Downloaded 14 times








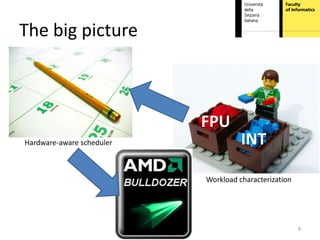



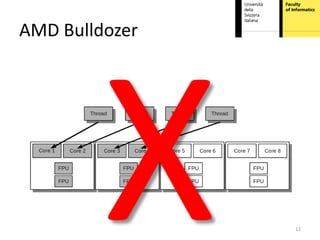
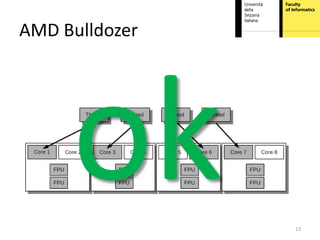








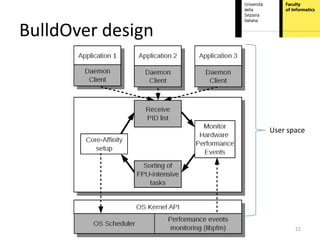



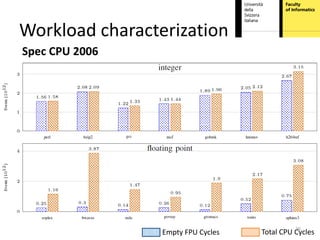
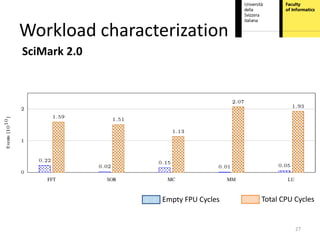
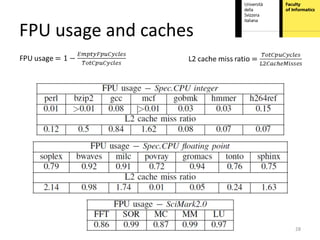


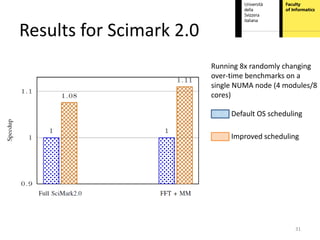






This document proposes hardware-aware thread scheduling on asymmetric multicore processors like the AMD Bulldozer. It presents a workload characterization technique using hardware performance counters to identify threads that are floating-point intensive. An optimized scheduler then performs scheduling decisions based on hardware resource usage and workload characterization to improve occupancy of processing units on Bulldozer chips. Evaluation on SPEC CPU2006 and SciMark2.0 benchmarks shows the approach improves performance over default OS scheduling by better distributing integer and floating-point workloads across the cores.









































































