Download as PDF, PPTX





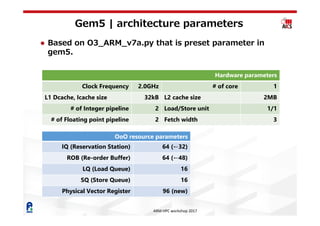
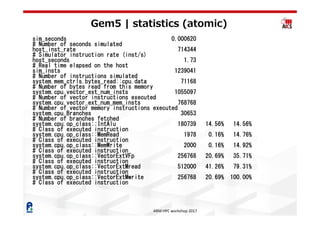



The document discusses the gem5 simulator presented at the ARM HPC Workshop 2017, highlighting its multi-ISA support and various CPU models including atomic and out-of-order simulations. It details the architecture parameters, performance statistics, and the limitations of simulating whole applications due to time constraints. Additionally, it raises concerns about parameter disclosure for fair performance comparisons in HPC contexts.














































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








