The document provides an introduction to machine learning. It discusses the author's path to becoming a data scientist and some key machine learning concepts, including:
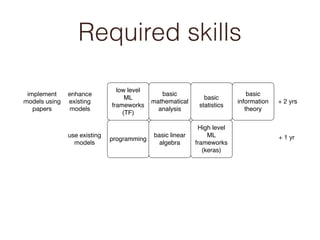
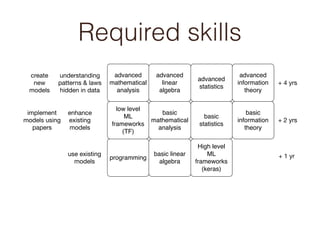
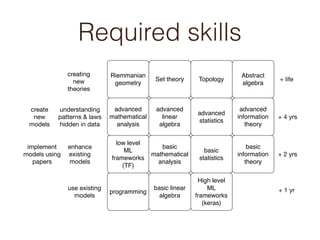
- Required skills at different experience levels for machine learning roles
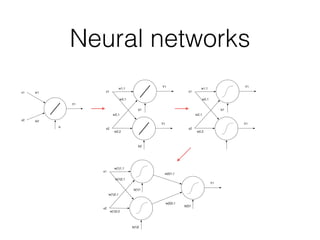
- Popular machine learning approaches like deep learning and reinforcement learning
- Common machine learning problems like one shot learning and imbalanced datasets
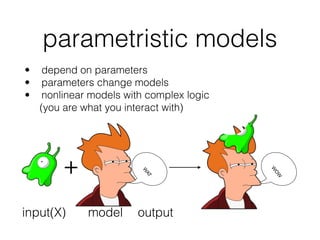
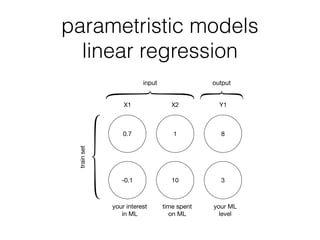
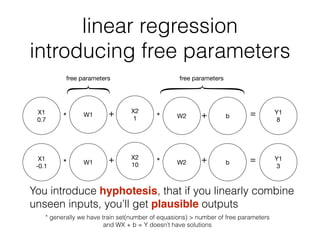
- How machine learning works by using tricks on data through parametric models and free parameters
- Key questions in machine learning like what to teach, how to teach, and to what entity
- Popular machine learning frameworks like TensorFlow that automate tasks















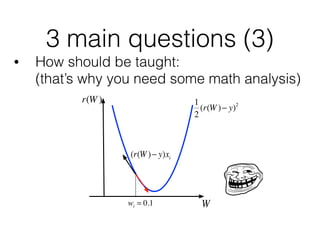

![3 main questions (3)
• How should be taught:
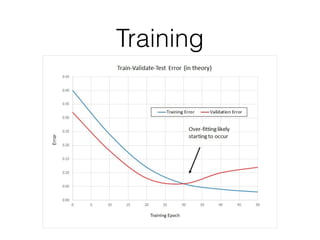
This is a simple optimizer, but there are much more.
wi = wi −η(r(W )− y)xi SGD
You may use precise information about error curvature
(2nd order optimization)[1],
or try to simulate 2nd order optimization for faster convergence[2]](https://image.slidesharecdn.com/intro2mlandhowtobecomedsinyrs-161122192126/85/Introduction-to-Machine-Learning-24-320.jpg)

![Back to linear regression
In [3]: from sklearn import linear_model
In [4]: regr = linear_model.LinearRegression()
In [5]: x_train = [[0.7, 1], [-0.1, 10]]
In [6]: x_test = [[0.8, 2]]
In [7]: y_train = [8, 3]
In [8]: y_test = [9]
In [9]: regr.fit(x_train, y_train)
Out[9]: LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
In [10]: regr.coef_
Out[10]: array([ 0.04899559, -0.55120039])
In [11]: regr.predict(x_test)
Out[11]: array([ 7.45369917])
find what’s wrong?](https://image.slidesharecdn.com/intro2mlandhowtobecomedsinyrs-161122192126/85/Introduction-to-Machine-Learning-27-320.jpg)








![Starter links
http://openclassroom.stanford.edu/MainFolder/
CoursePage.php?course=MachineLearning
[1] http://andrew.gibiansky.com/blog/machine-learning/
hessian-free-optimization/
[2] http://sebastianruder.com/optimizing-gradient-descent/
index.html#momentum](https://image.slidesharecdn.com/intro2mlandhowtobecomedsinyrs-161122192126/85/Introduction-to-Machine-Learning-38-320.jpg)







































![[update] Introductory Parts of the Book "Dive into Deep Learning"](https://cdn.slidesharecdn.com/ss_thumbnails/d2lq1introbasicssimplemodels-190415080926-thumbnail.jpg?width=640&height=640&fit=bounds)




































