Downloaded 47 times













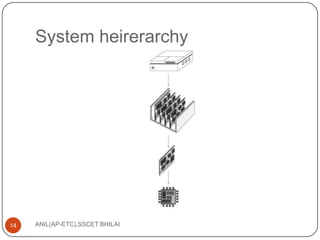
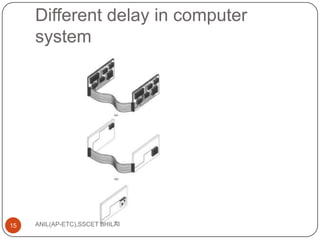




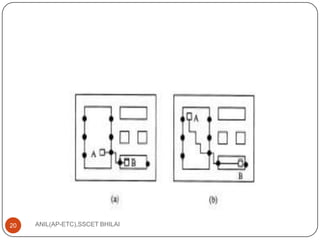





This document discusses algorithms for VLSI physical design automation. It describes the process of partitioning, which involves decomposing a complex system into smaller subsystems that can be designed independently to speed up the design process. Partitioning plays a key role in designing computer systems and VLSI chips by breaking them down into smaller blocks. The document outlines different types of partitioning at the system, board and chip levels, and describes the objectives and constraints of partitioning at each level, such as minimizing area, number of boards/chips, and interconnects between partitions.






































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
















