Download as PDF, PPTX














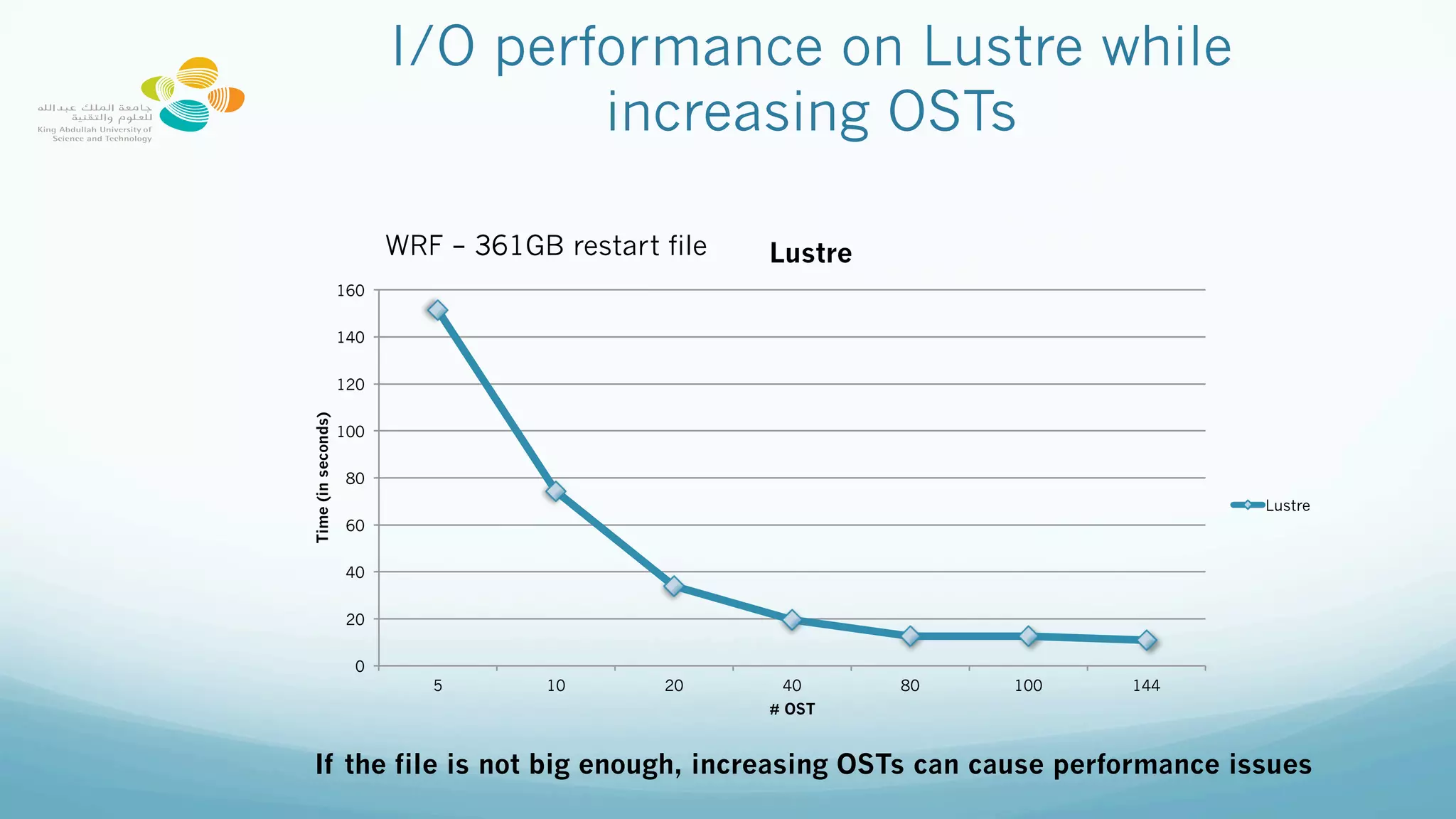





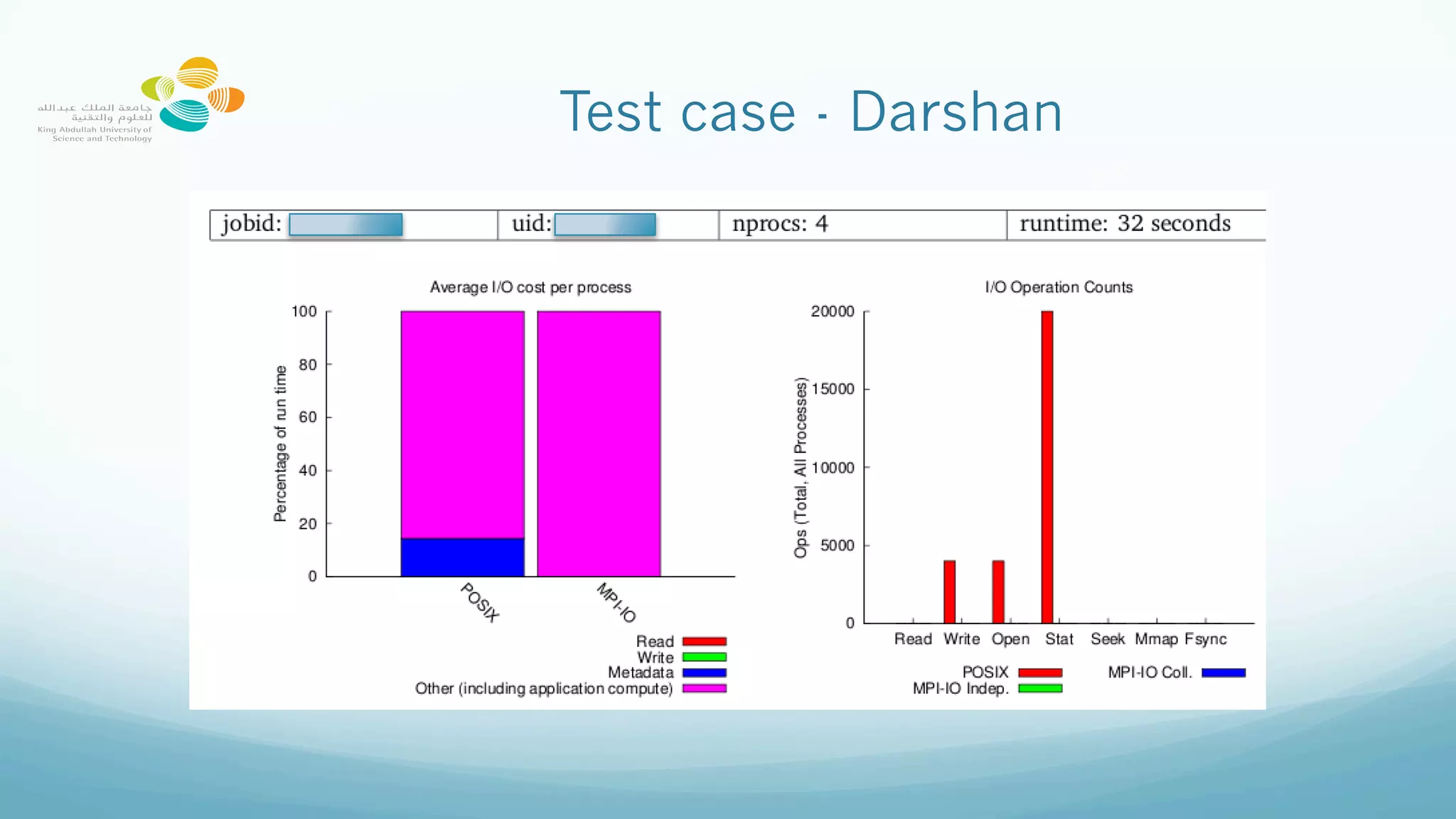
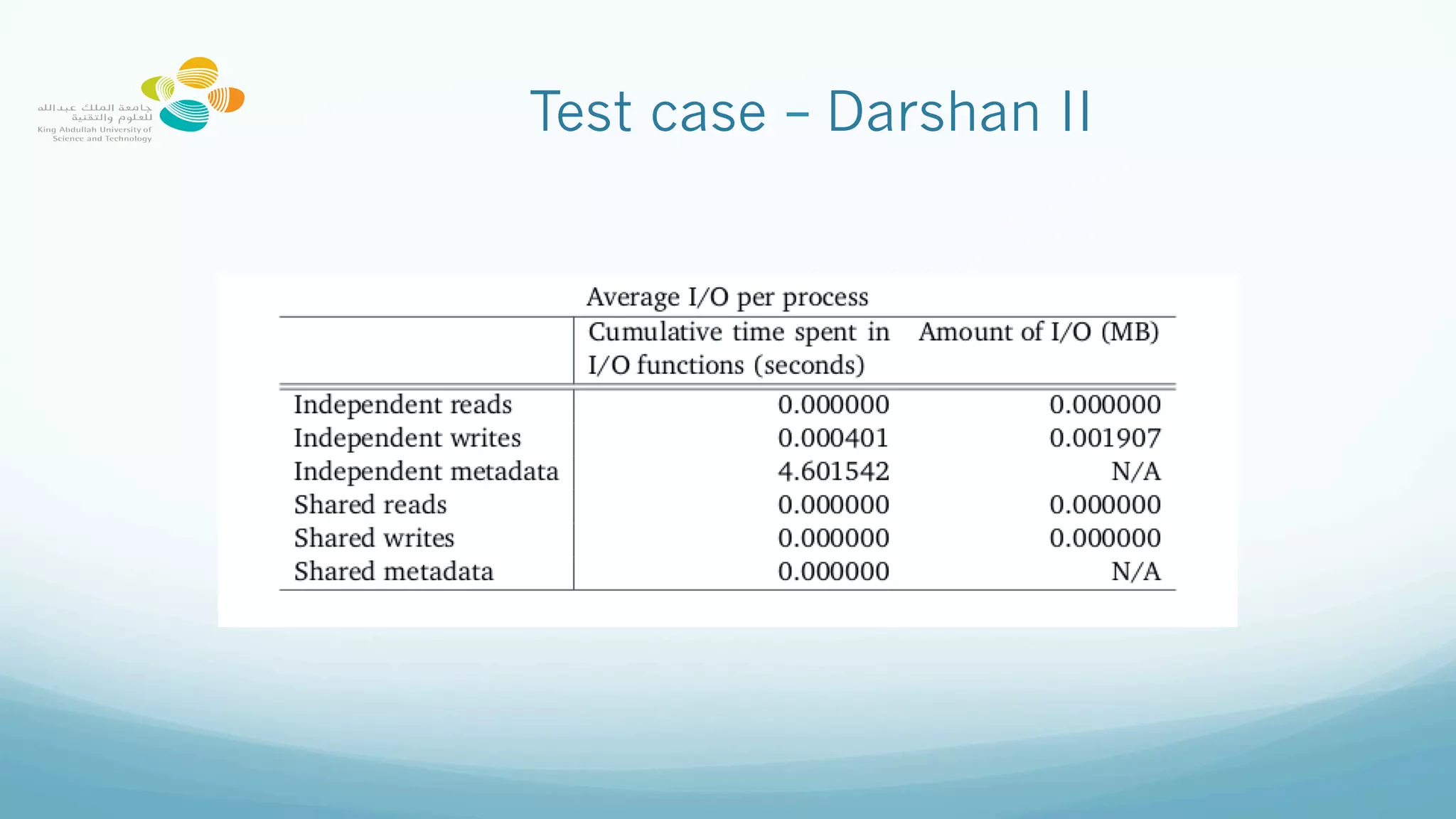

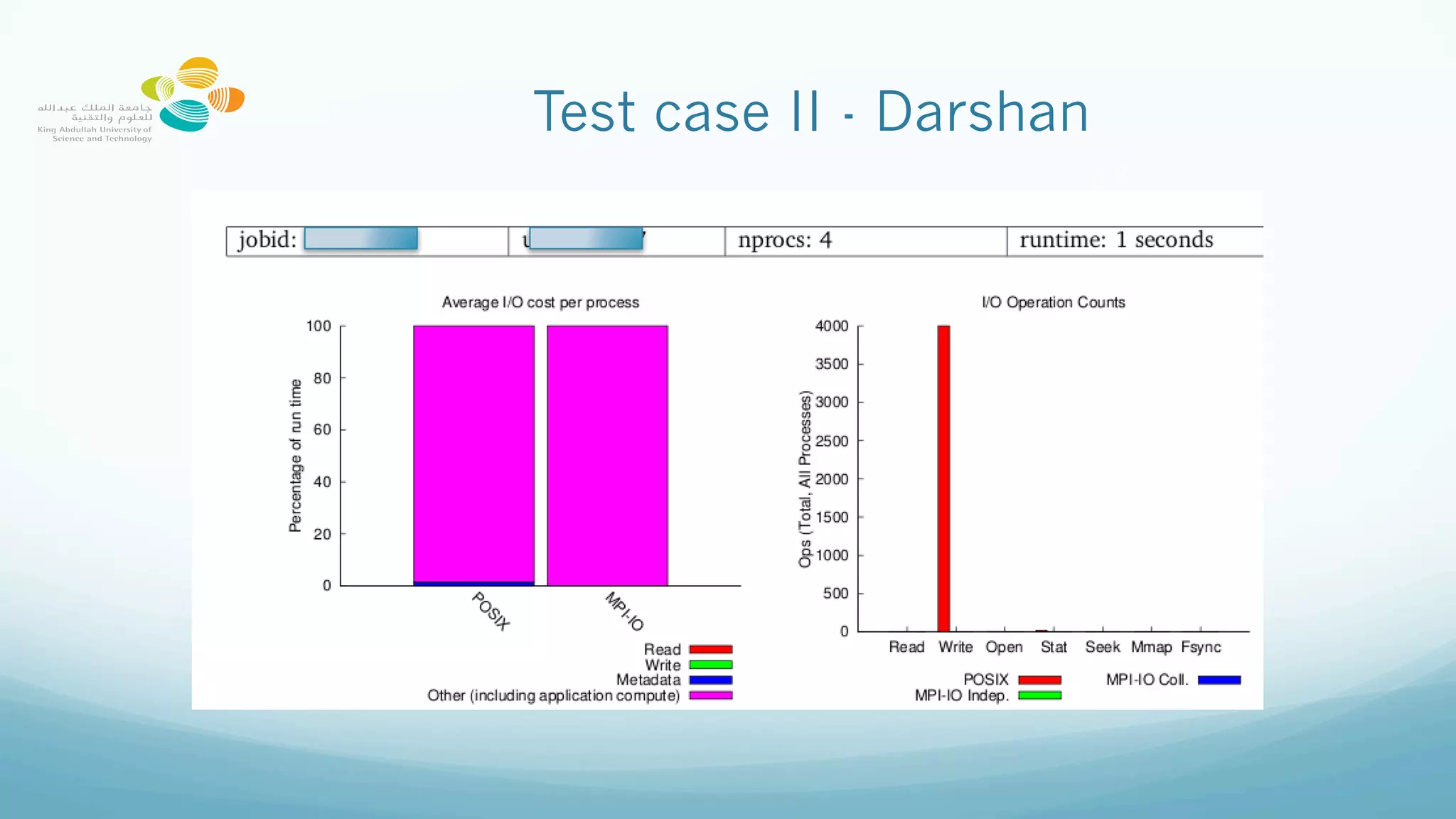




This document provides best practices for optimizing I/O performance on the Lustre parallel filesystem, emphasizing file organization, striping techniques, and appropriate use of MPI processes. Key recommendations include avoiding excessive small file access, leveraging collective buffering for parallel I/O, and strategic use of striping to enhance data throughput. The conclusions highlight the complexity of maximizing performance and the importance of experimentation to find optimal configurations.



















![[OpenInfra Days Korea 2018] (Track 3) - CephFS with OpenStack Manila based on...](https://cdn.slidesharecdn.com/ss_thumbnails/36openinfra-2018-naver-cephfs-180704055415-thumbnail.jpg?width=640&height=640&fit=bounds)














































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

