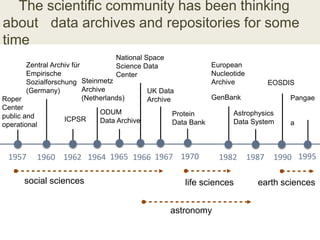
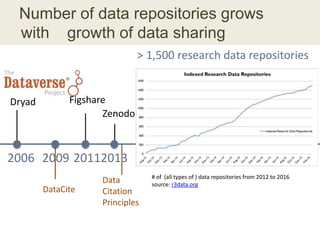
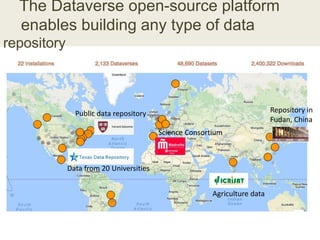
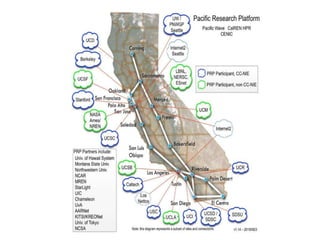
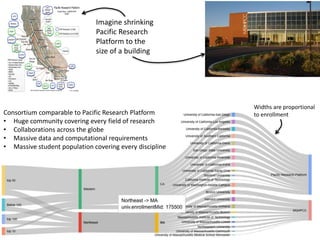
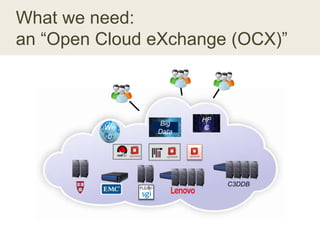
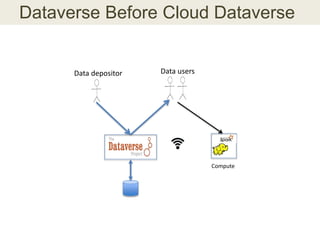
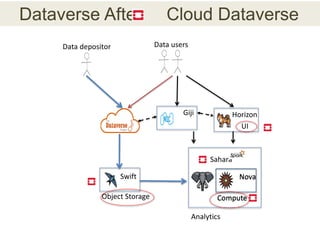
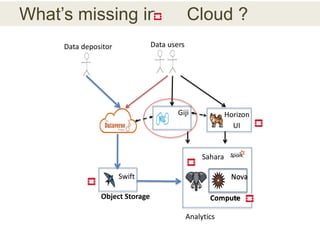
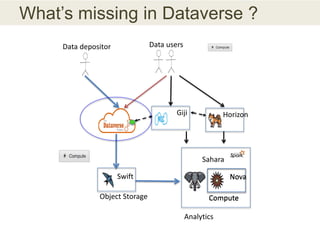
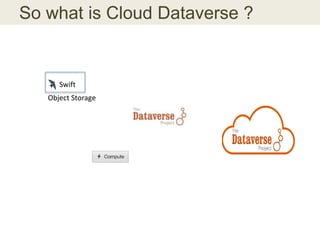
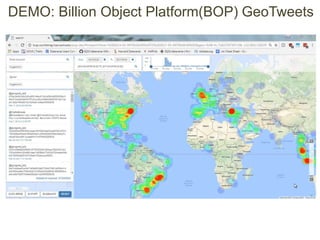
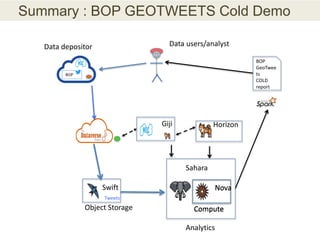
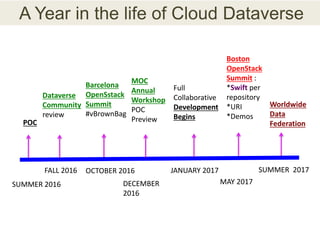
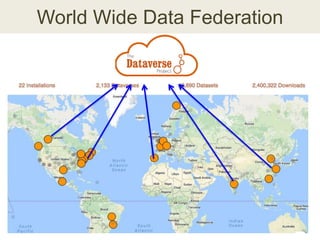
This document discusses the need for data repositories and clouds to work together. It proposes a solution called Cloud Dataverse that brings the Dataverse open-source data repository platform together with the Massachusetts Open Cloud (MOC) OpenStack cloud. Cloud Dataverse would allow data repositories to take advantage of the scalability and computing resources of the cloud, while also giving clouds access to structured data and metadata. It outlines the key components of Cloud Dataverse including Swift object storage, Nova compute, and integration with the Dataverse platform. Cloud Dataverse aims to address what is currently missing from both data repositories and clouds by enabling worldwide data sharing and federation across cloud infrastructures.