Downloaded 21 times





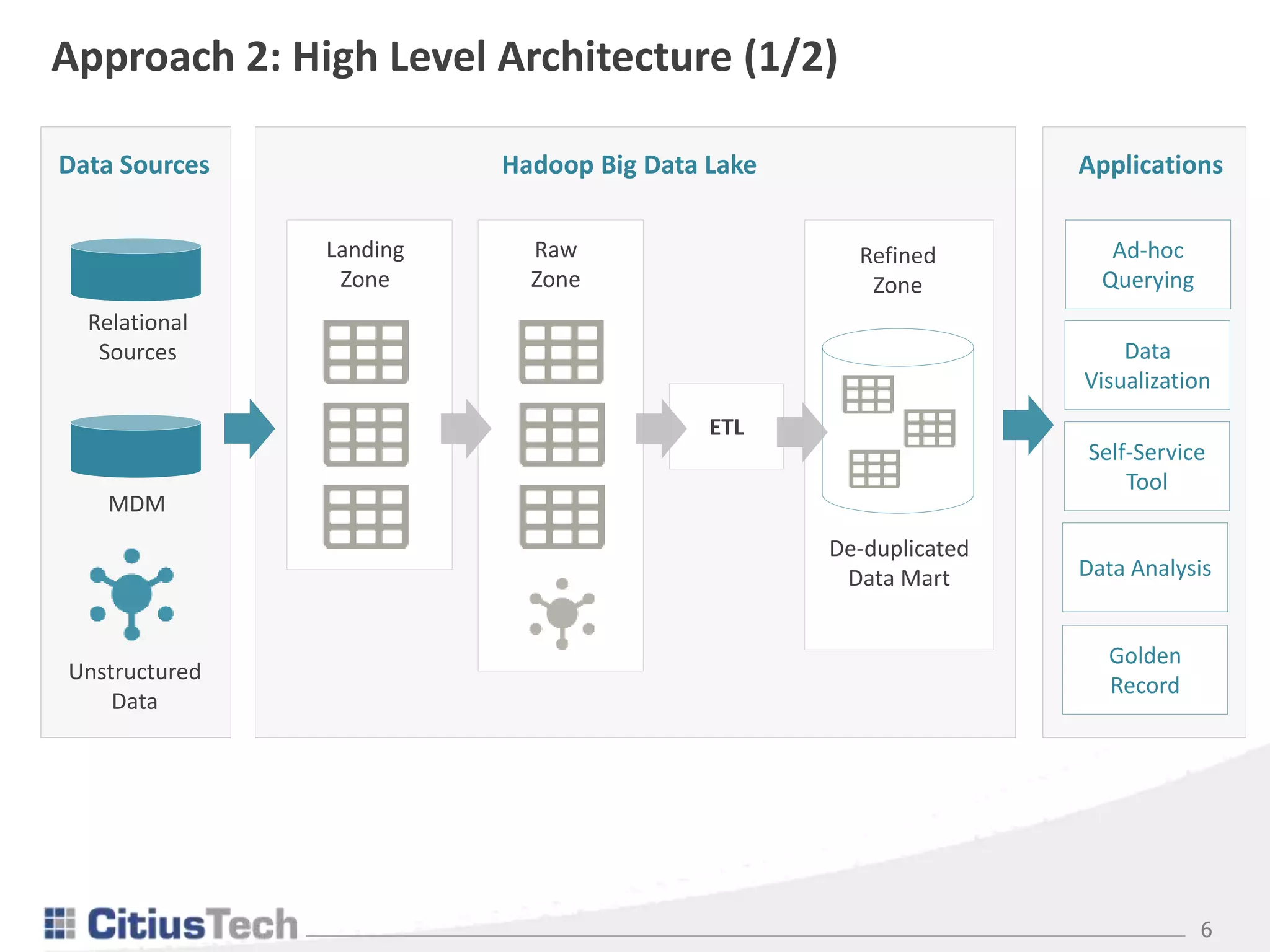






This document discusses de-duplicating data in a healthcare data lake using big data processing frameworks. It describes keeping duplicate records and querying the latest one, or rewriting records to create a golden copy. The preferred approach uses Spark to partition data, identify new/updated records, de-duplicate by selecting the latest from incremental and refined data, and overwrite only affected partitions. This creates a non-ambiguous, de-duplicated dataset for analysis in a scalable and cost-effective manner.








































































![Understanding Parkinson’s Disease: Causes, Symptoms, and Treatment [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/understandingparkinson-251208102525-80ba3223-thumbnail.jpg?width=640&height=640&fit=bounds)













