Download as ZIP, PPTX


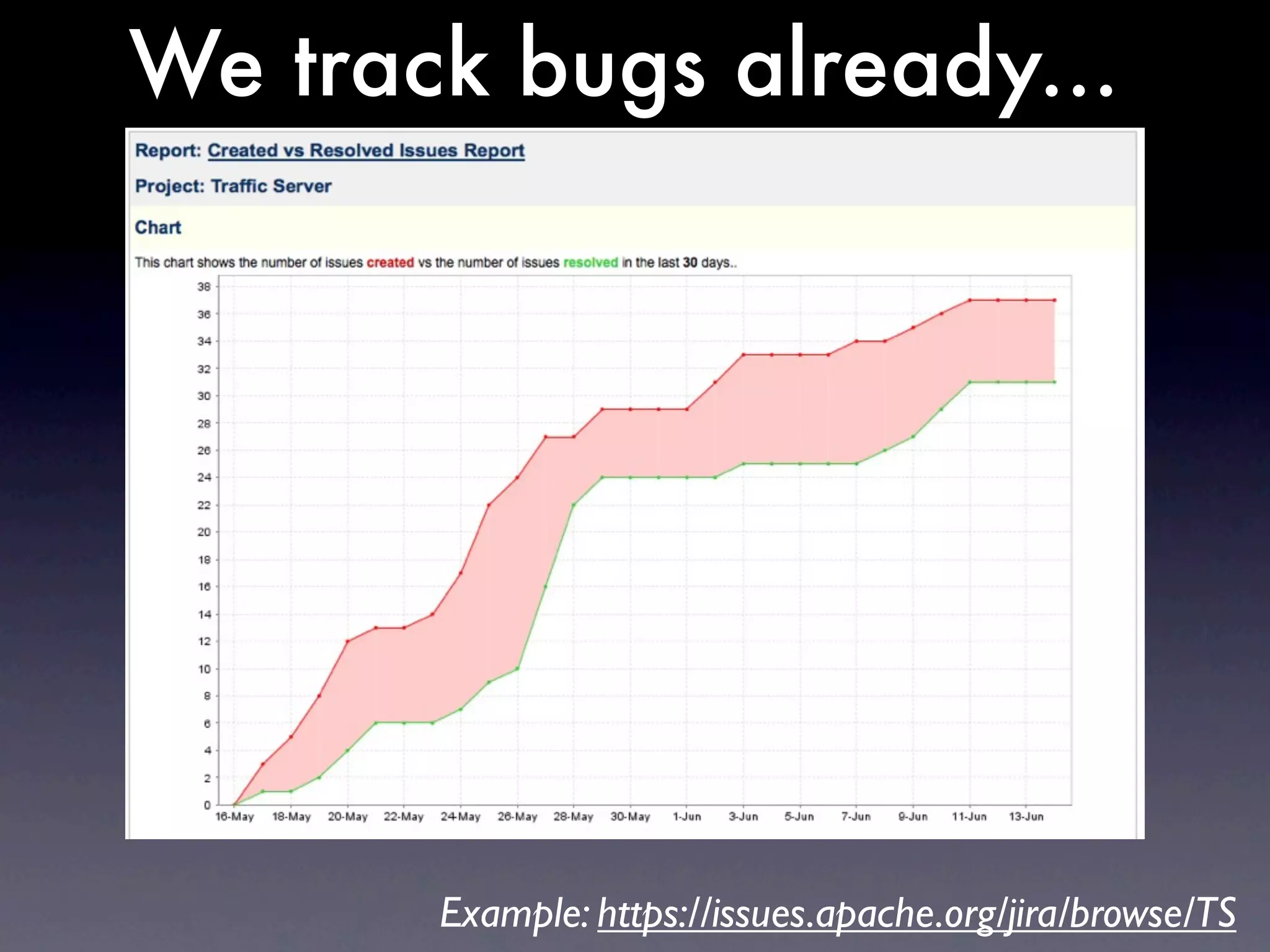





















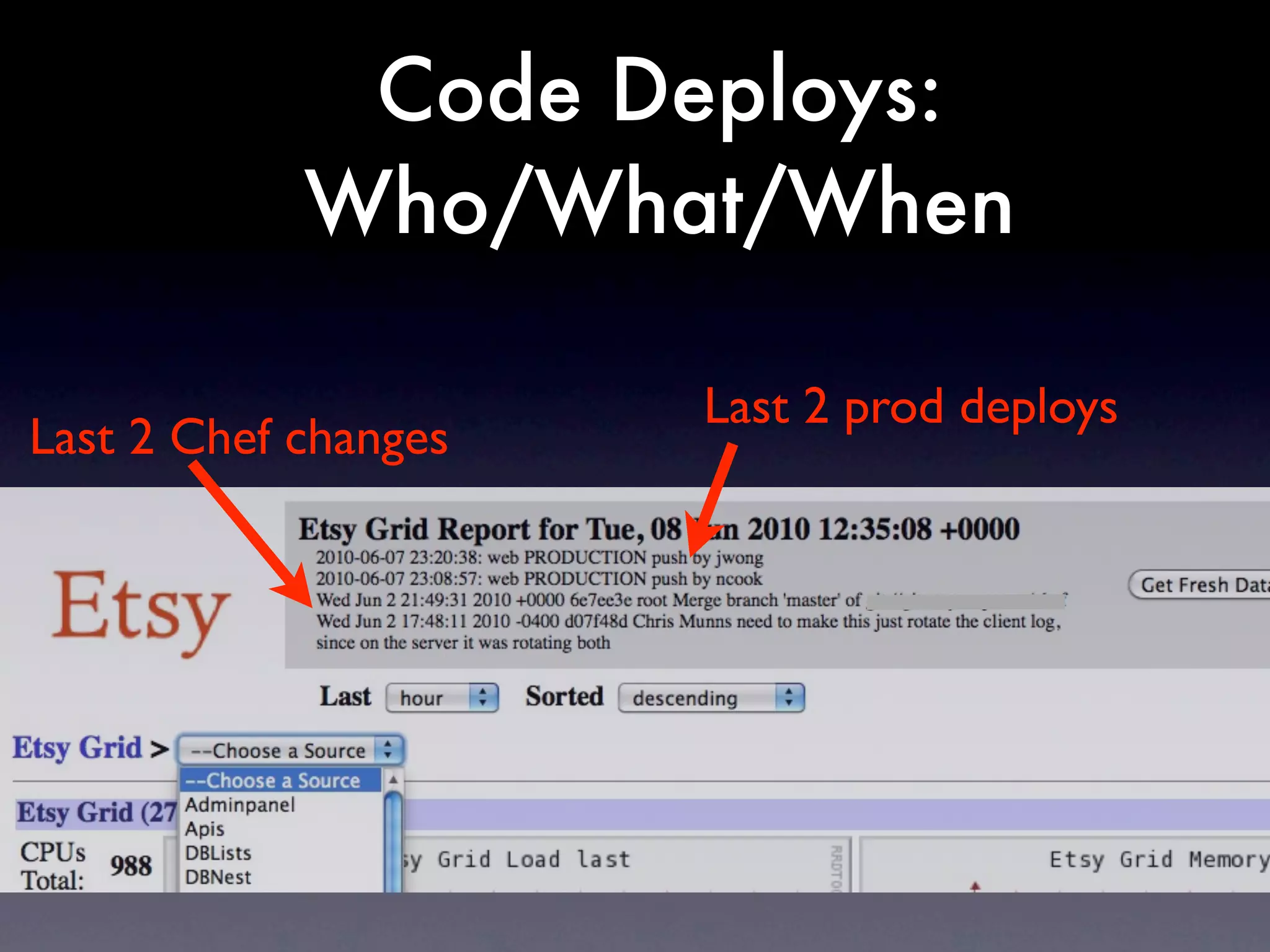
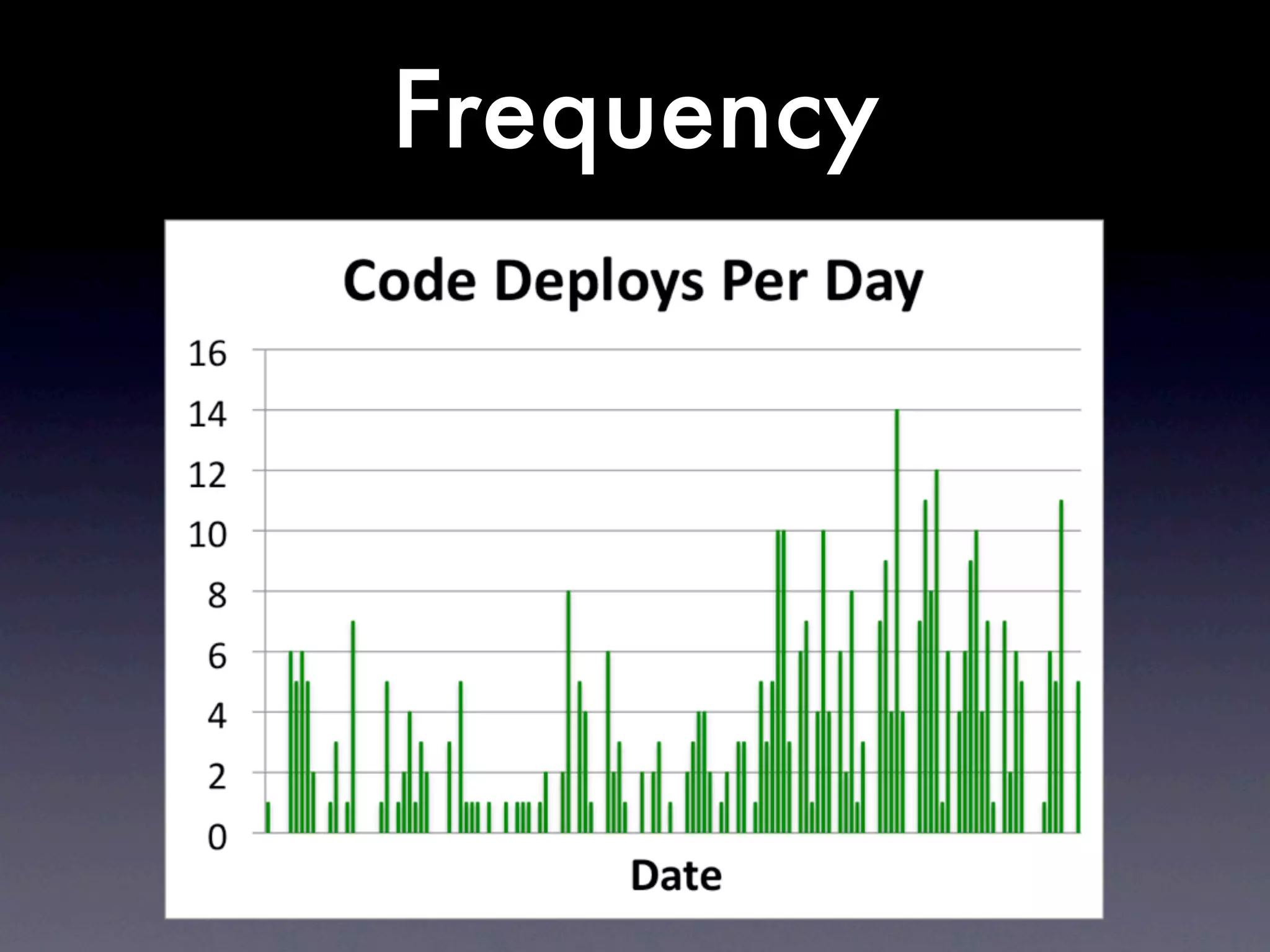
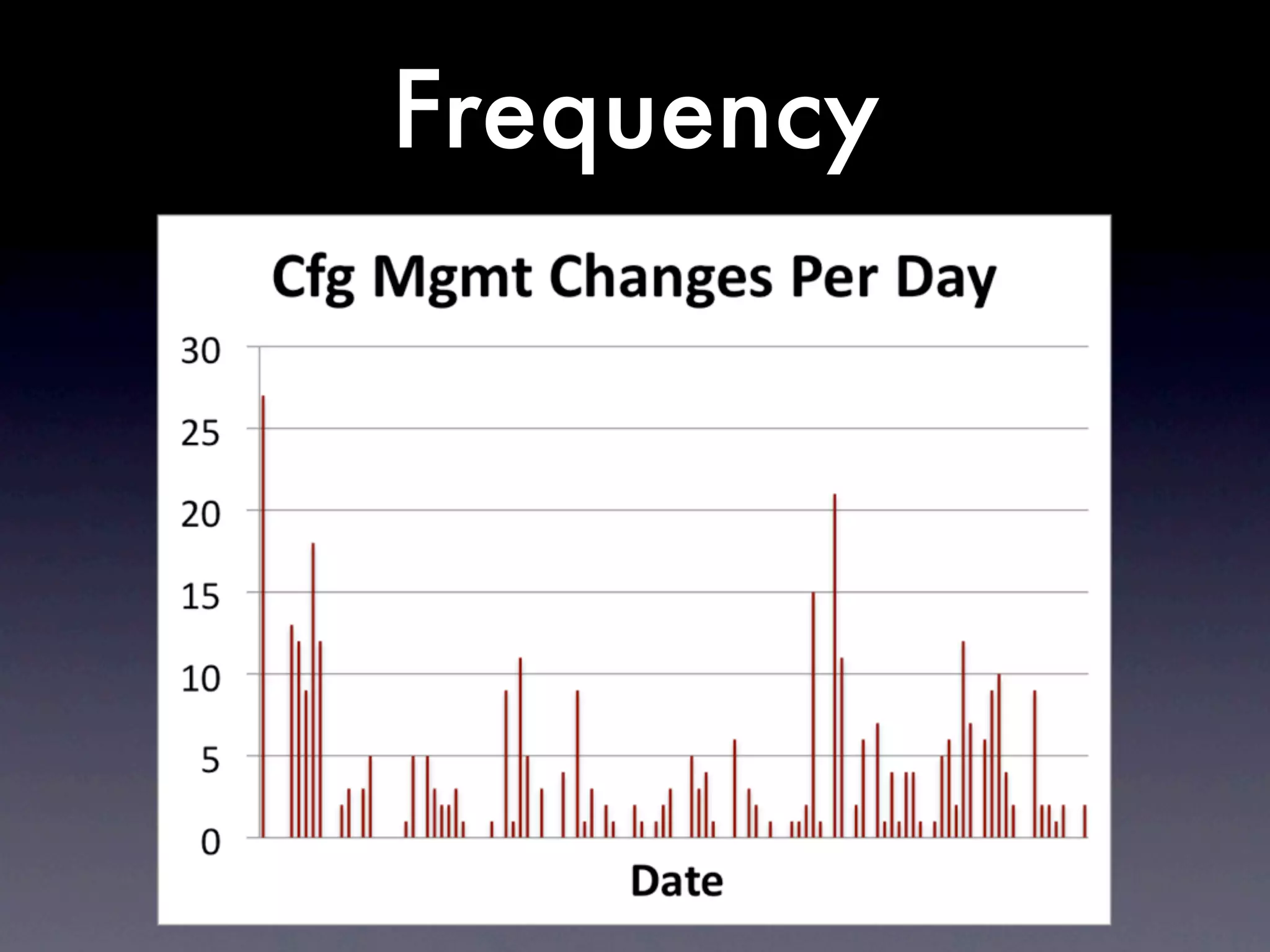
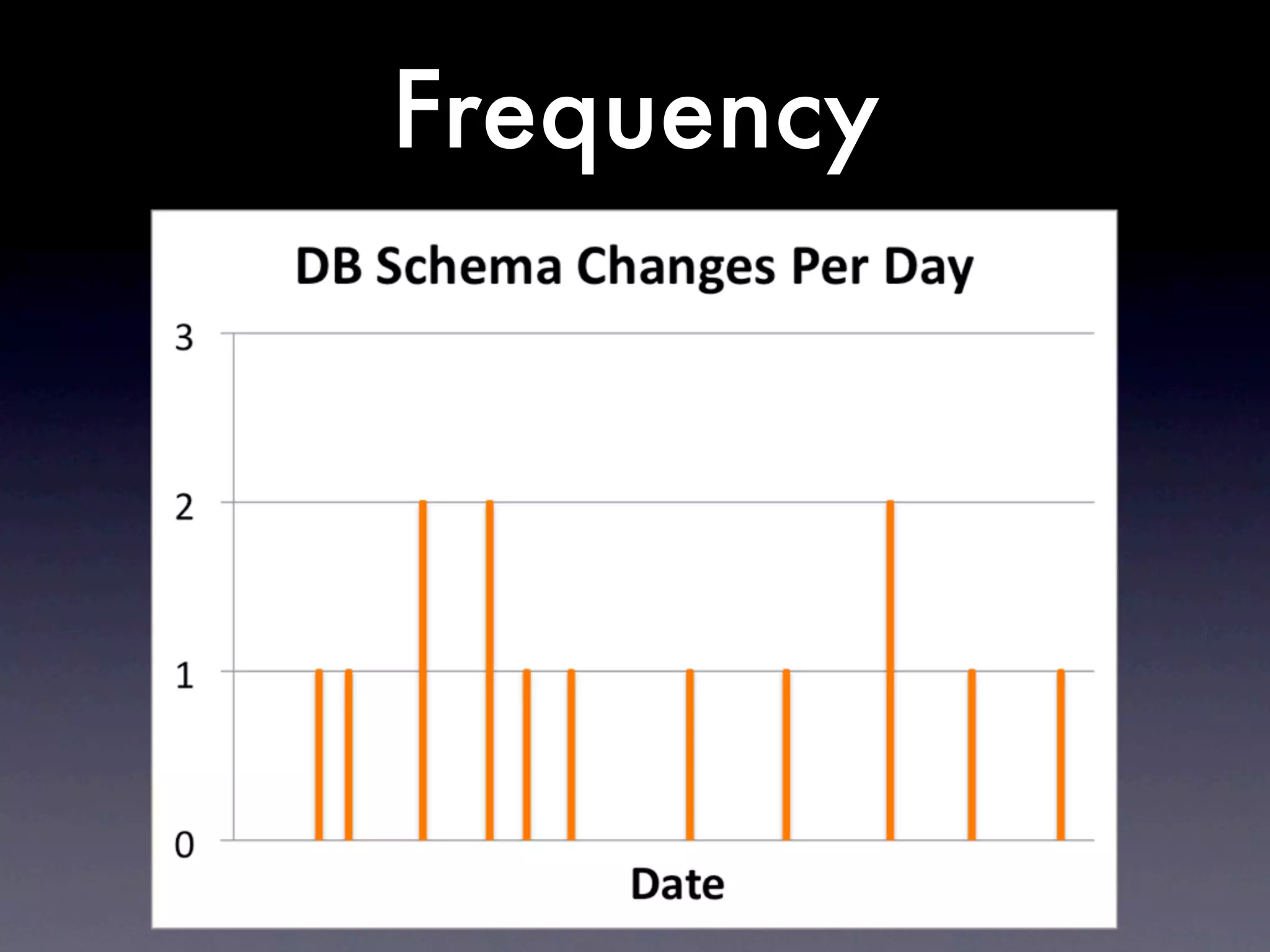
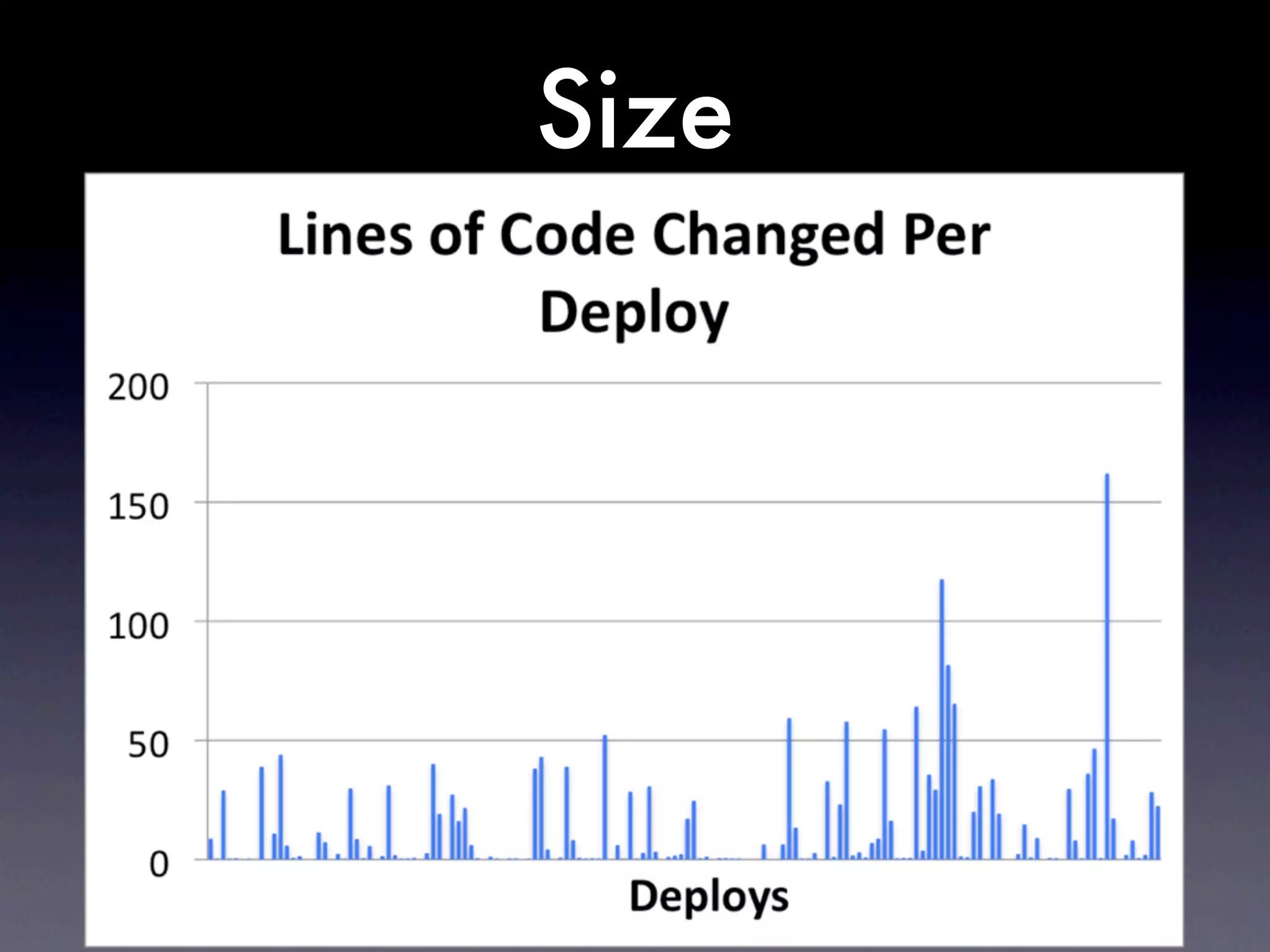

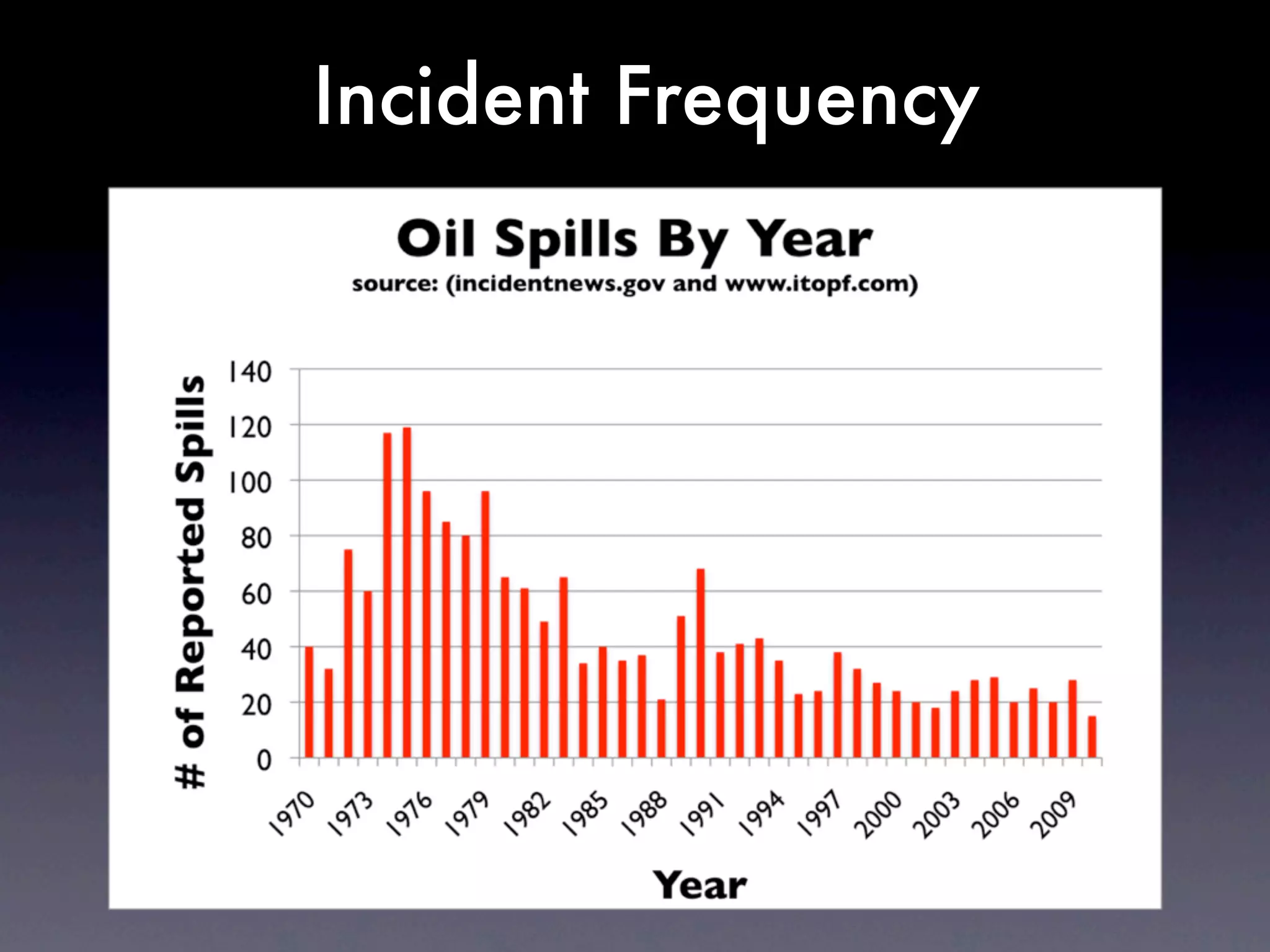
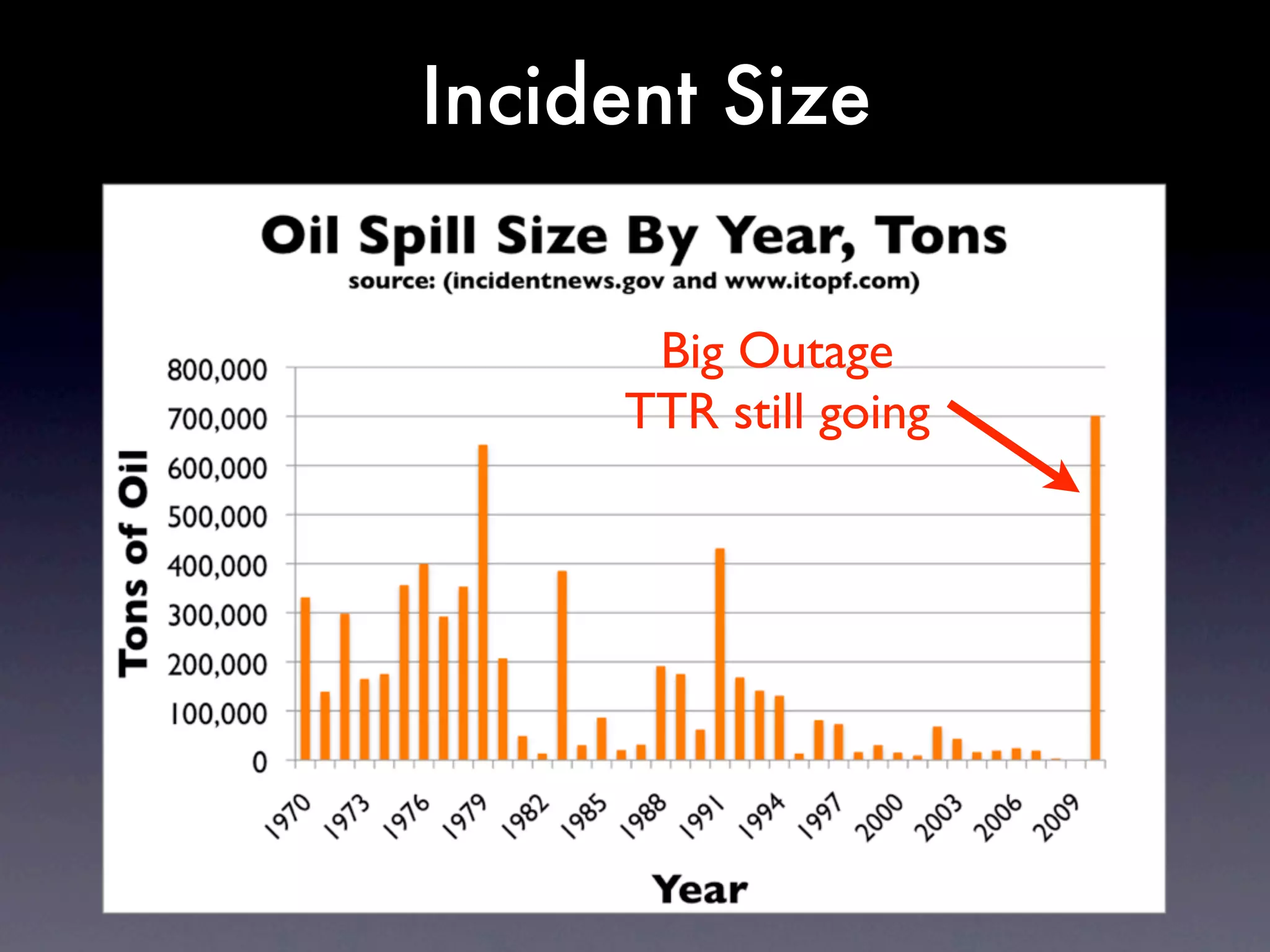


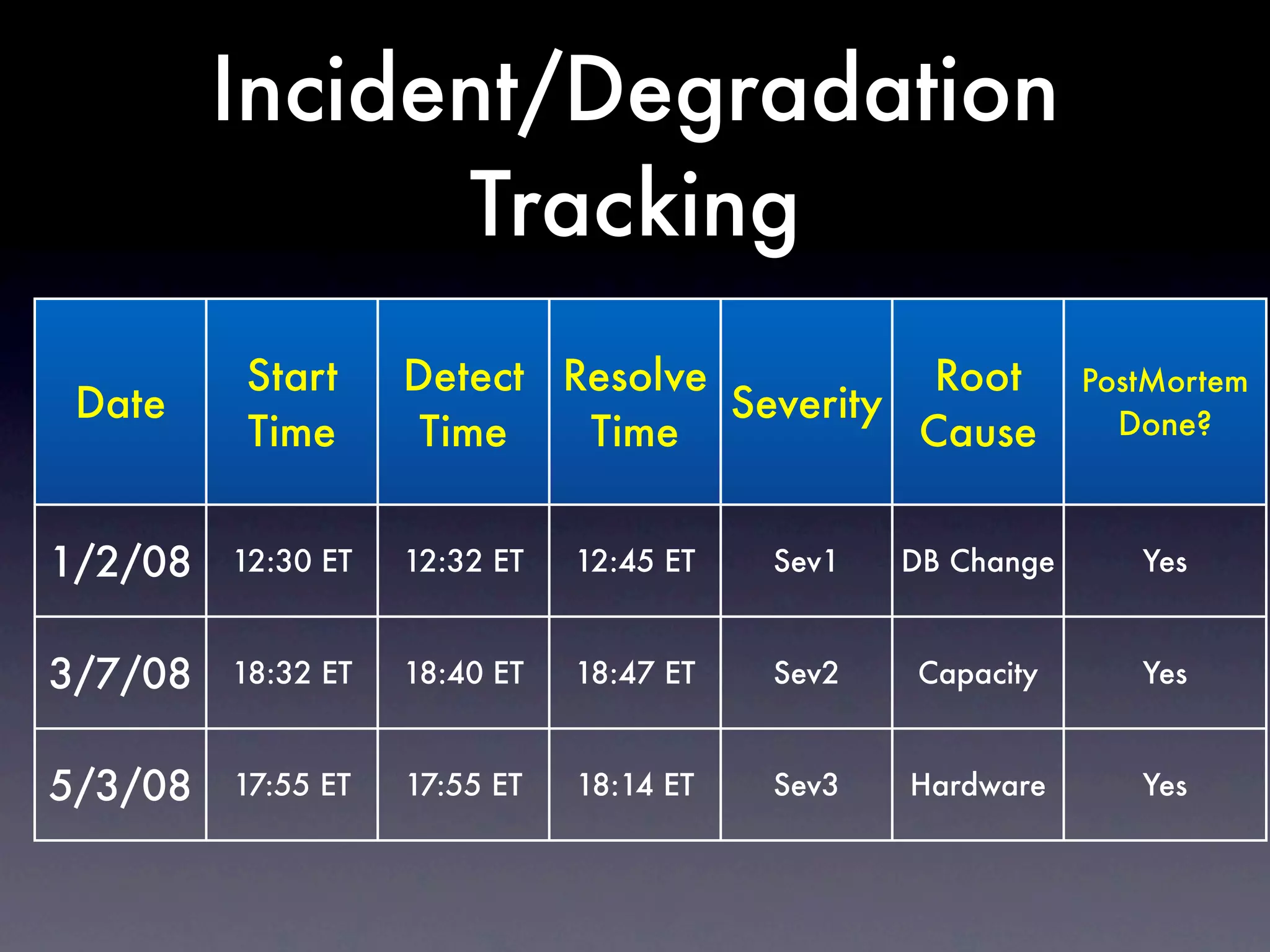




















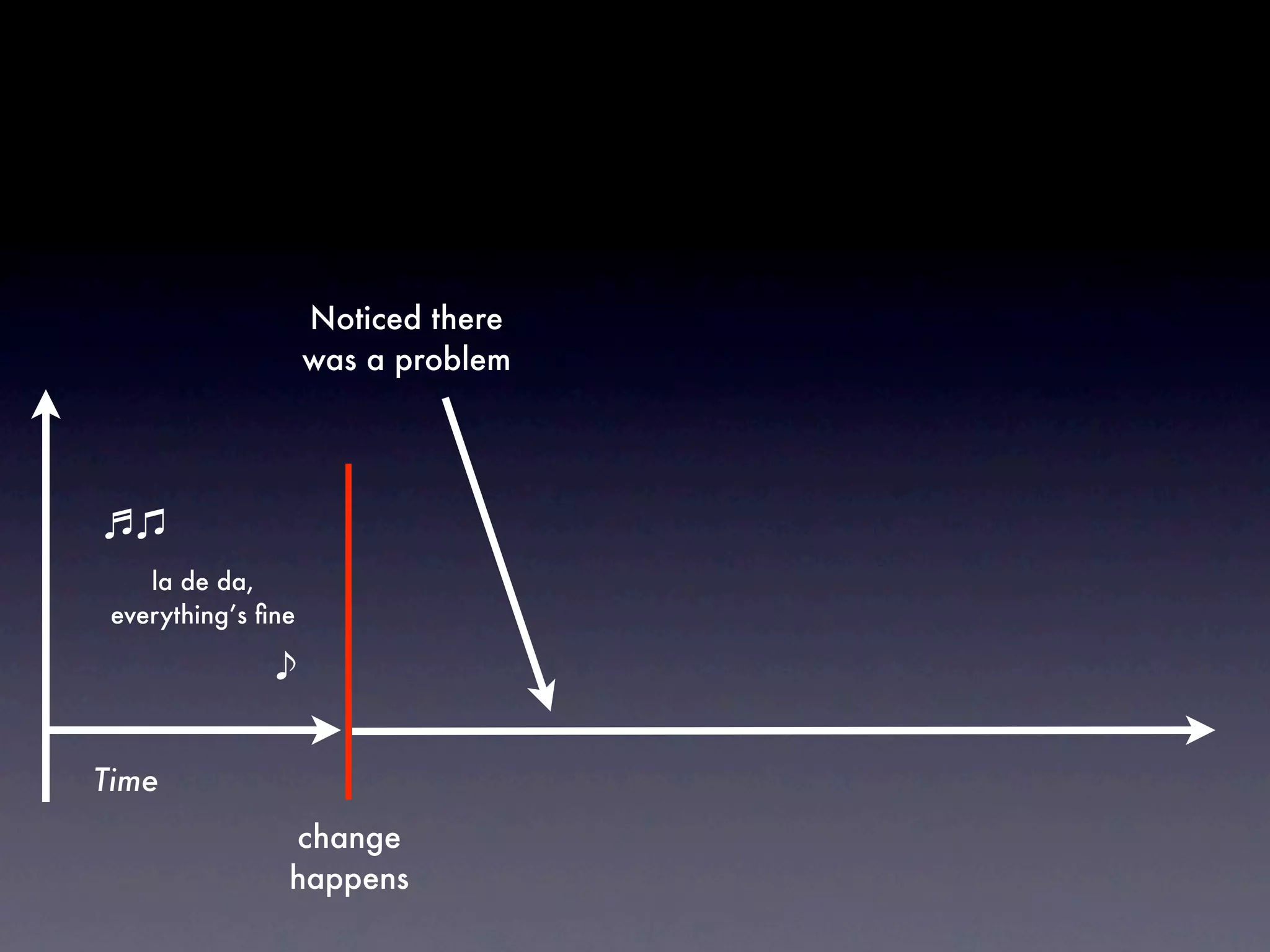
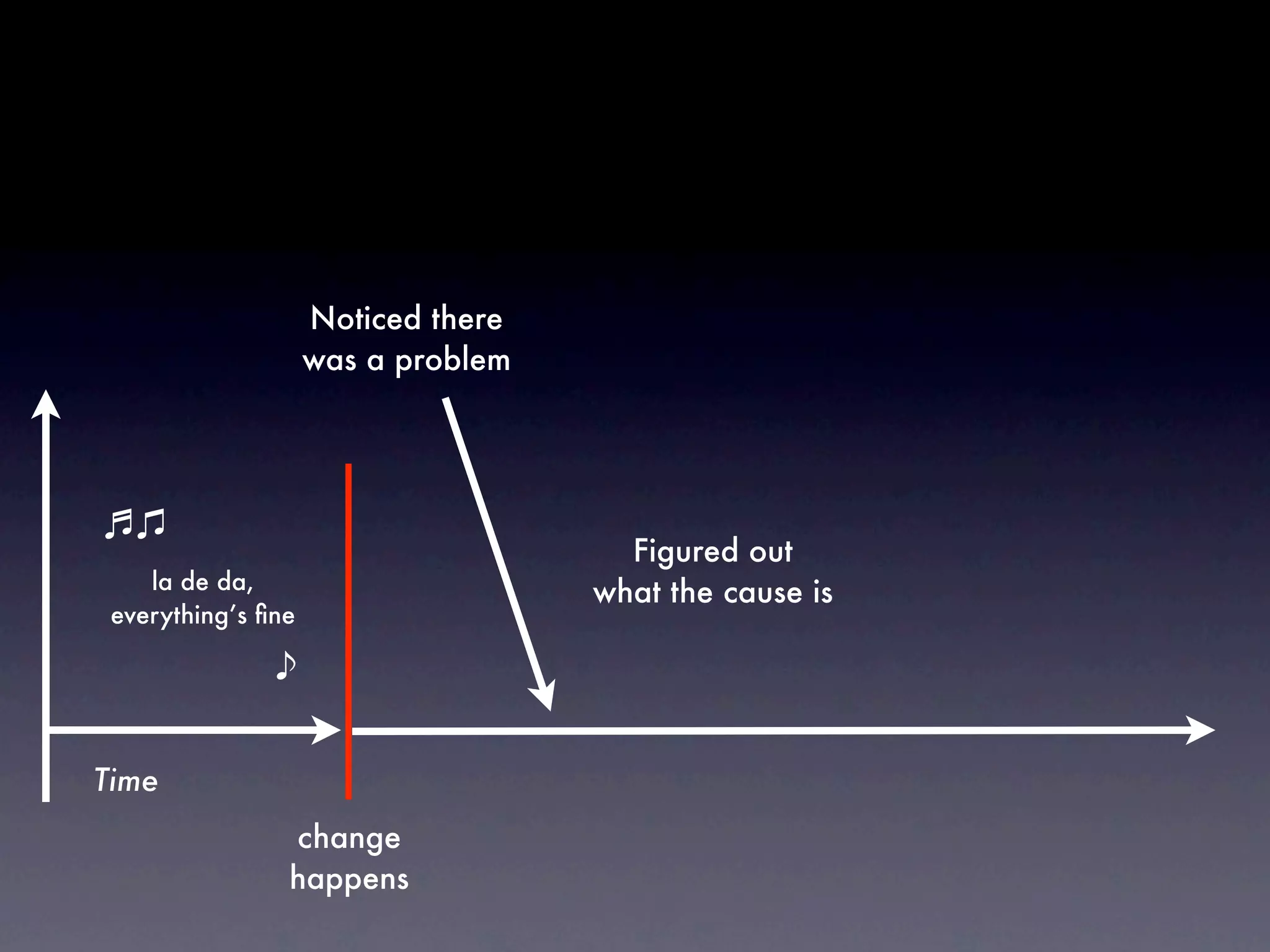
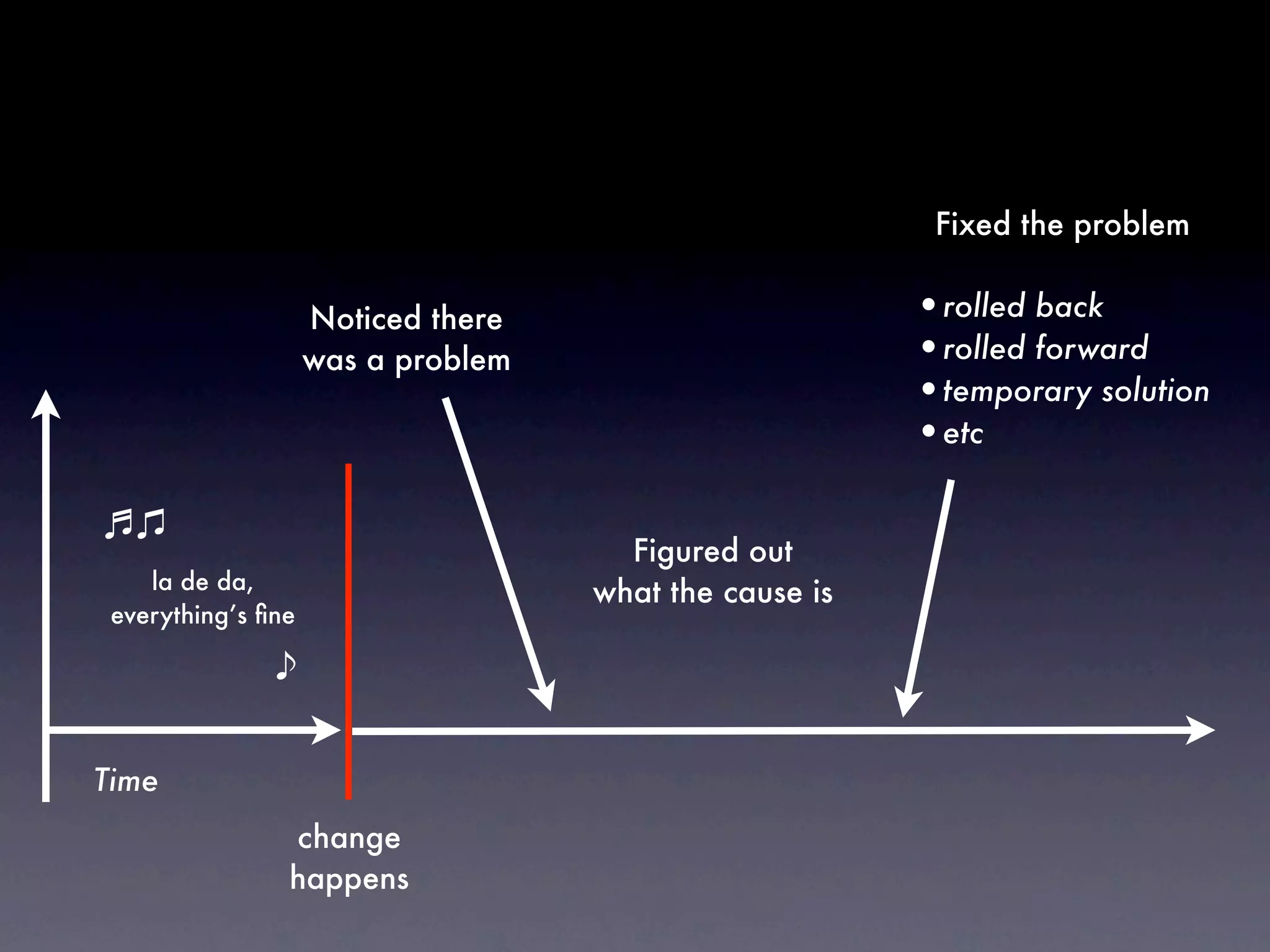
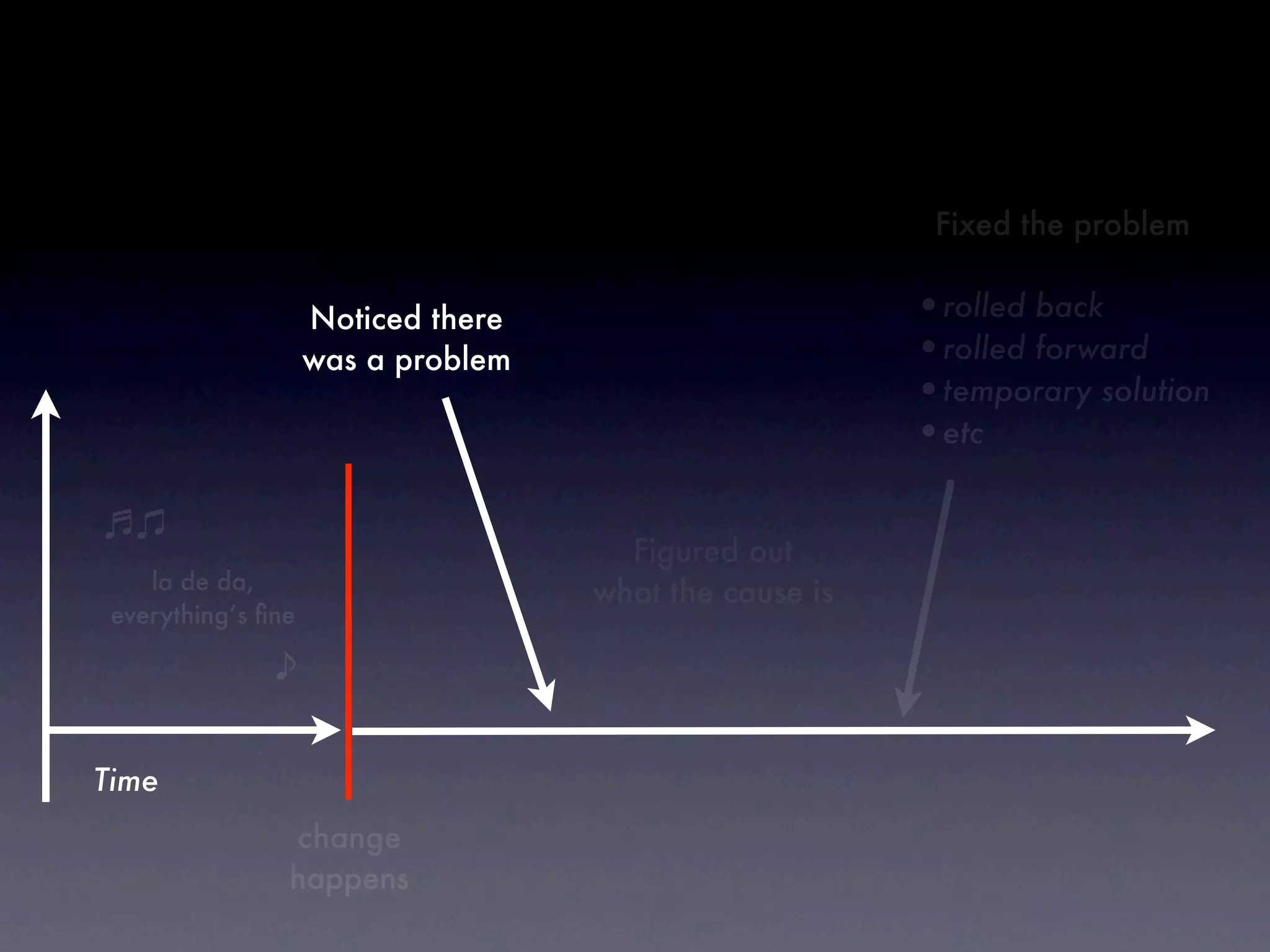
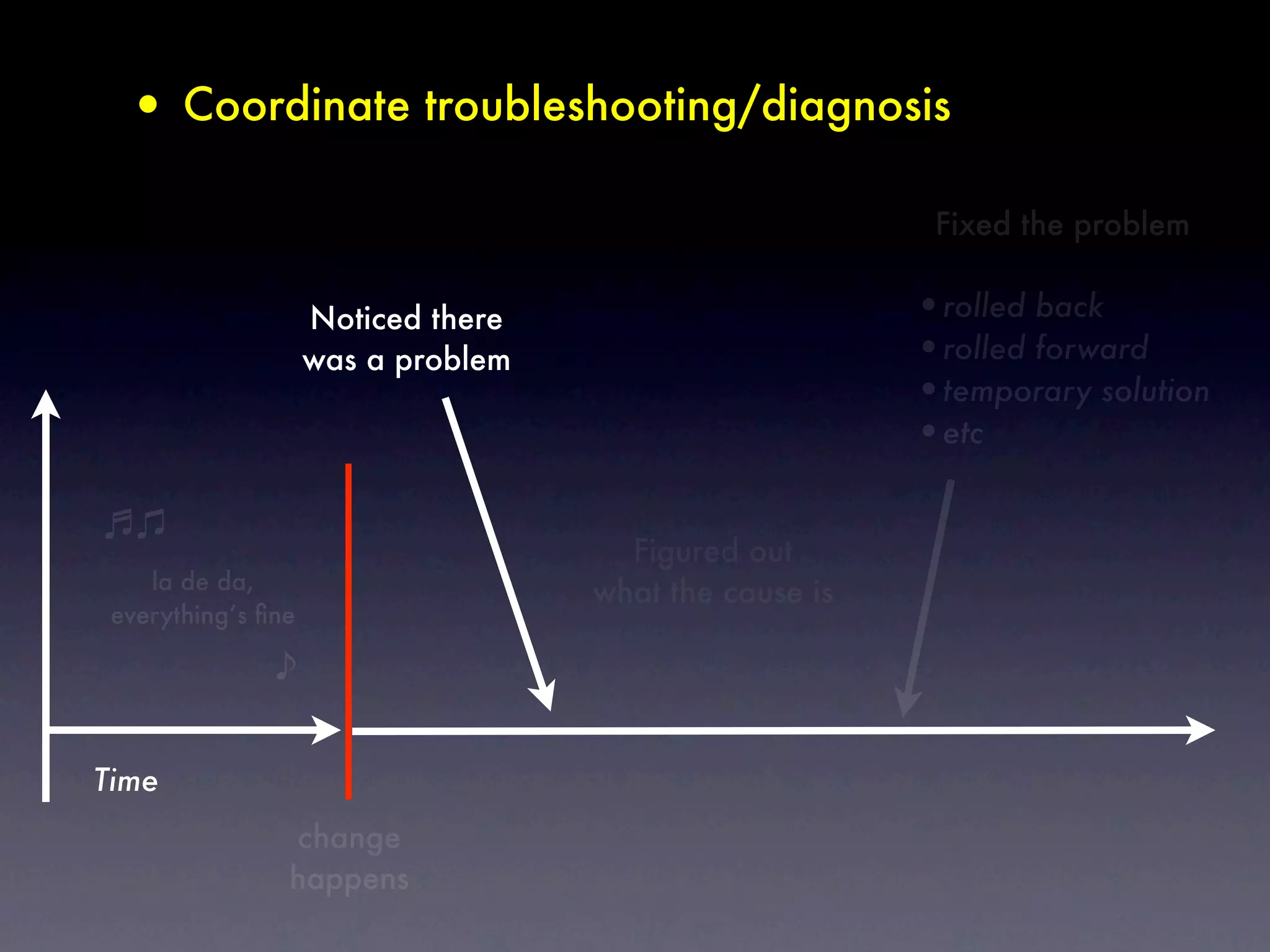

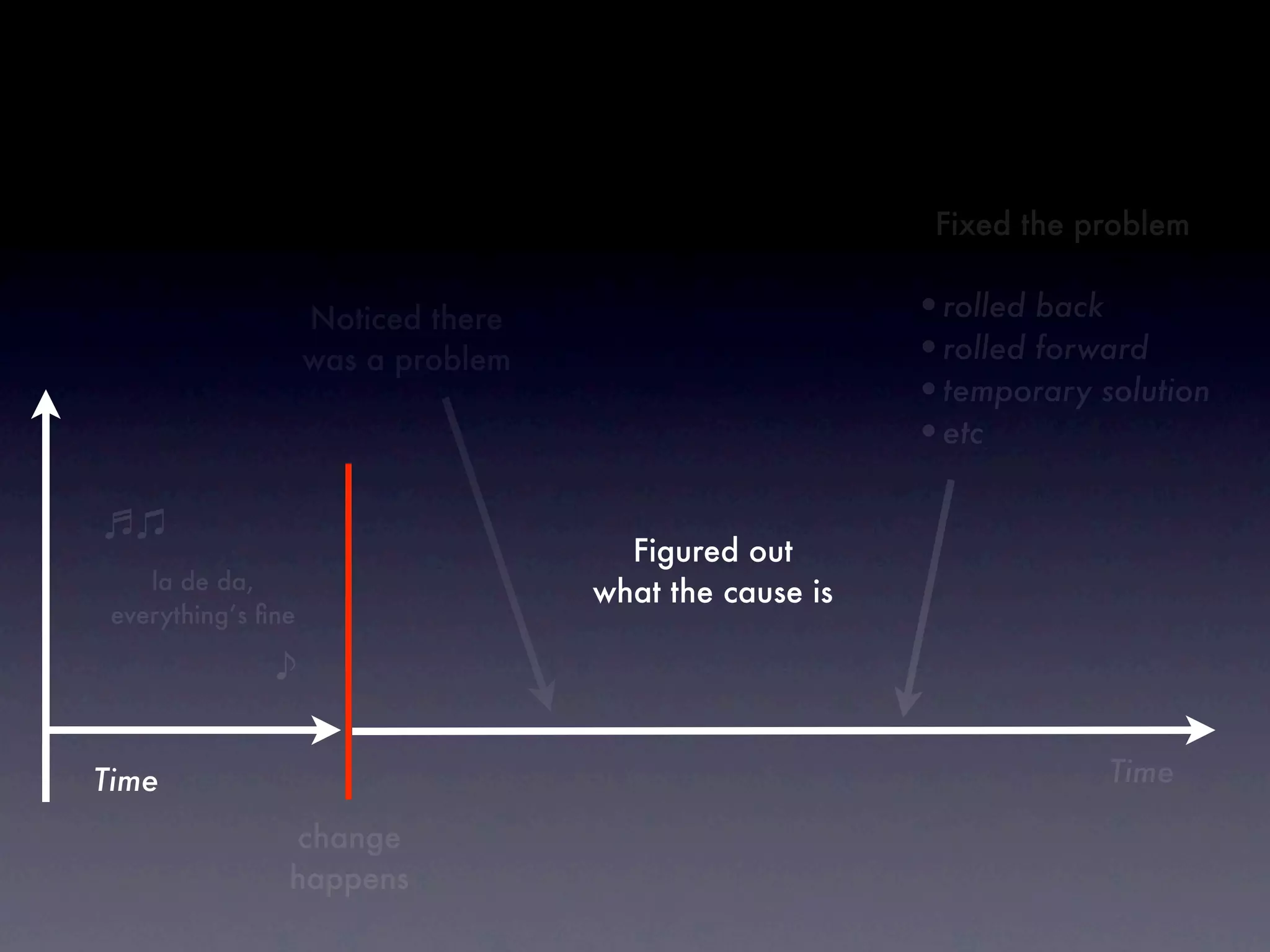
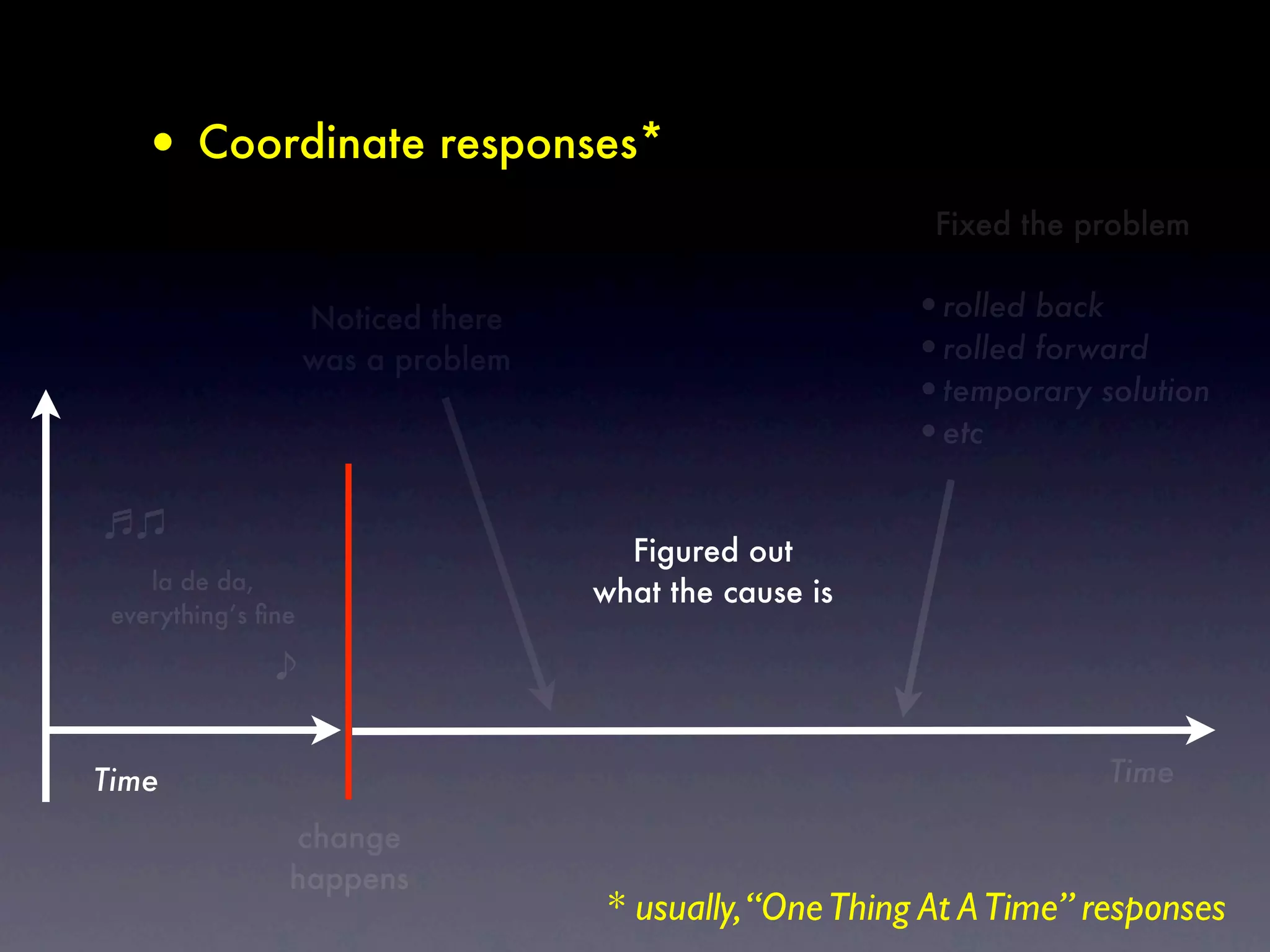
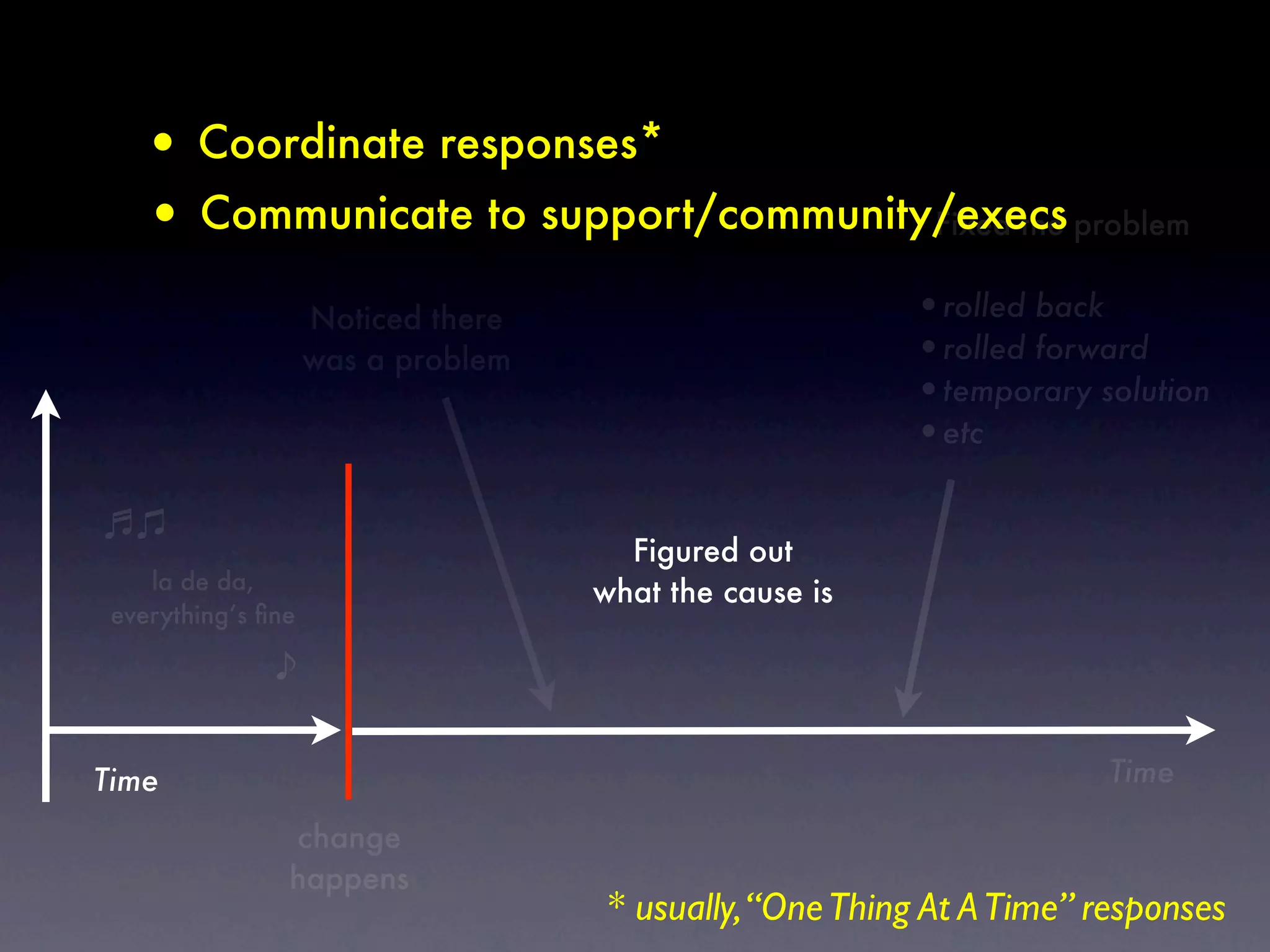
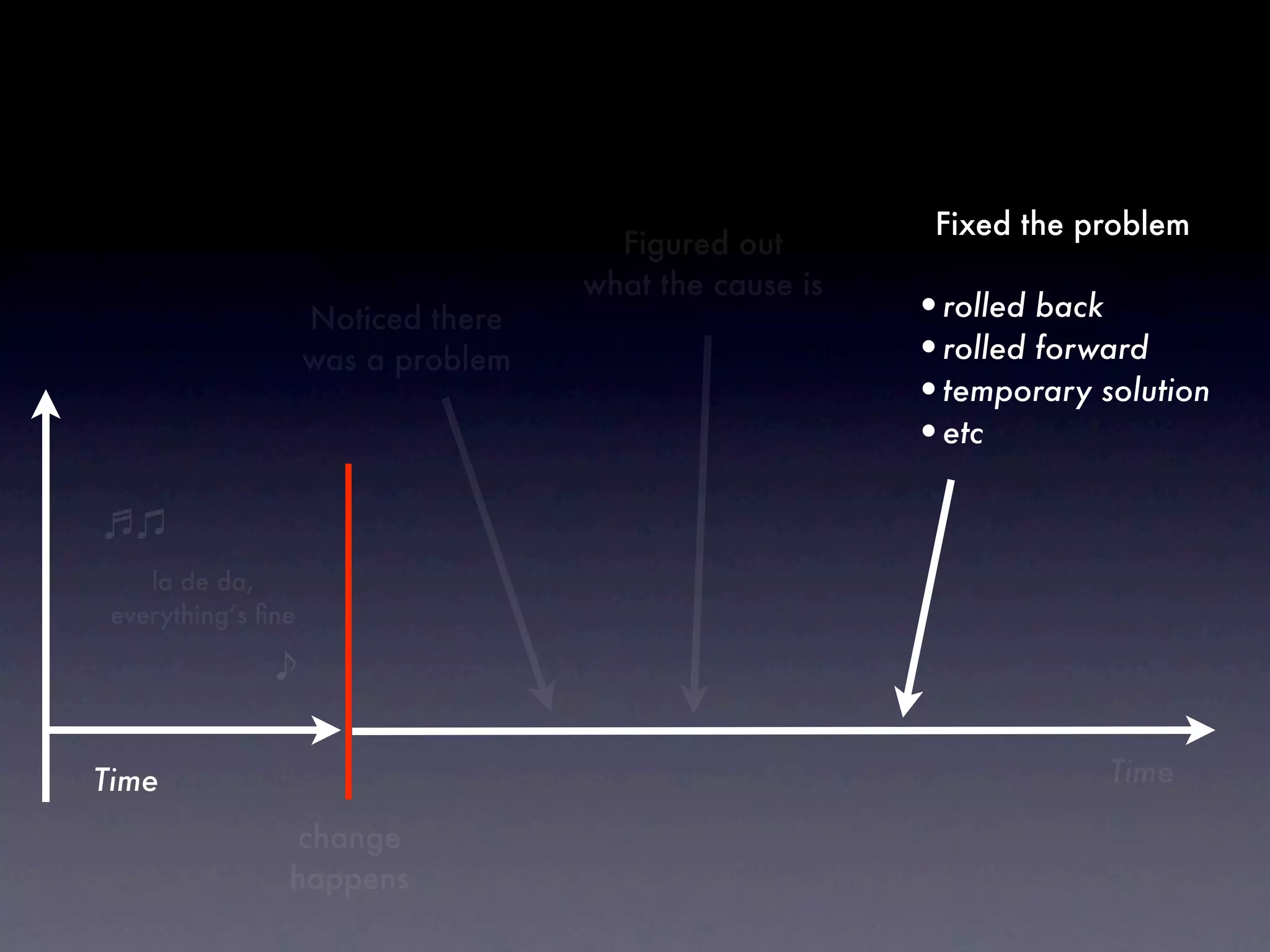
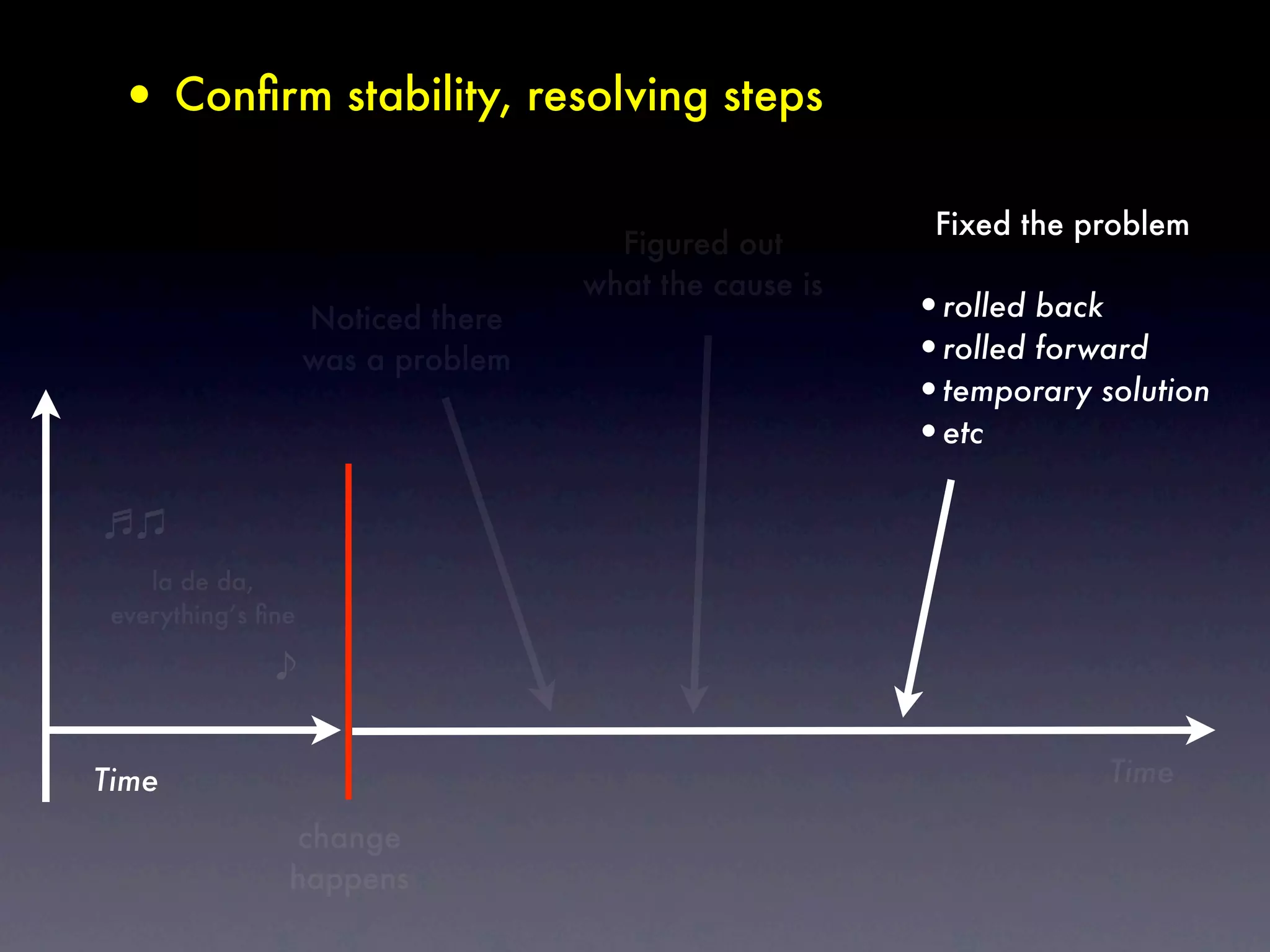


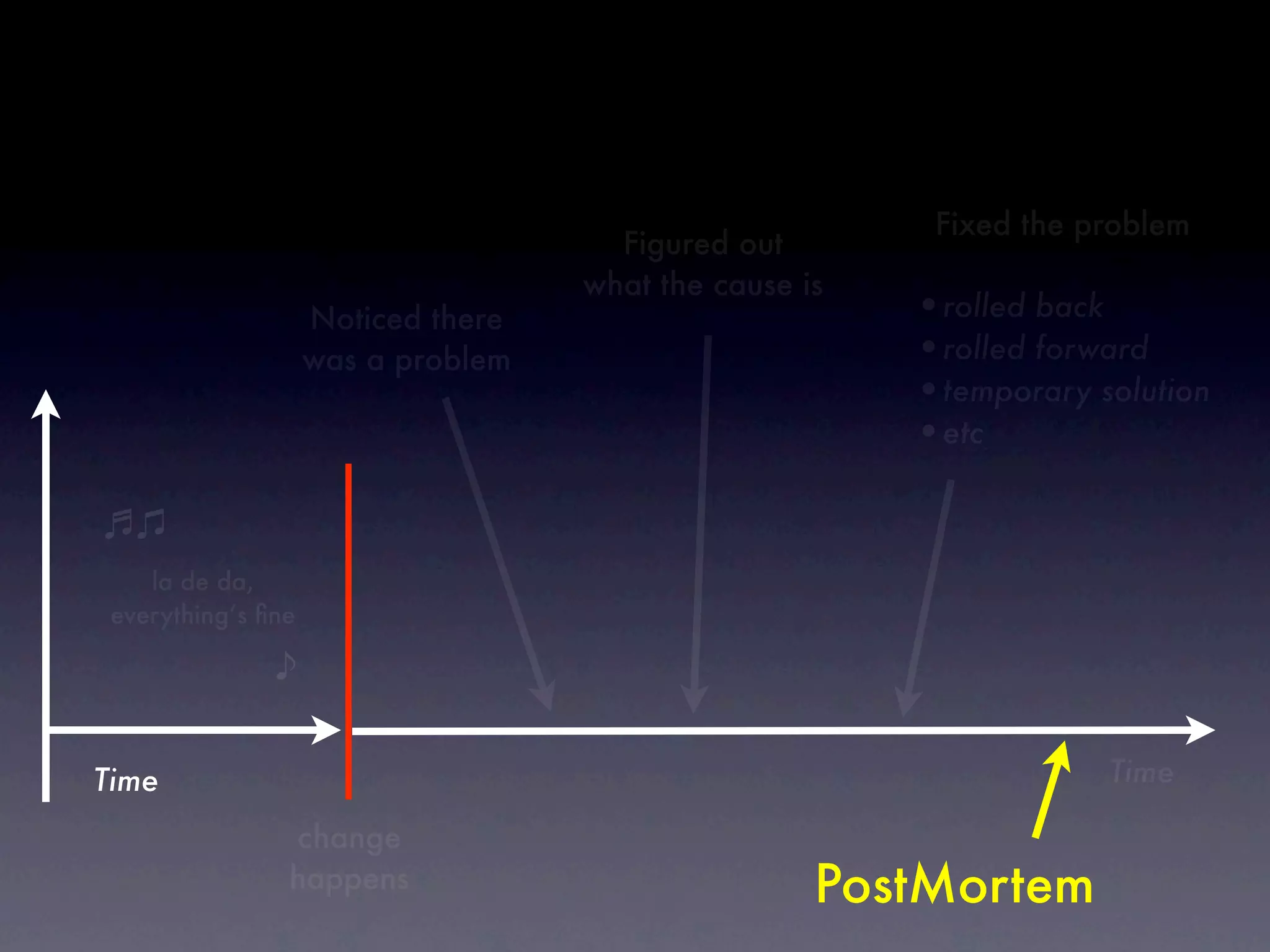
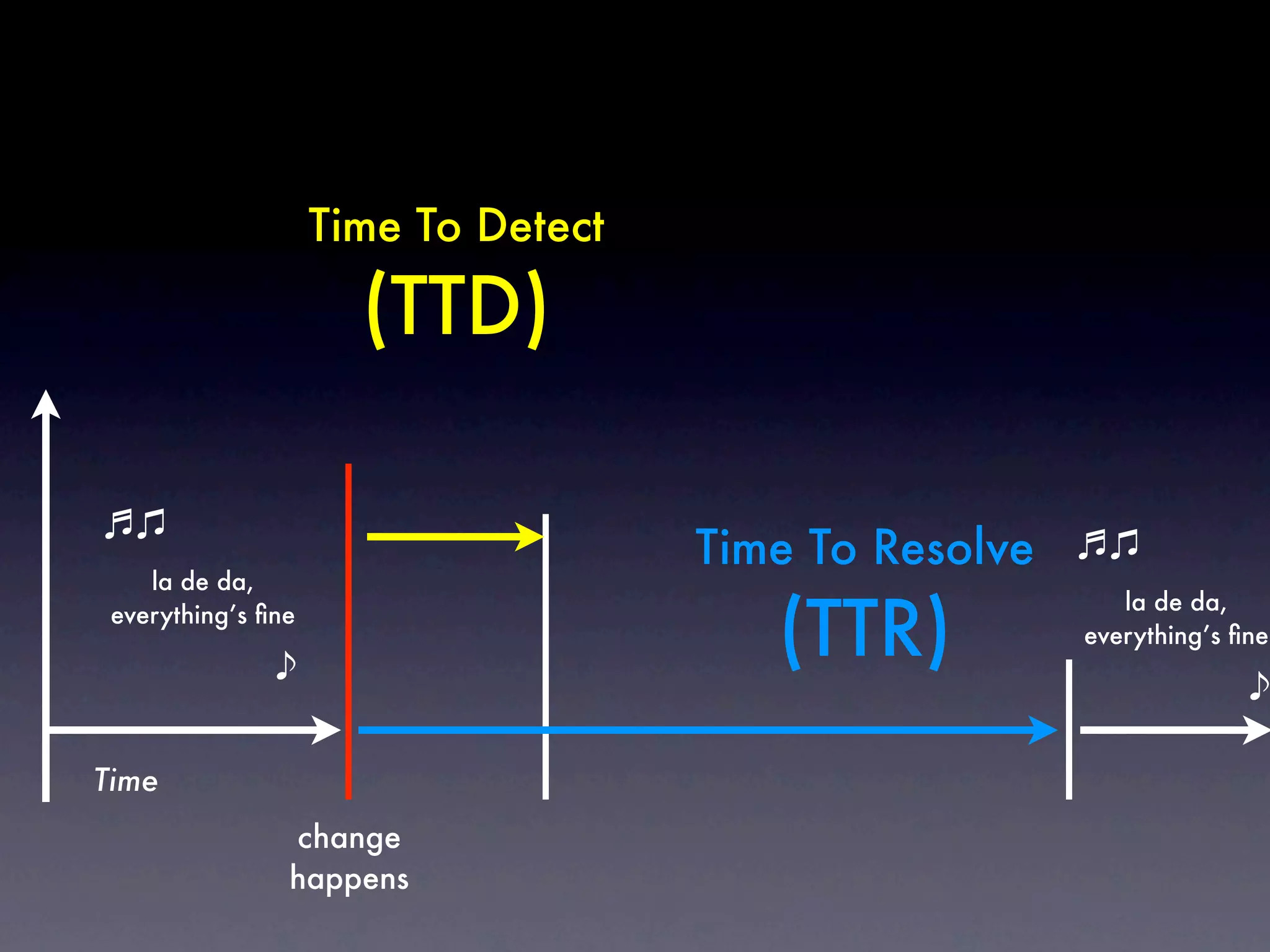
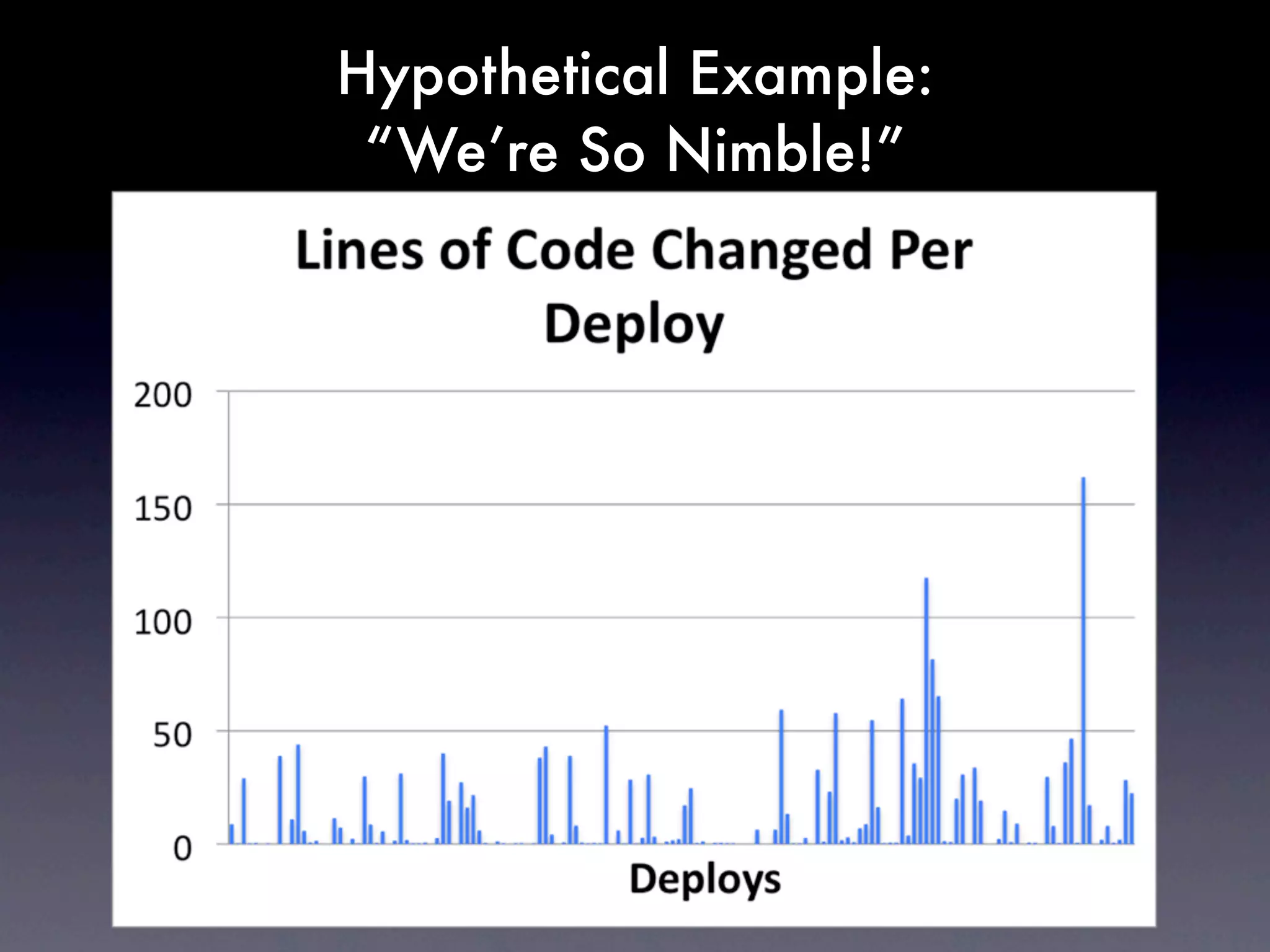
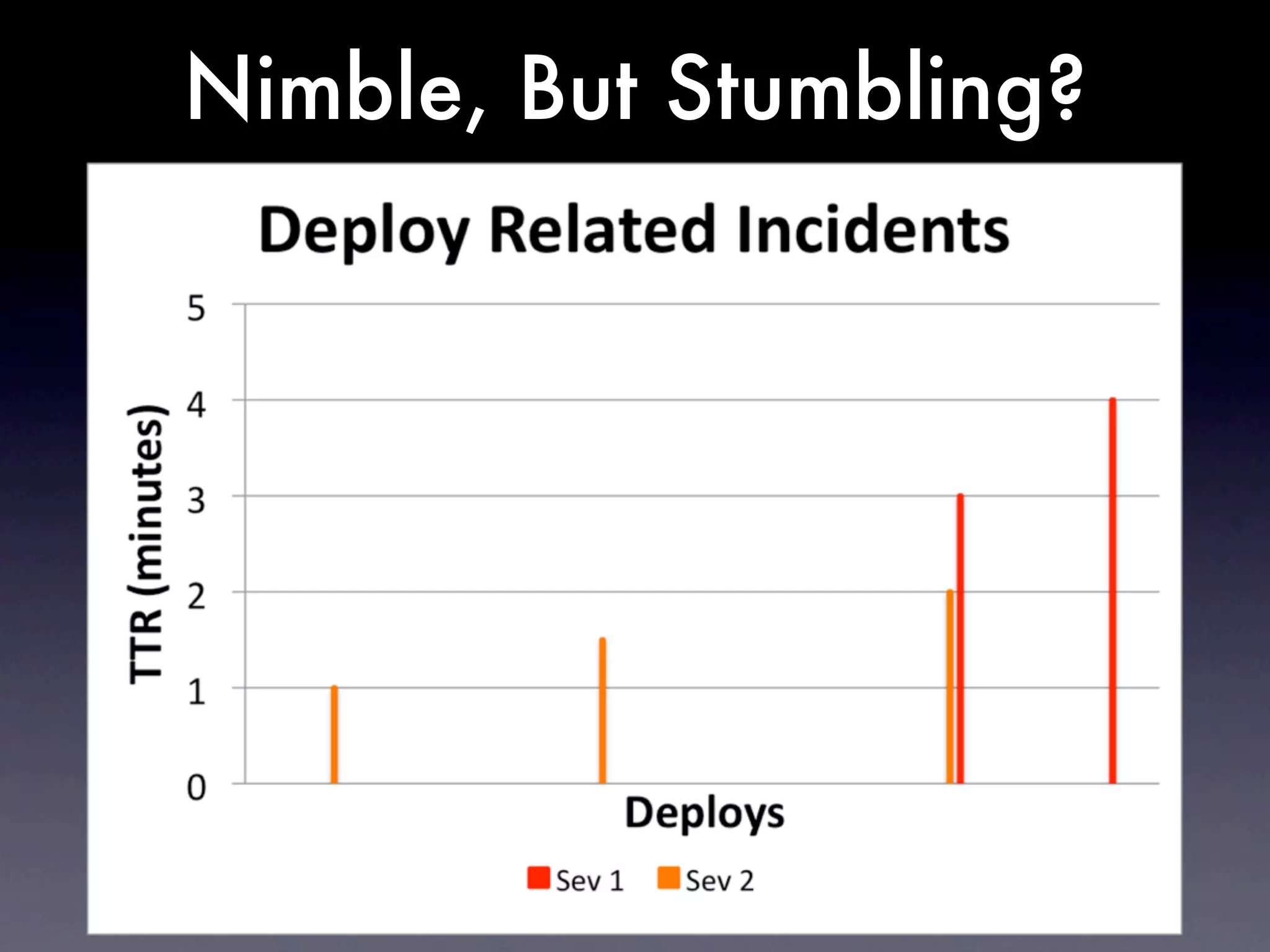

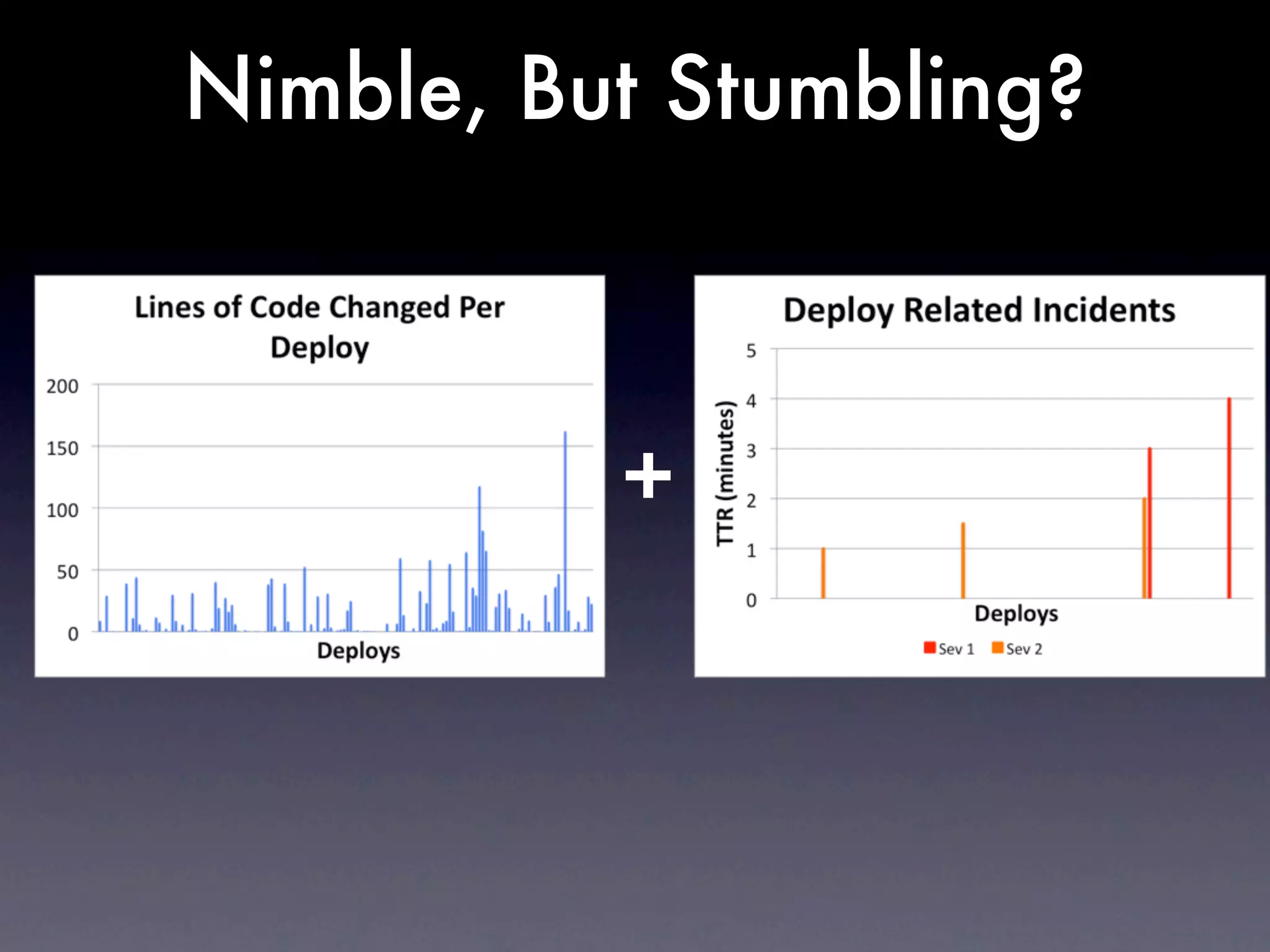
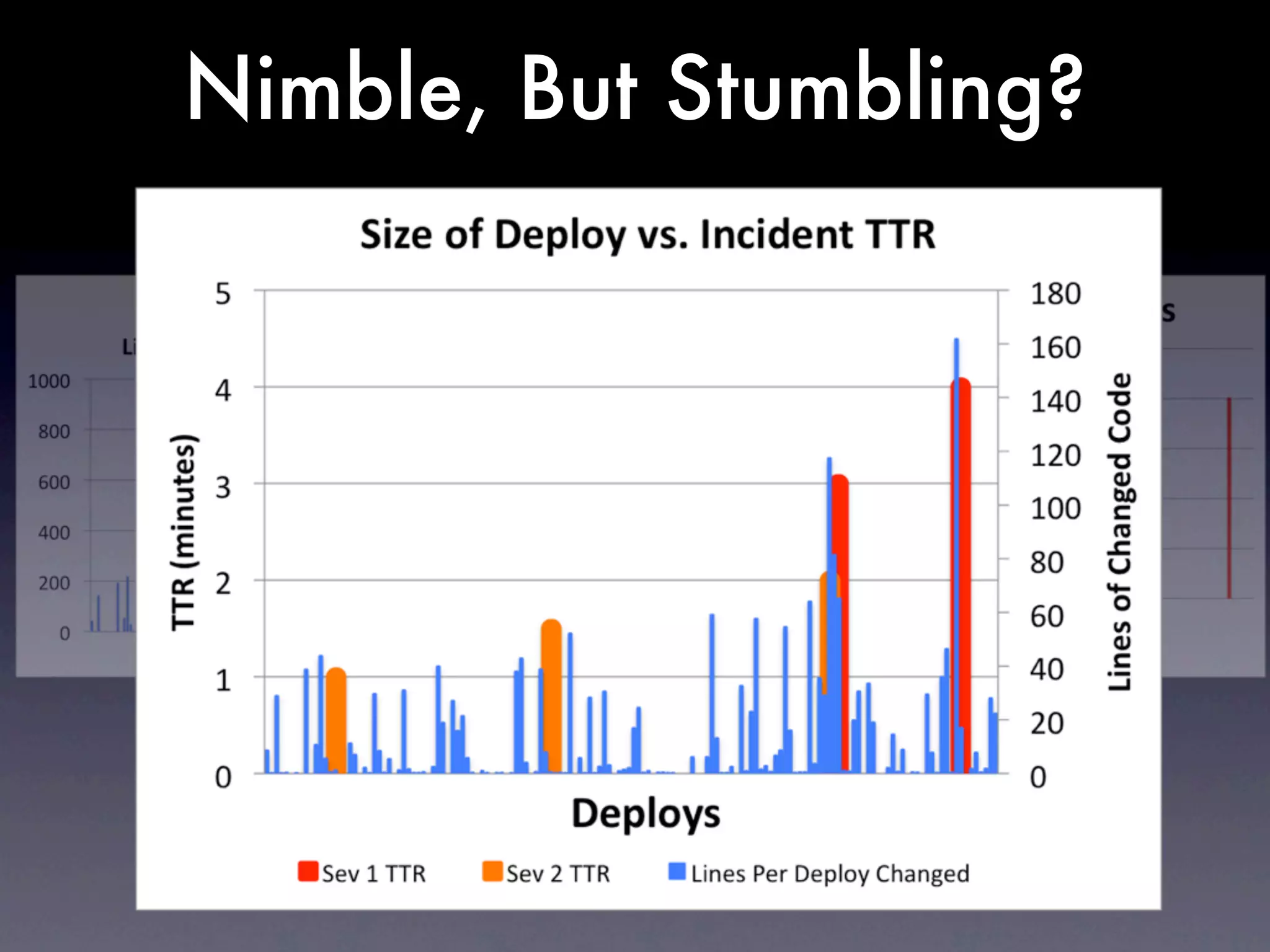
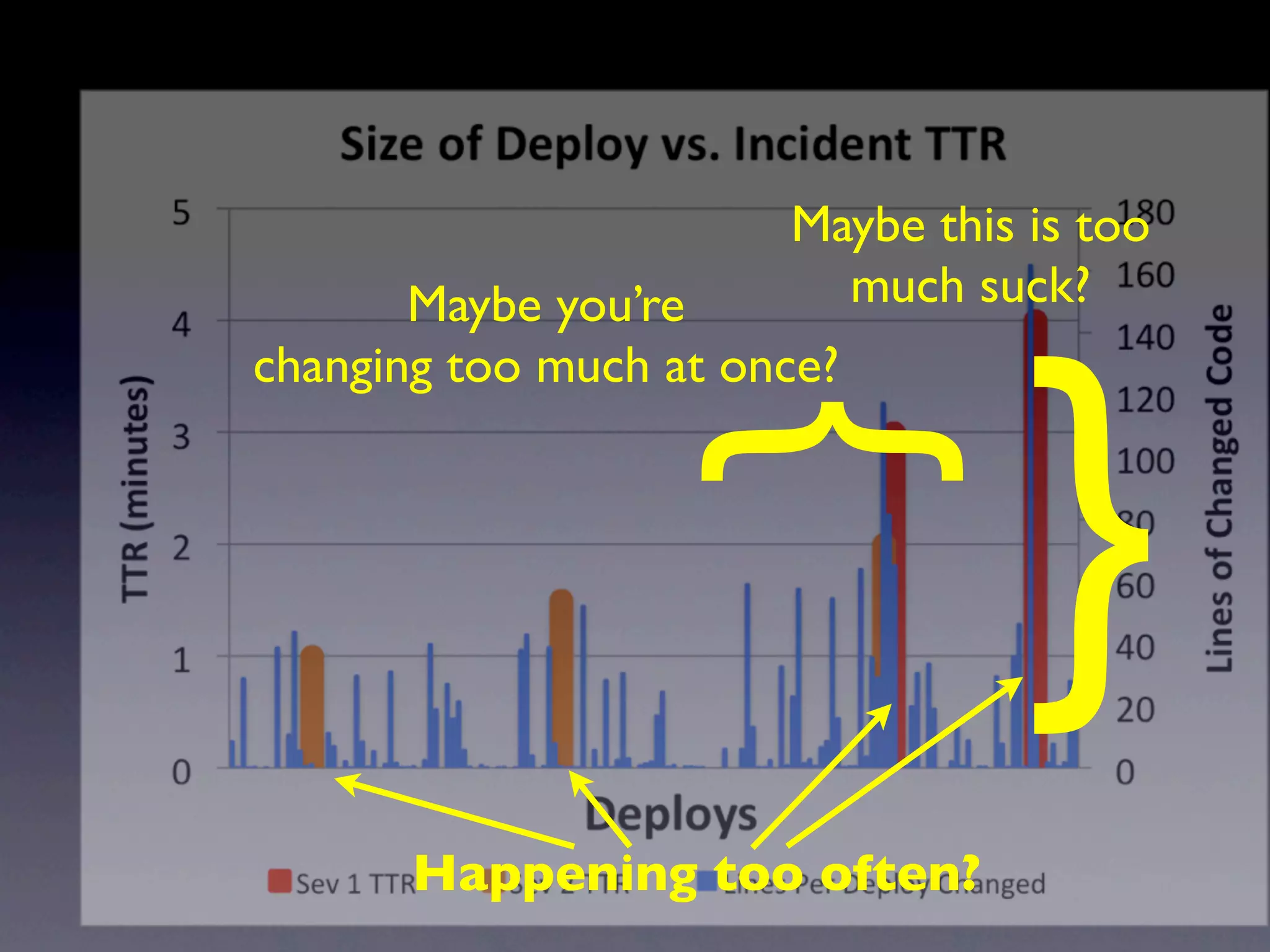







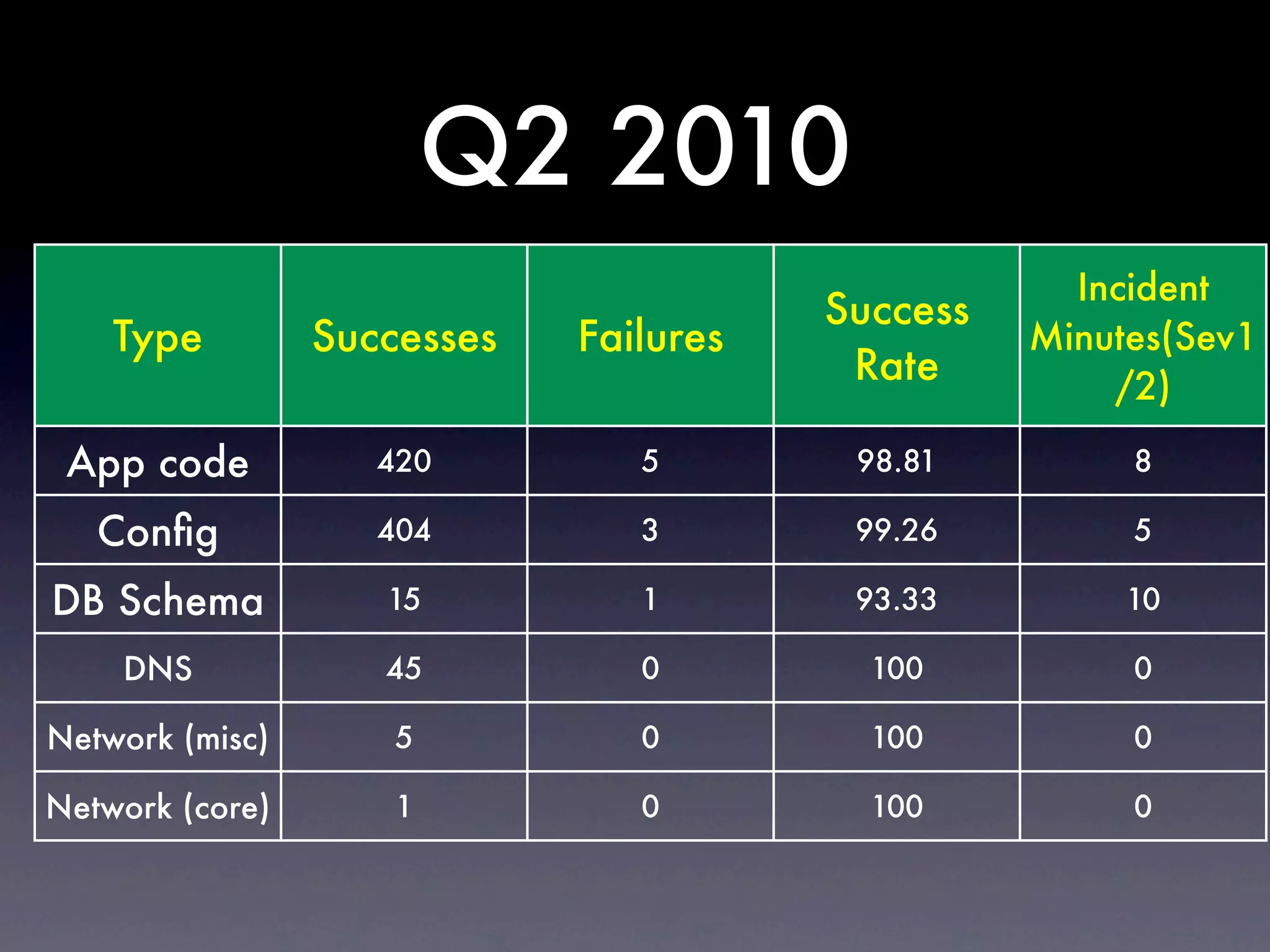
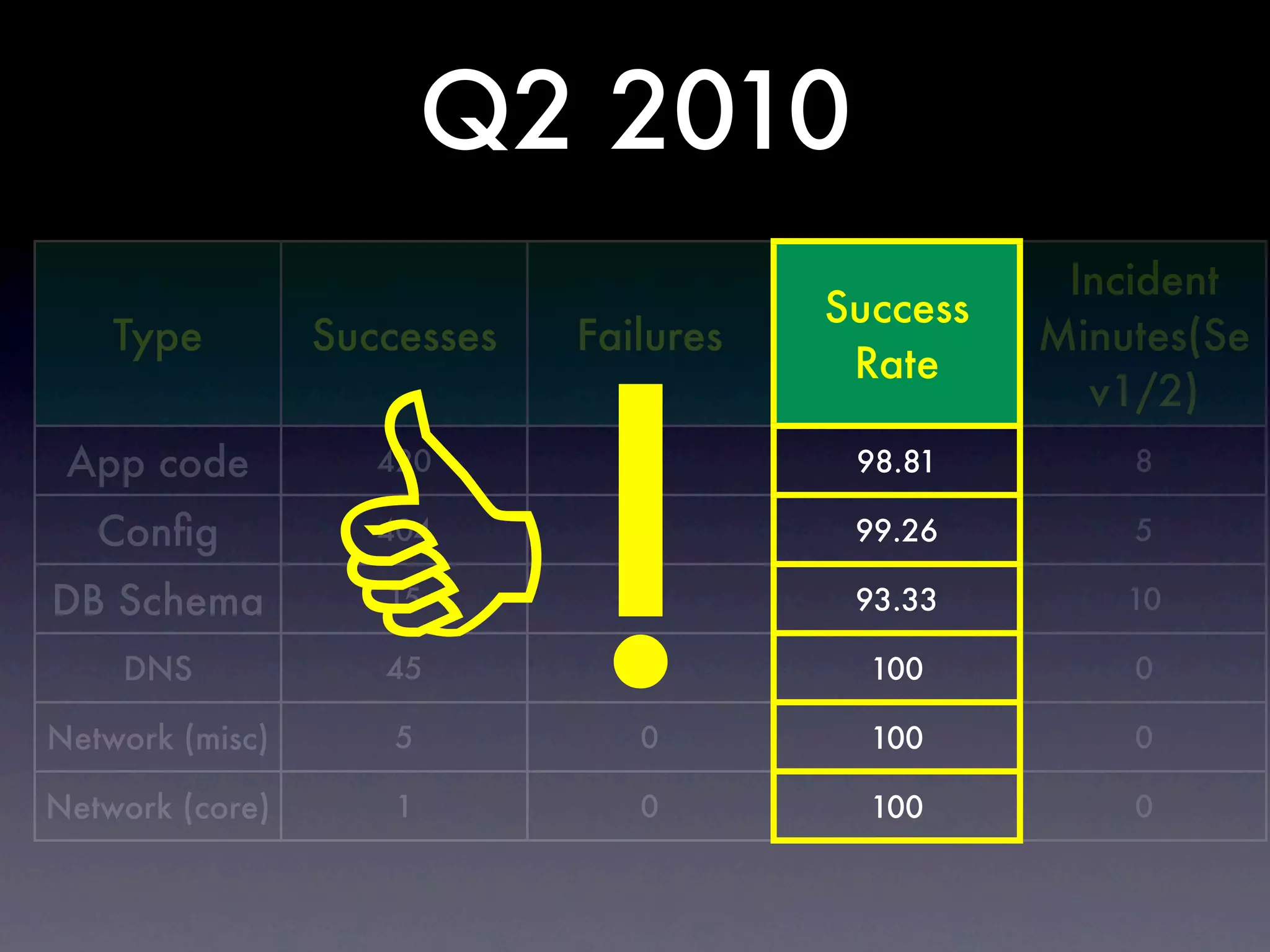

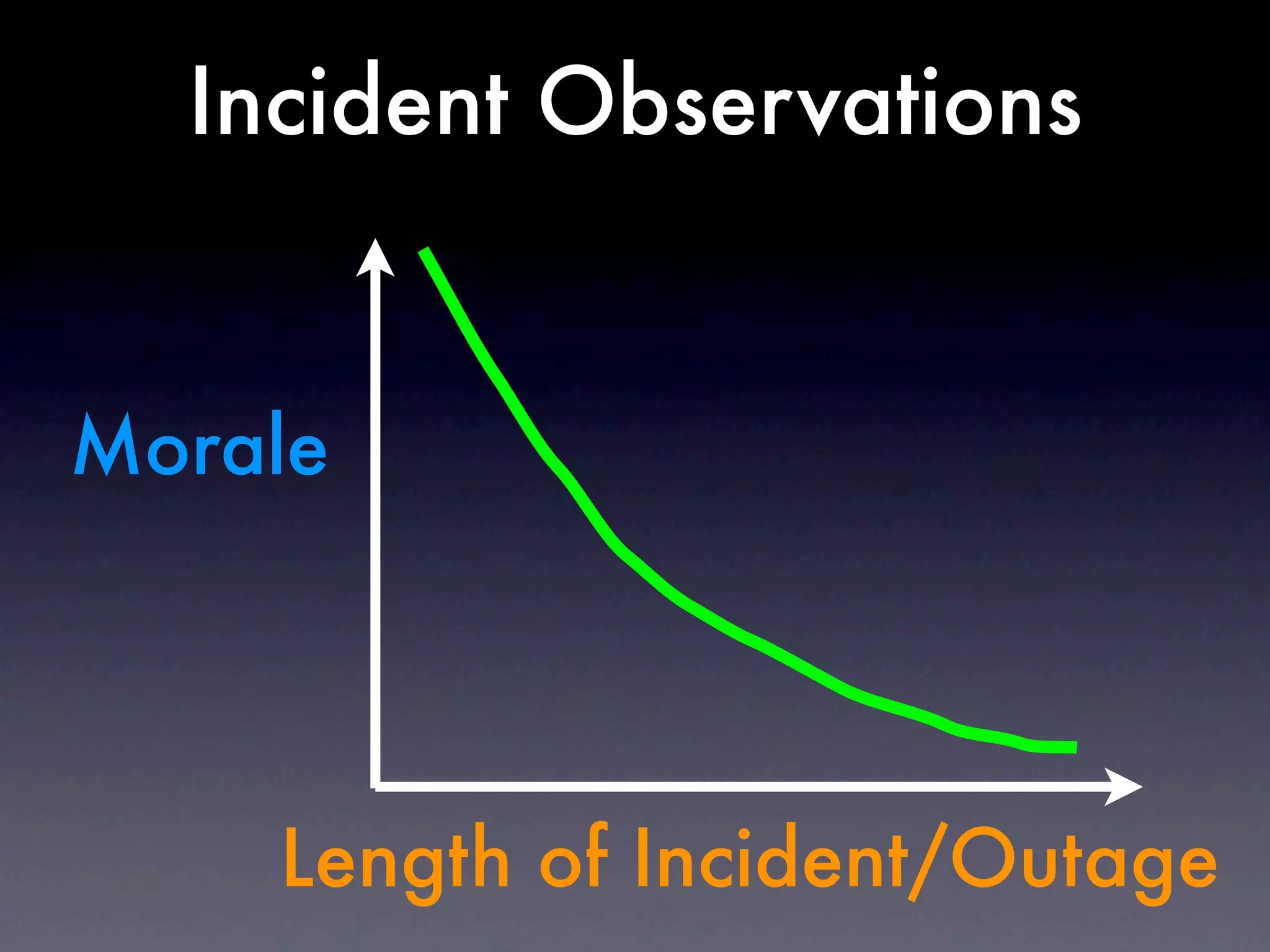
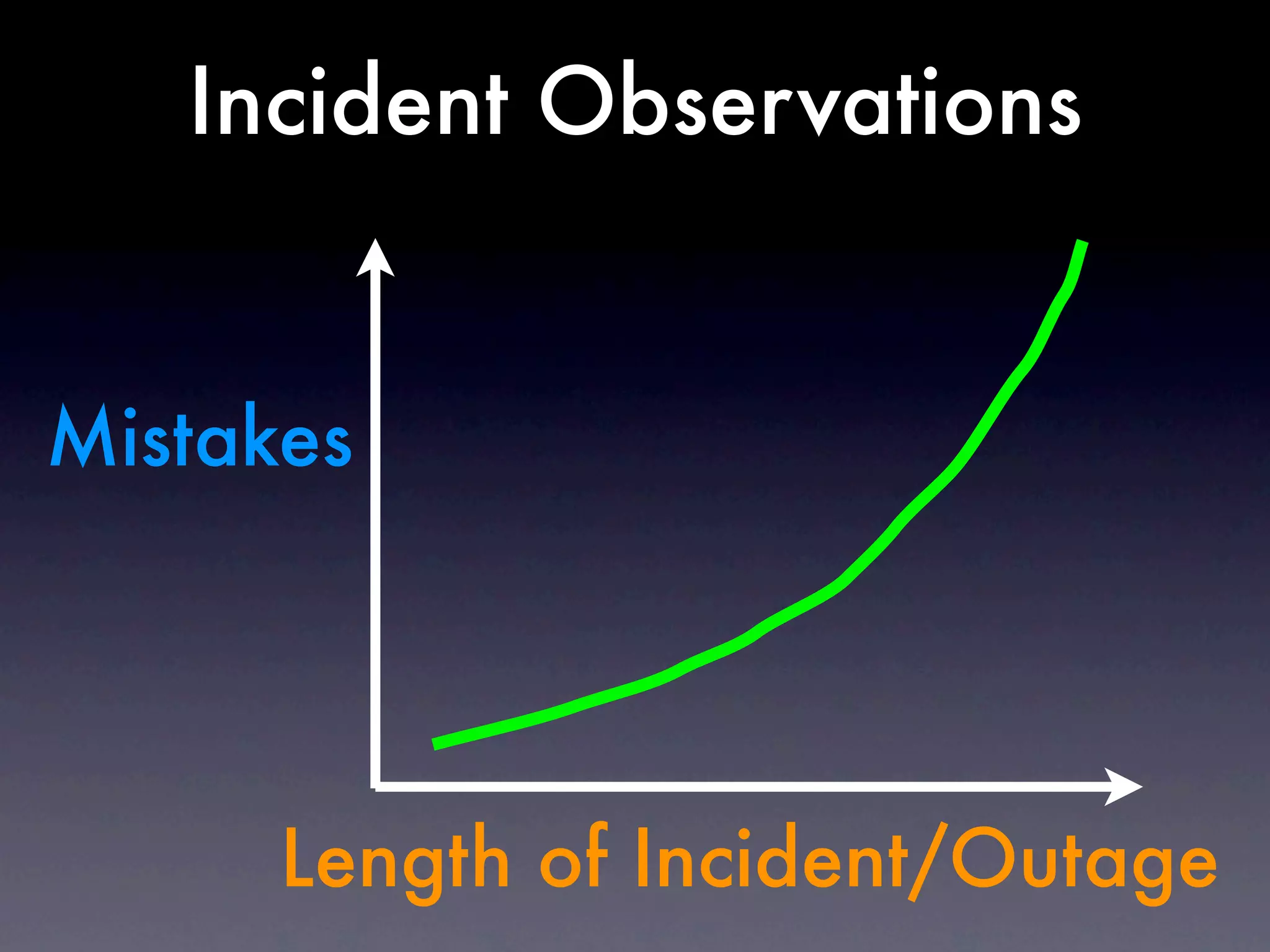
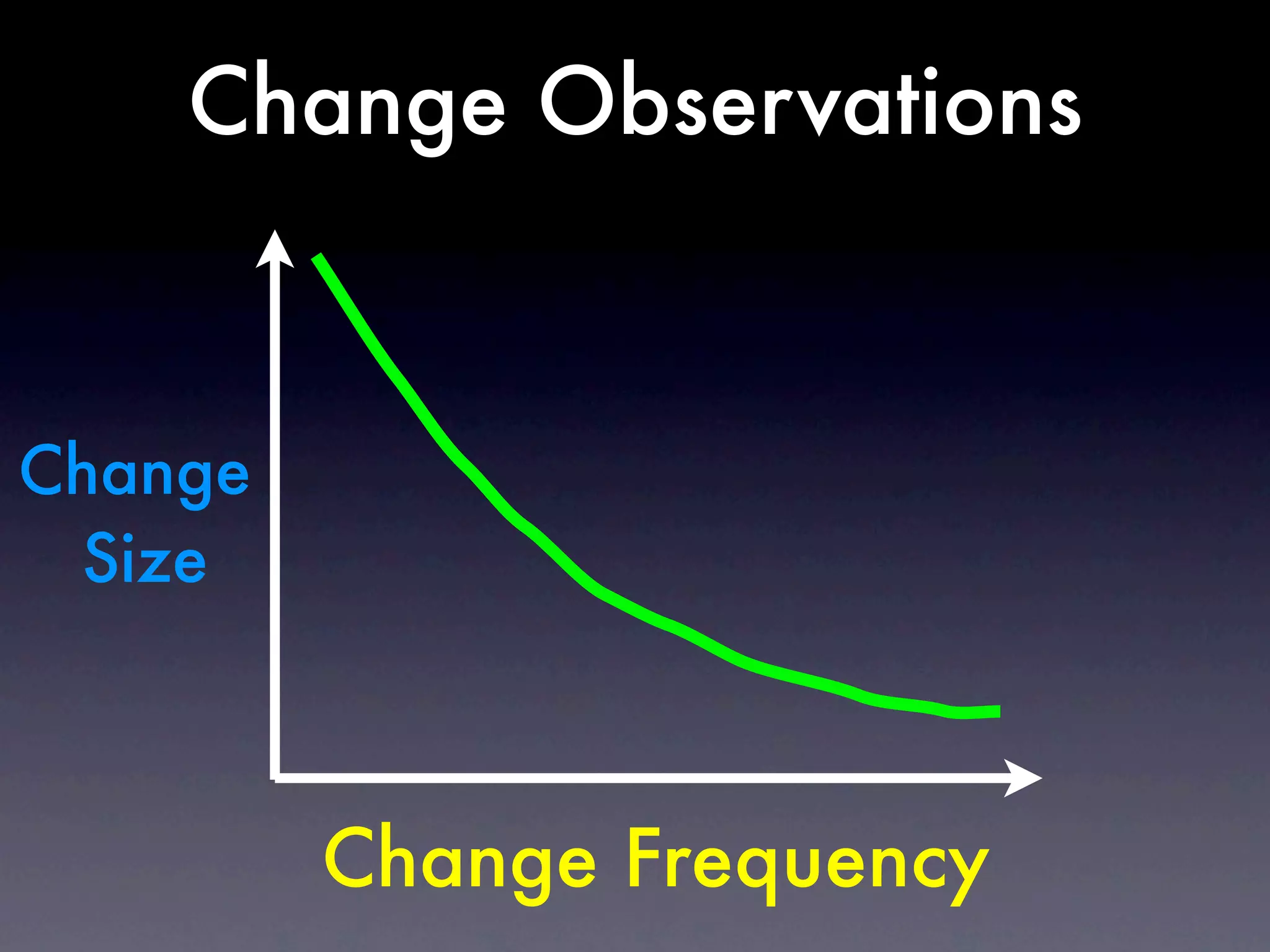
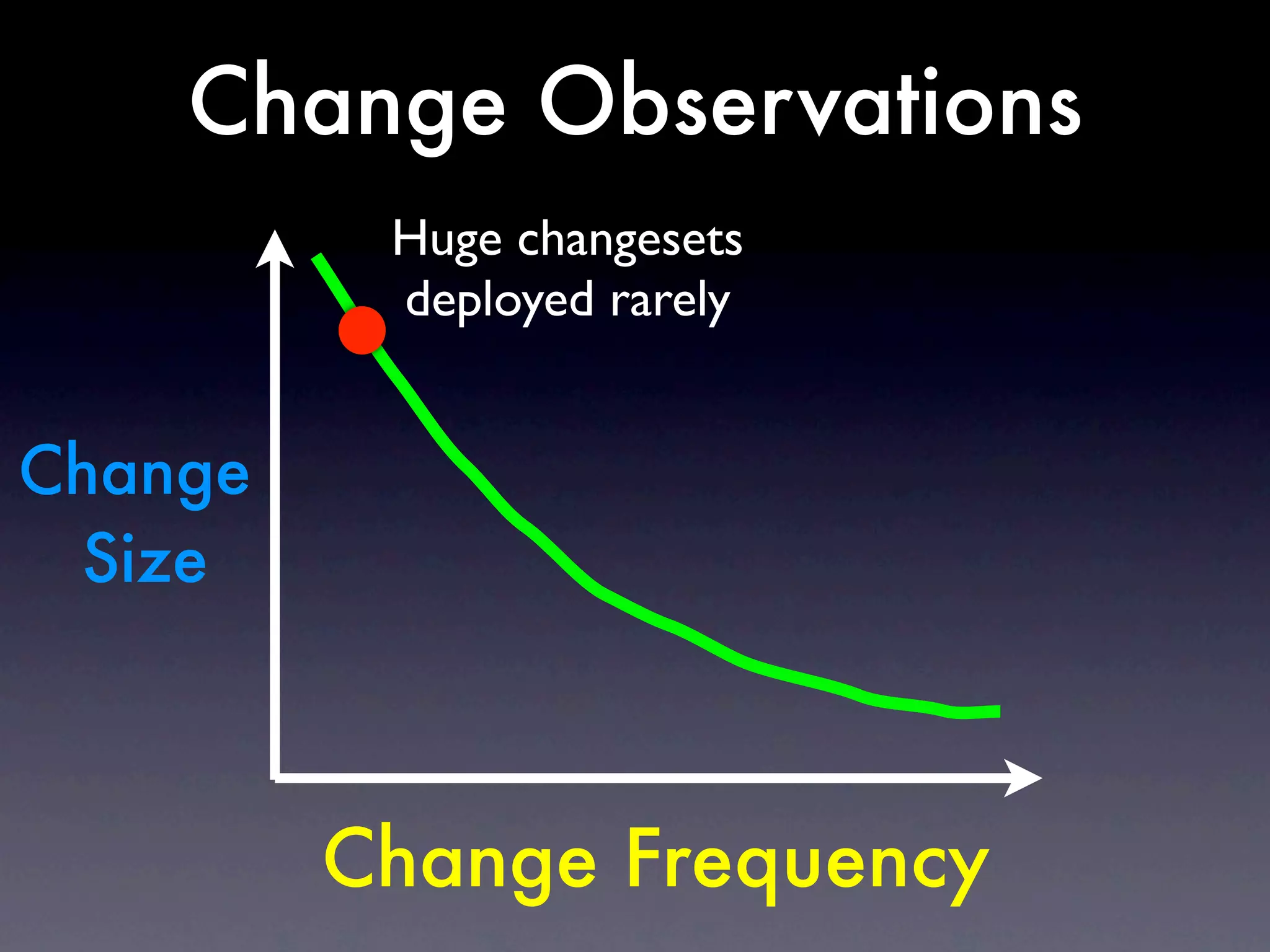
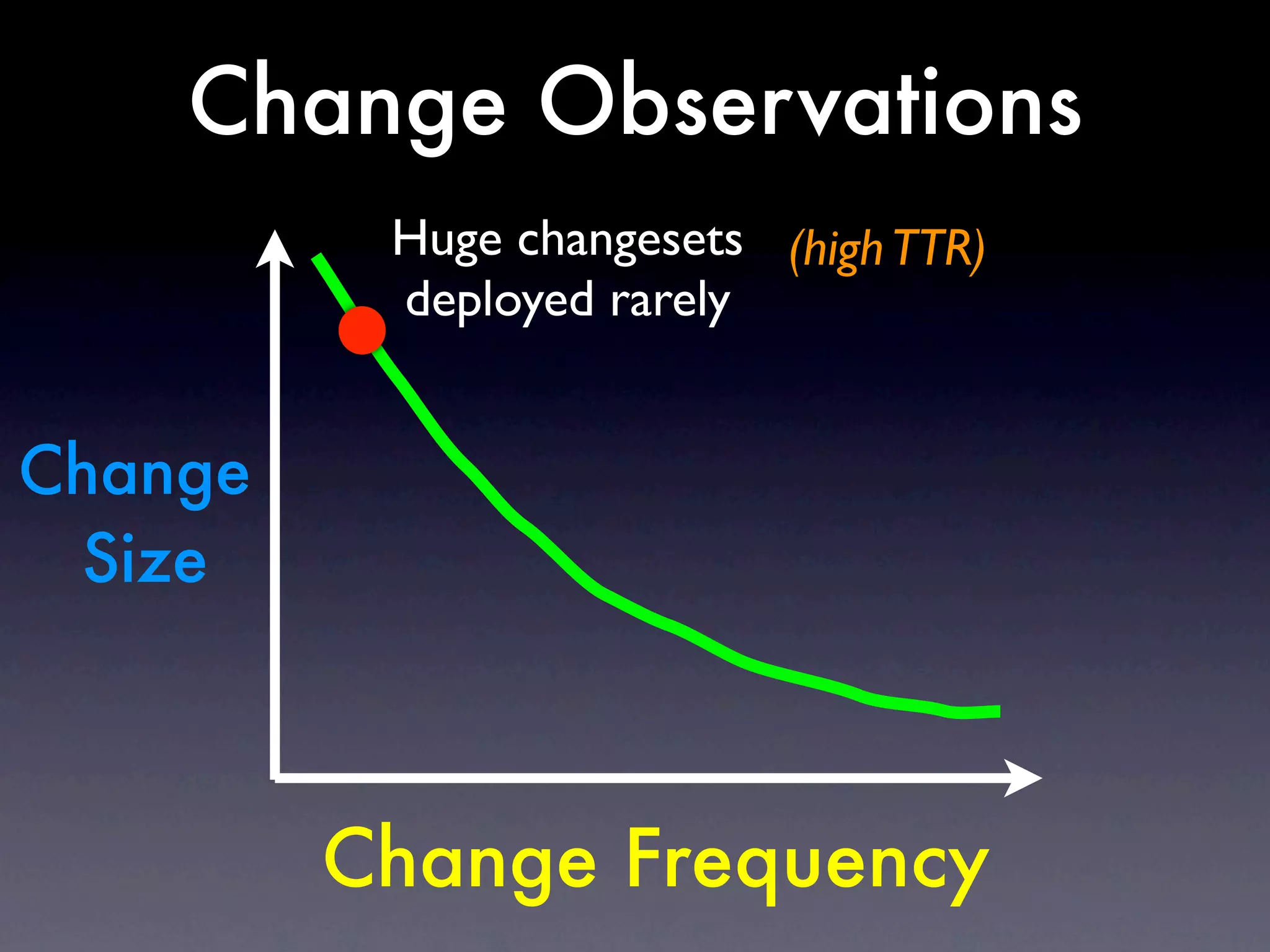
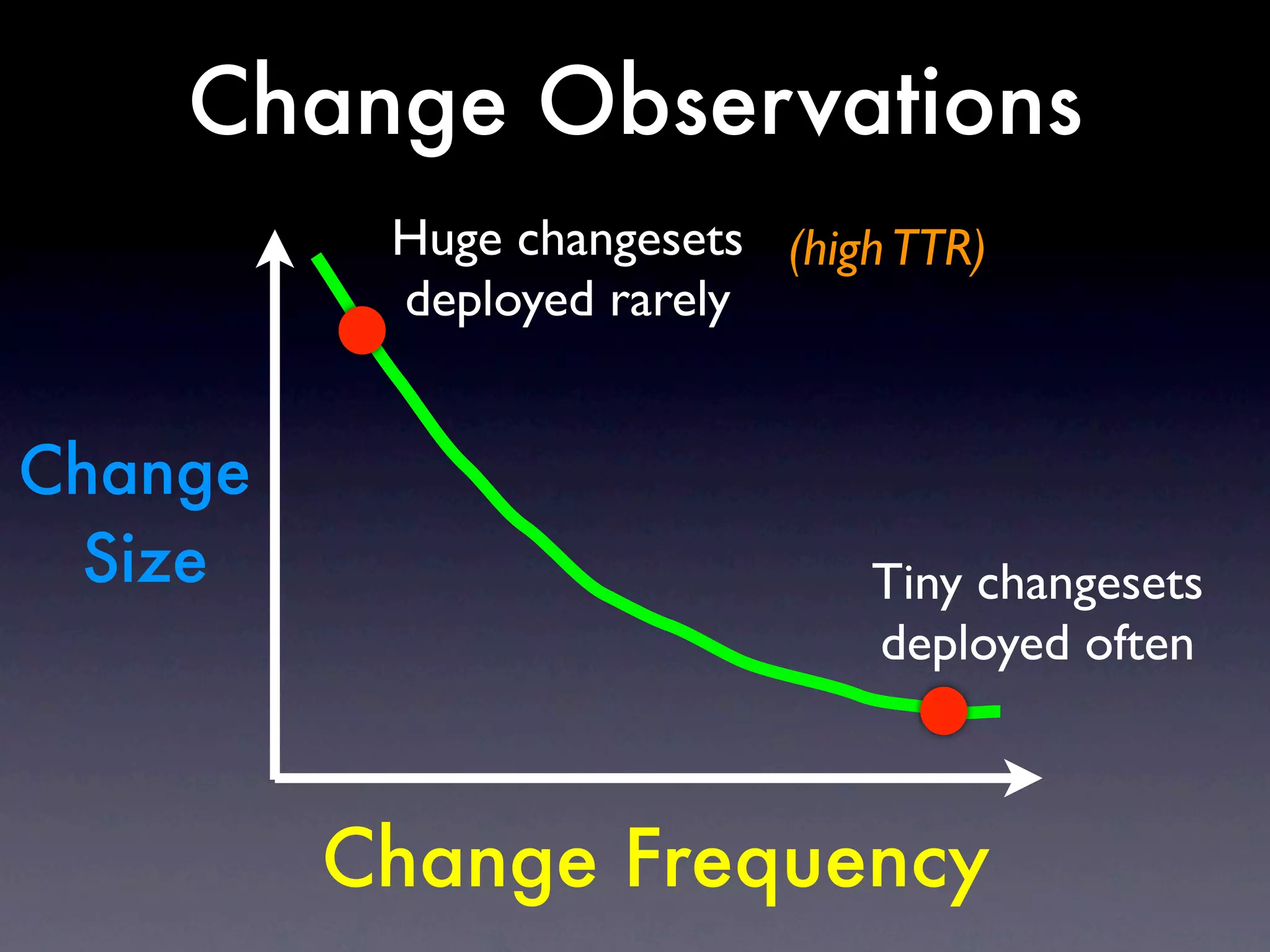
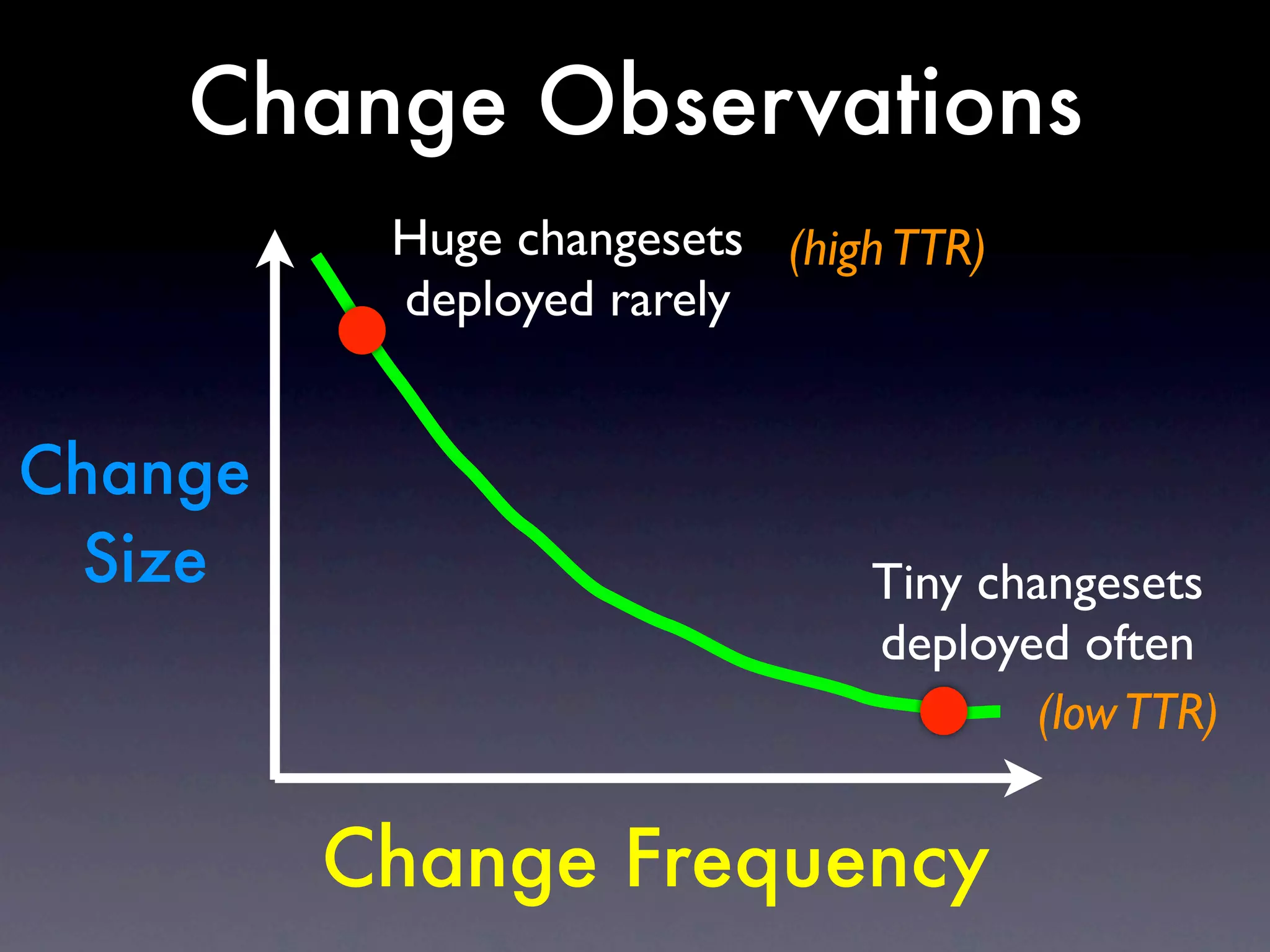






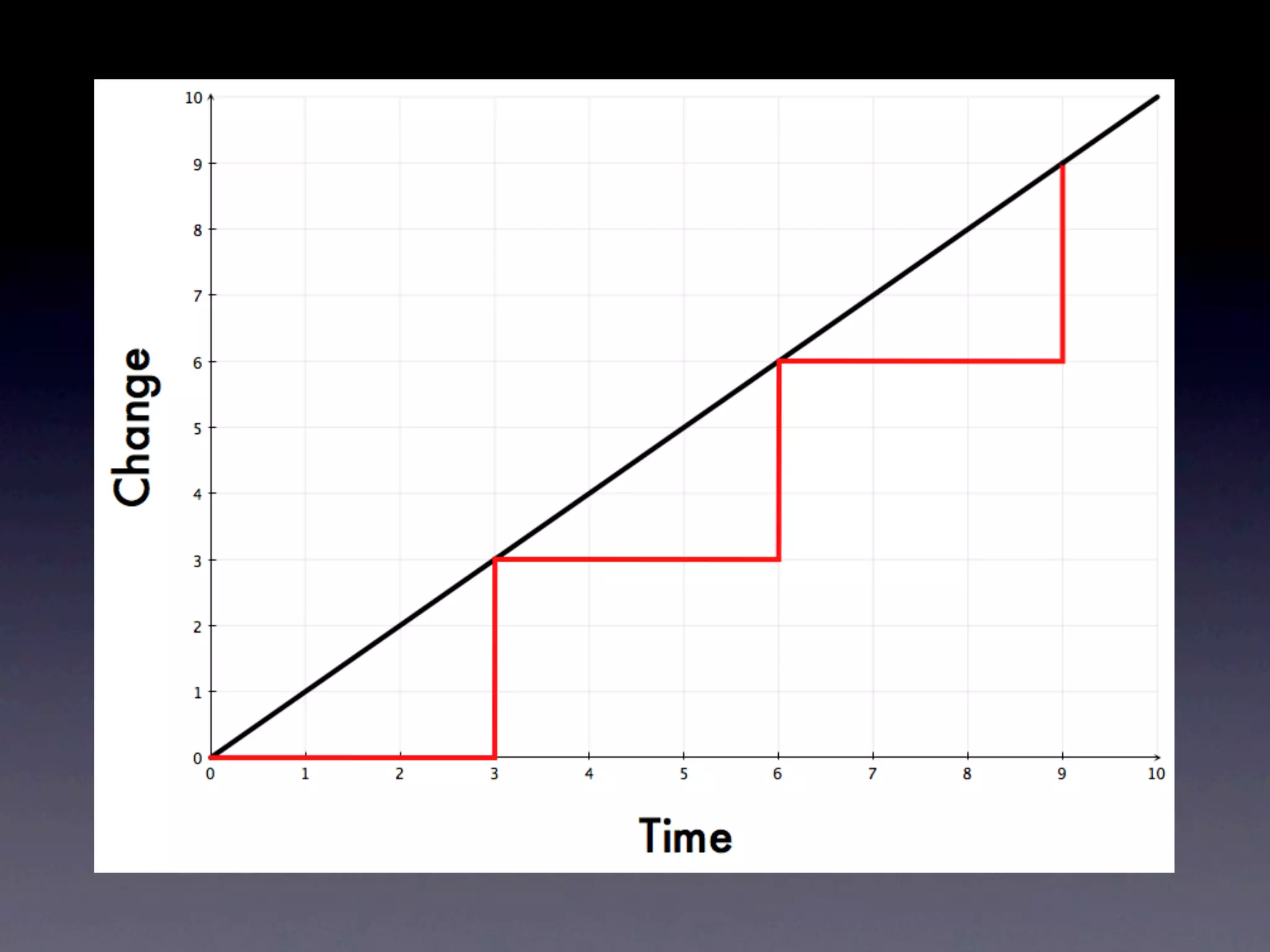

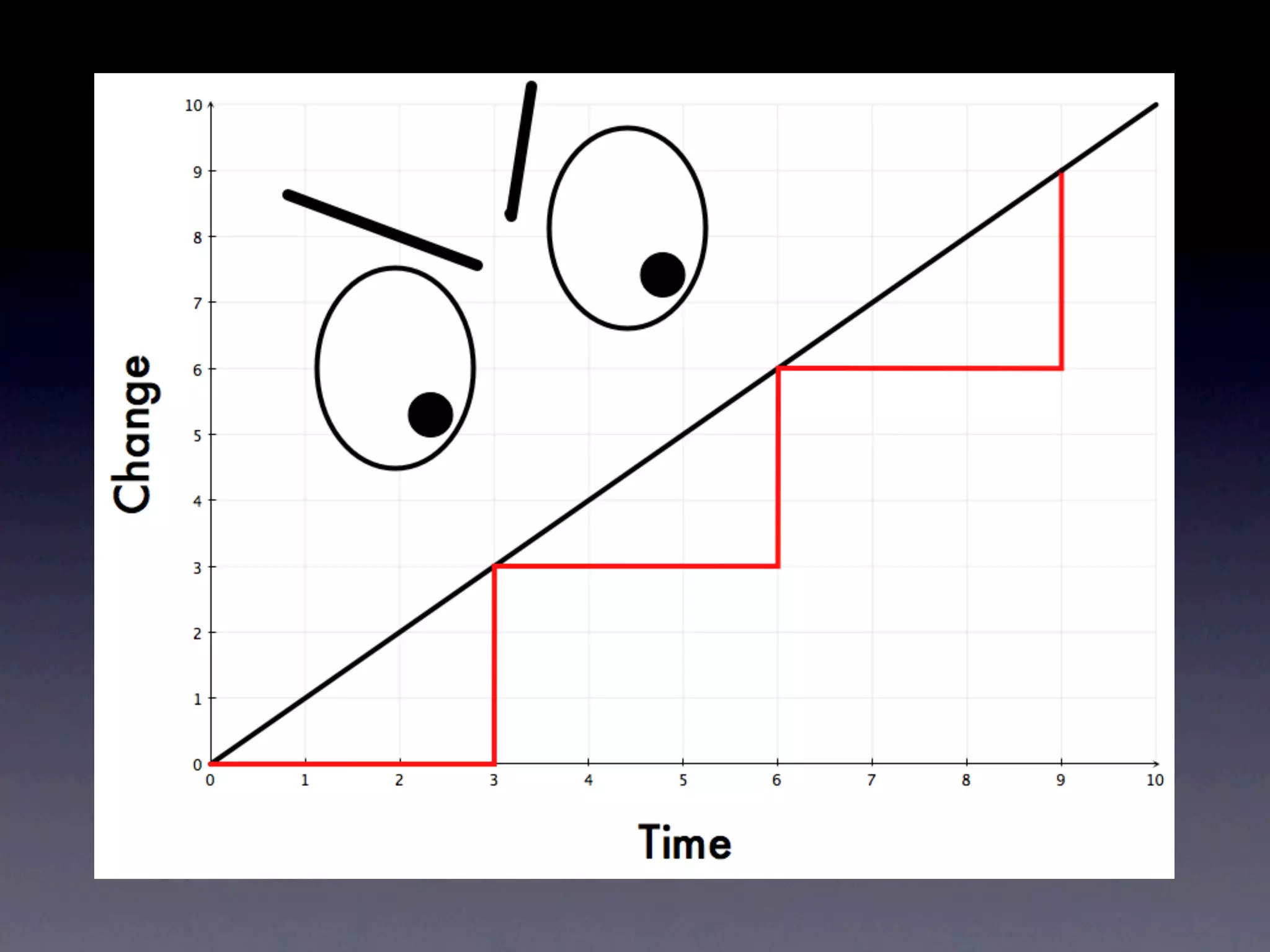
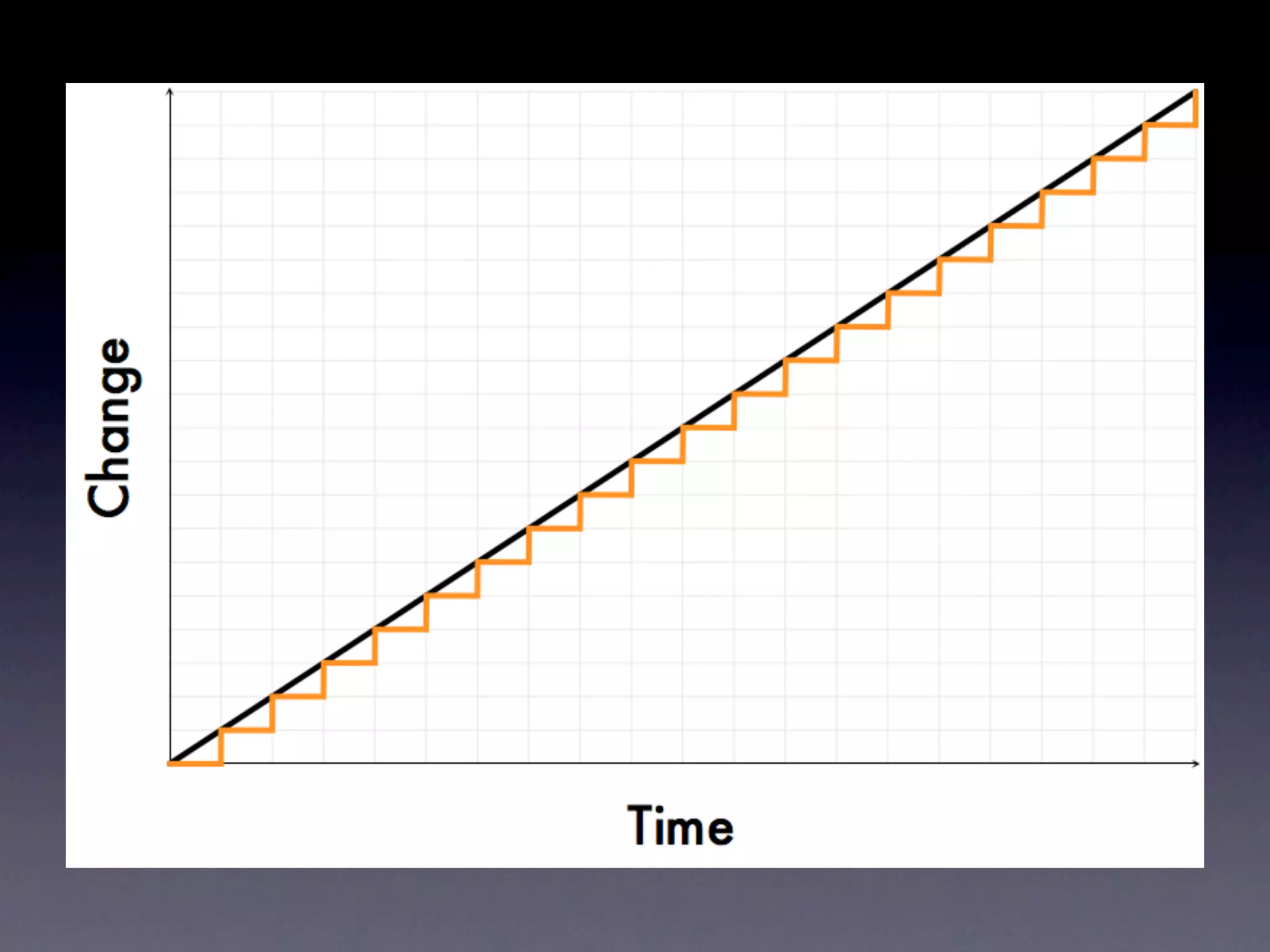
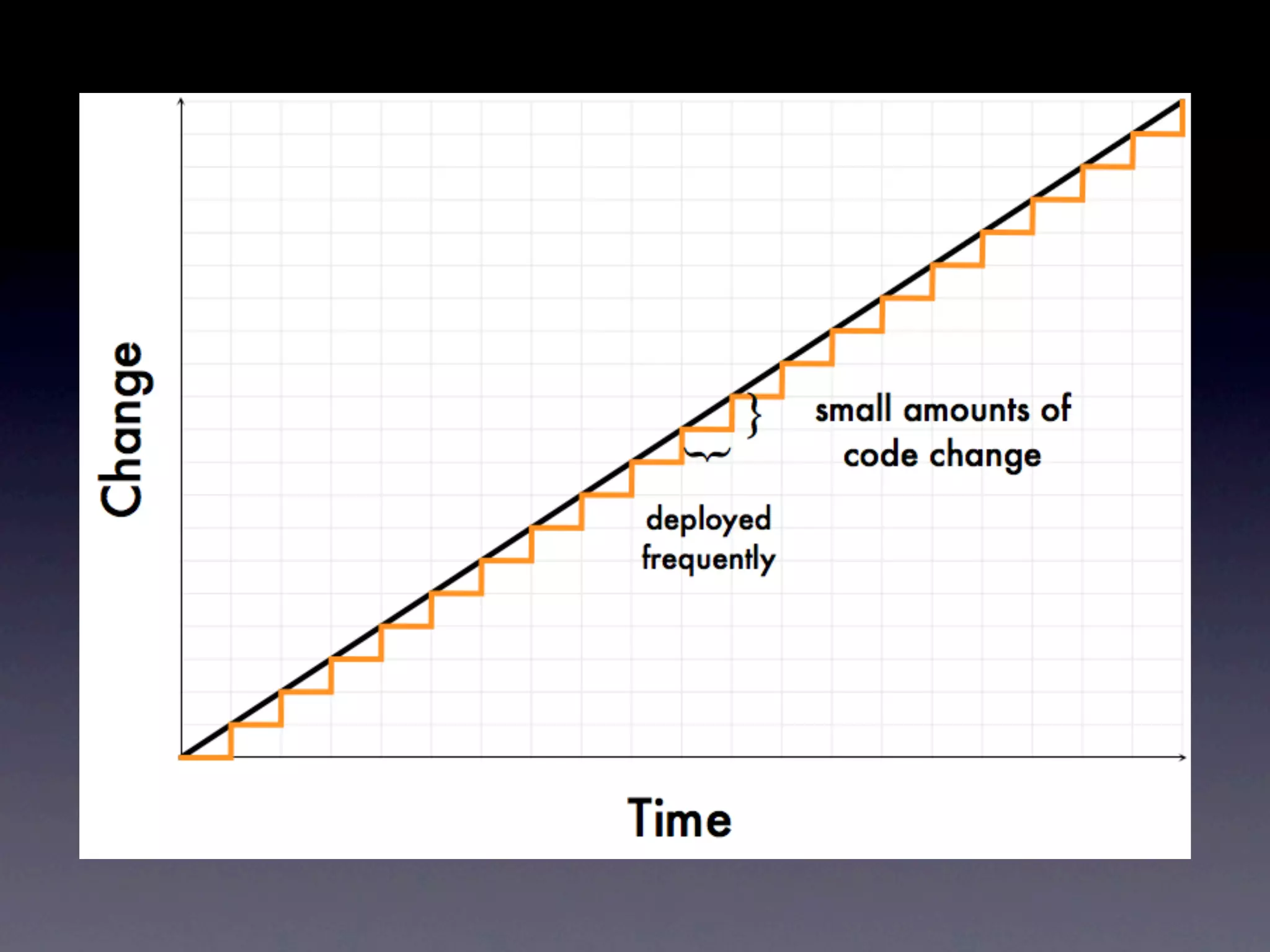
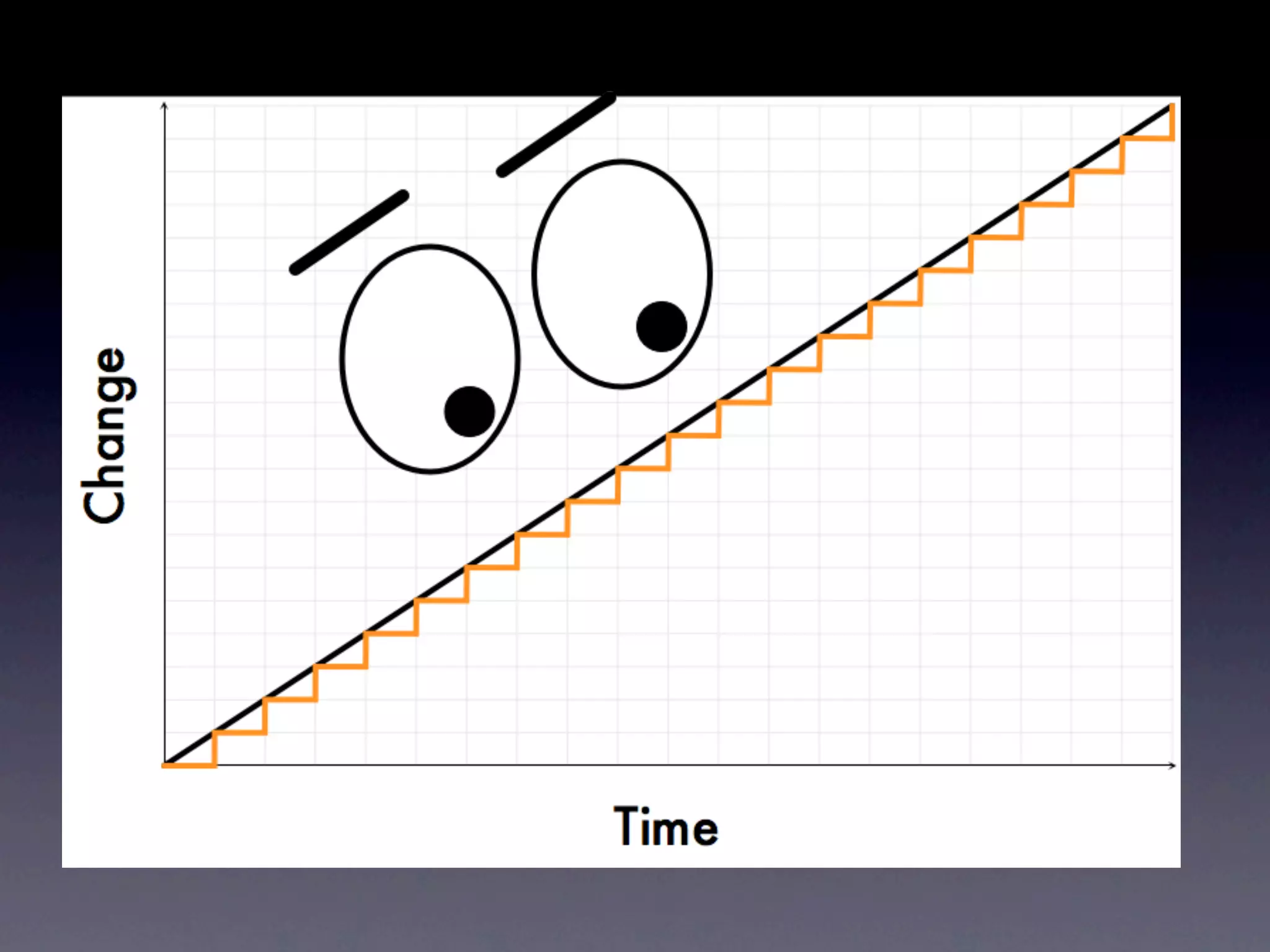

The document discusses tracking operations metrics to build confidence in an organization's ability to handle changes. It recommends tracking: 1) Types of changes made, including code, configuration, infrastructure, etc. 2) Frequency and size of changes through metrics like number of code commits. 3) Results of changes, including number of incidents related to changes and their root causes, time to detect incidents, and time to resolve them. Tracking these metrics over time can provide insight into what types of changes are most likely to cause incidents and how the organization responds to incidents on average. The data can help identify areas to improve processes and build confidence that changes do not necessarily lead to outages.




































































































