Downloaded 3,462 times









































![Activity Diagram For Document Processing
Request document
processing
Process
document
[ scanner not ready ]
[ scanner ready ]
Figure 16:Activity Diagram For Processing
45
Retry for
scanning
Scan
documents
Store
documents](https://image.slidesharecdn.com/projectreport-ocrrecognition-140903052518-phpapp02/75/Project-report-of-OCR-Recognition-45-2048.jpg)
![[ Document exists ]
Retrieves
document
Figure 17:Activity Diagram for document Retrieval
46
Request
document
Initiate search
Returns
message
Sends document to
user
[ Document does not exist ]](https://image.slidesharecdn.com/projectreport-ocrrecognition-140903052518-phpapp02/75/Project-report-of-OCR-Recognition-46-2048.jpg)
![Activity Diagram For Document Storage
Edit
documents
[ user choses modify ]
Figure 18:Activity Diagram for Document Storage
47
Delete document
content
Add document [ user choses delete ]
content
[ user choses add ]
Modify
document
Store
documents](https://image.slidesharecdn.com/projectreport-ocrrecognition-140903052518-phpapp02/75/Project-report-of-OCR-Recognition-47-2048.jpg)



![5.CODING/CODE TEMPLATES
51
Sample Code
CODE SNIPPETS FOR TRAINING
public class TrainingSet
{
protected int inputCount;
protected int outputCount;
protected double input[][];
protected double output[][];
protected double classify[];
protected int trainingSetCount;
TrainingSet ( int inputCount , int outputCount )
{
this.inputCount = inputCount;s
this.outputCount = outputCount;
trainingSetCount = 0;
}
public int getInputCount()
{
return inputCount;](https://image.slidesharecdn.com/projectreport-ocrrecognition-140903052518-phpapp02/75/Project-report-of-OCR-Recognition-51-2048.jpg)
![52
}
public int getOutputCount()
{
return outputCount;
}
public void setTrainingSetCount(int trainingSetCount)
{
this.trainingSetCount = trainingSetCount;
input = new double[trainingSetCount][inputCount];
output = new double[trainingSetCount][outputCount];
classify = new double[trainingSetCount];
}
public int getTrainingSetCount()
{
return trainingSetCount;
}
void setInput(int set,int index,double value) throws RuntimeException
{
if ( (set<0) || (set>=trainingSetCount) )
throw(new RuntimeException("Training set out of range:" + set ));
if ( (index<0) || (index>=inputCount) )
throw(new RuntimeException("Training input index out of range:" + index ));
input[set][index] = value;](https://image.slidesharecdn.com/projectreport-ocrrecognition-140903052518-phpapp02/75/Project-report-of-OCR-Recognition-52-2048.jpg)
![53
}
void setOutput(int set,int index,double value)
throws RuntimeException
{
if ( (set<0) || (set>=trainingSetCount) )
throw(new RuntimeException("Training set out of range:" + set ));
if ( (index<0) || (set>=outputCount) )
throw(new RuntimeException("Training input index out of range:" + index ));
output[set][index] = value;
}
void setClassify(int set,double value)
throws RuntimeException
{
if ( (set<0) || (set>=trainingSetCount) )
throw(new RuntimeException("Training set out of range:" + set ));
classify[set] = value;
}
double getInput(int set,int index)
throws RuntimeException
{
if ( (set<0) || (set>=trainingSetCount) )
throw(new RuntimeException("Training set out of range:" + set ));
if ( (index<0) || (index>=inputCount) )](https://image.slidesharecdn.com/projectreport-ocrrecognition-140903052518-phpapp02/75/Project-report-of-OCR-Recognition-53-2048.jpg)
![throw(new RuntimeException("Training input index out of range:" + index ));
54
return input[set][index];
}
double getOutput(int set,int index)
throws RuntimeException
{
if ( (set<0) || (set>=trainingSetCount) )
throw(new RuntimeException("Training set out of range:" + set ));
if ( (index<0) || (set>=outputCount) )
throw(new RuntimeException("Training input index out of range:" + index ));
return output[set][index];
}
double getClassify(int set)
throws RuntimeException
{
if ( (set<0) || (set>=trainingSetCount) )
throw(new RuntimeException("Training set out of range:" + set ));
return classify[set];
}
void CalculateClass(int c)
{for ( int i=0;i<=trainingSetCount;i++ ) {
classify[i] = c + 0.1;
} }](https://image.slidesharecdn.com/projectreport-ocrrecognition-140903052518-phpapp02/75/Project-report-of-OCR-Recognition-54-2048.jpg)
![55
double []getOutputSet(int set)
throws RuntimeException
{if ( (set<0) || (set>=trainingSetCount) )
throw(new RuntimeException("Training set out of range:" + set ));
return output[set];}
double []getInputSet(int set)
throws RuntimeException
{
if ( (set<0) || (set>=trainingSetCount) )
throw(new RuntimeException("Training set out of range:" + set ));
return input[set];
}
}](https://image.slidesharecdn.com/projectreport-ocrrecognition-140903052518-phpapp02/75/Project-report-of-OCR-Recognition-55-2048.jpg)







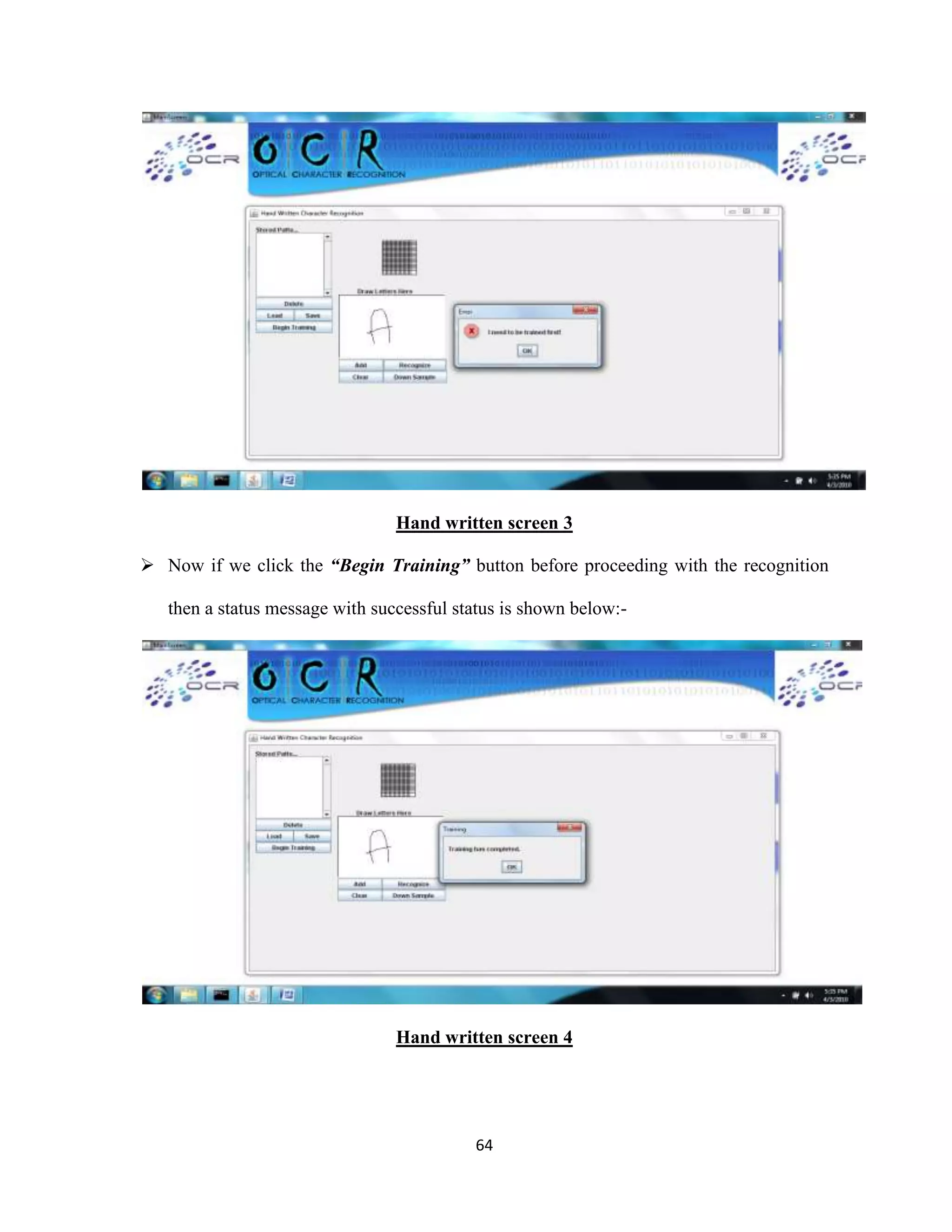

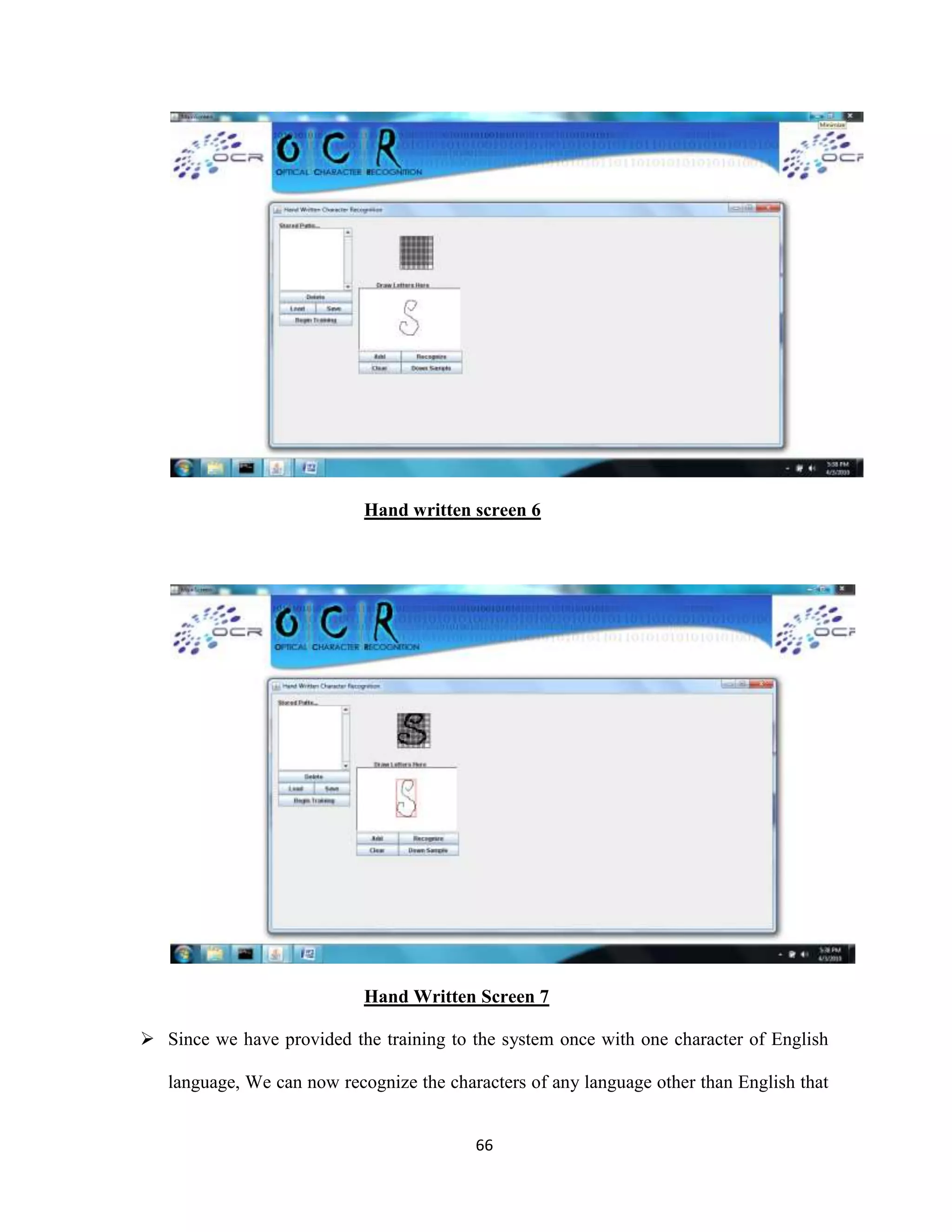
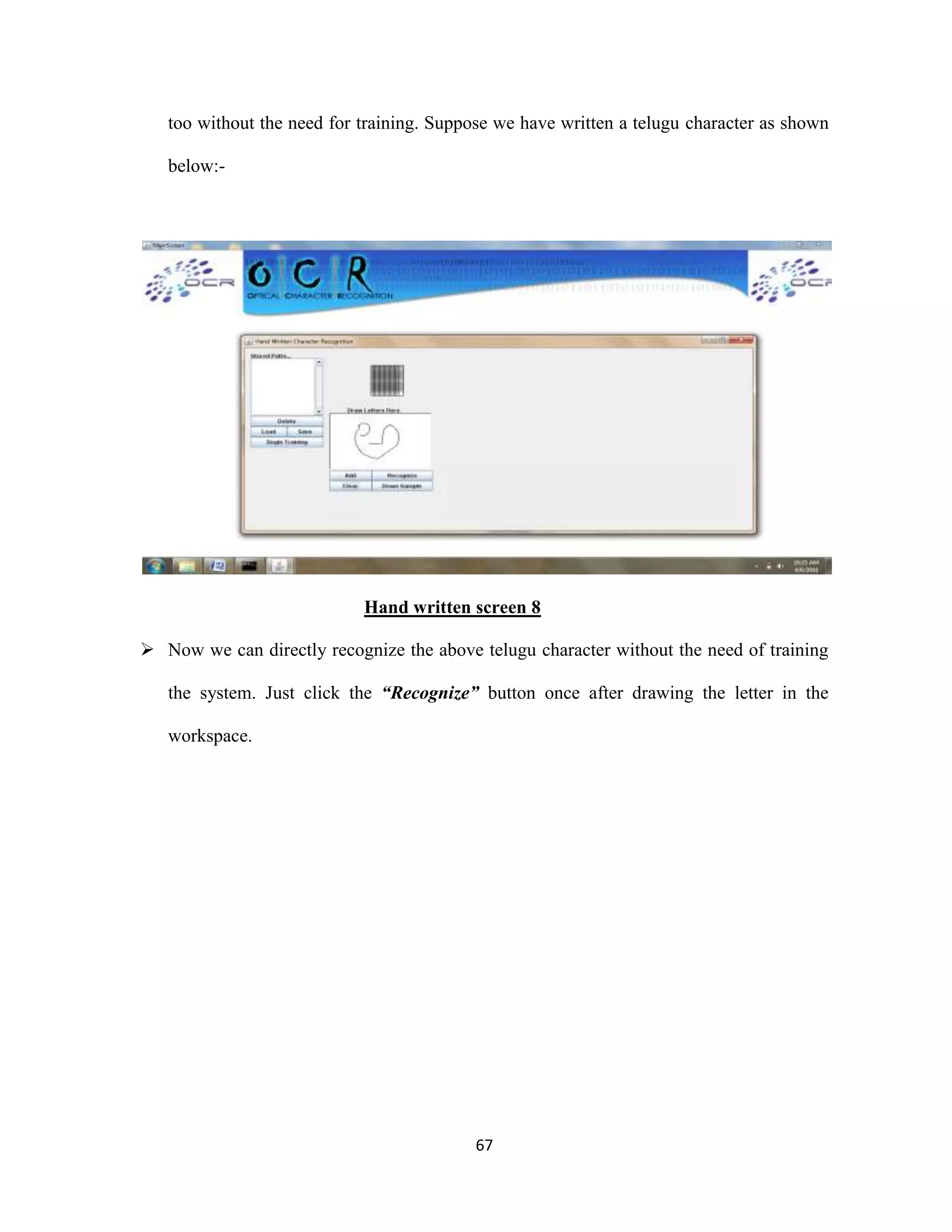
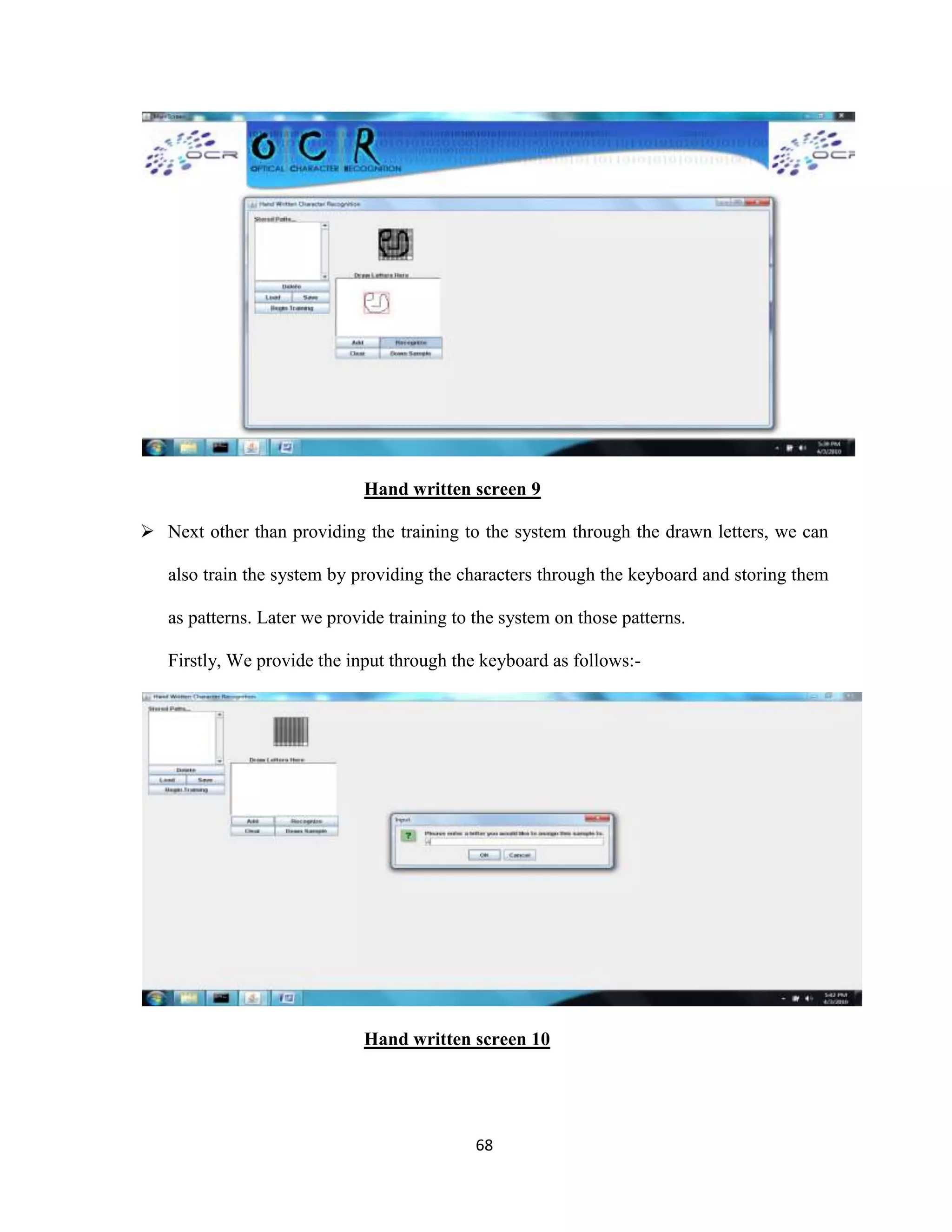

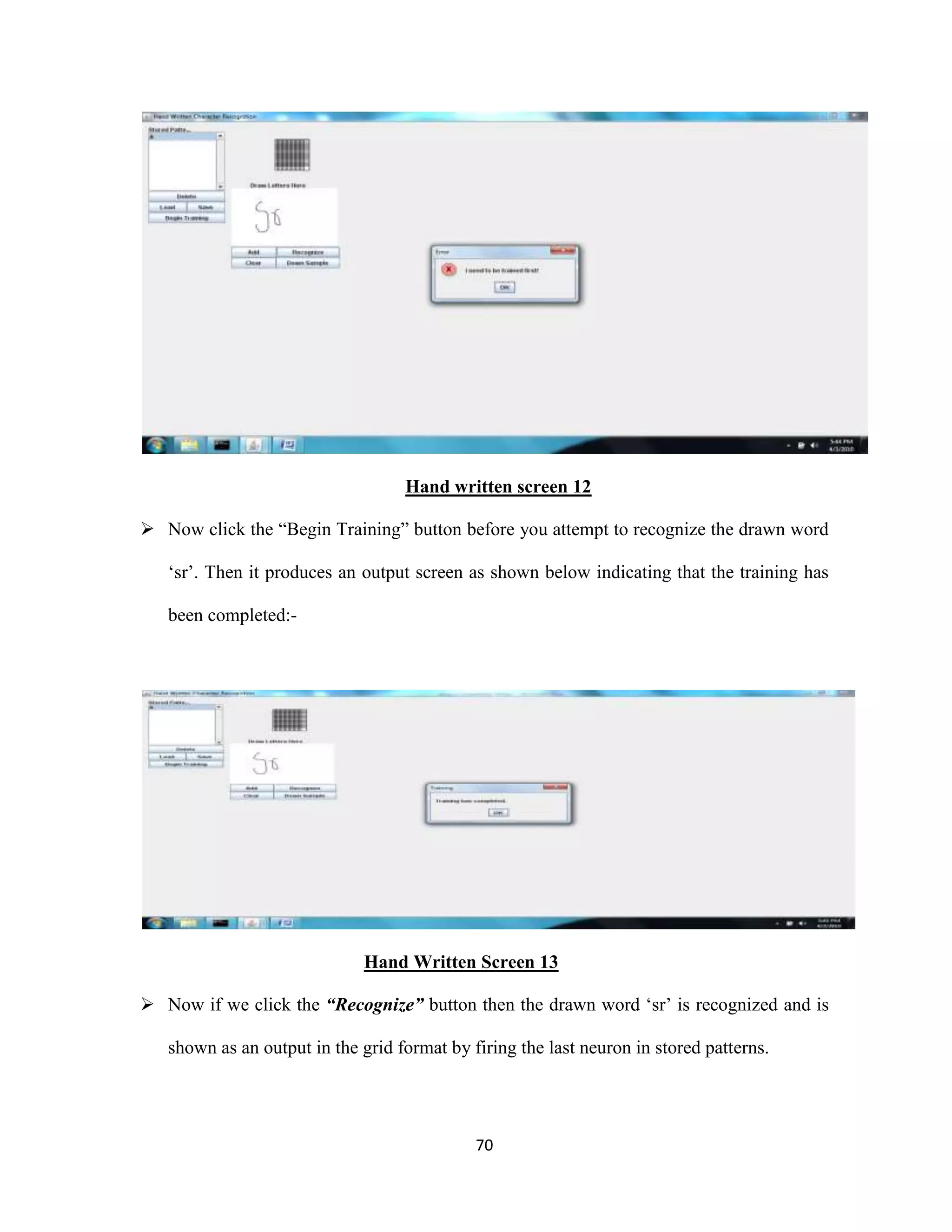
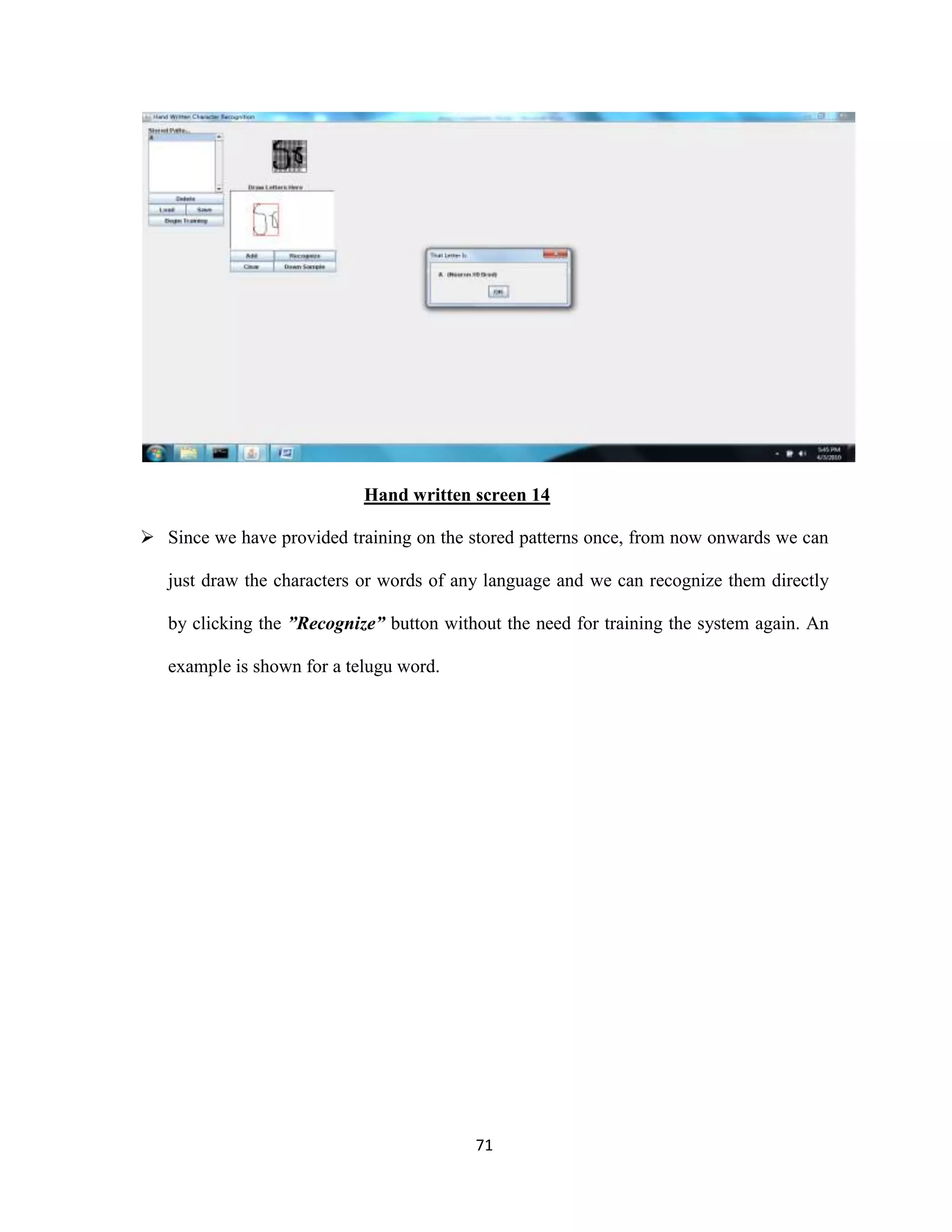
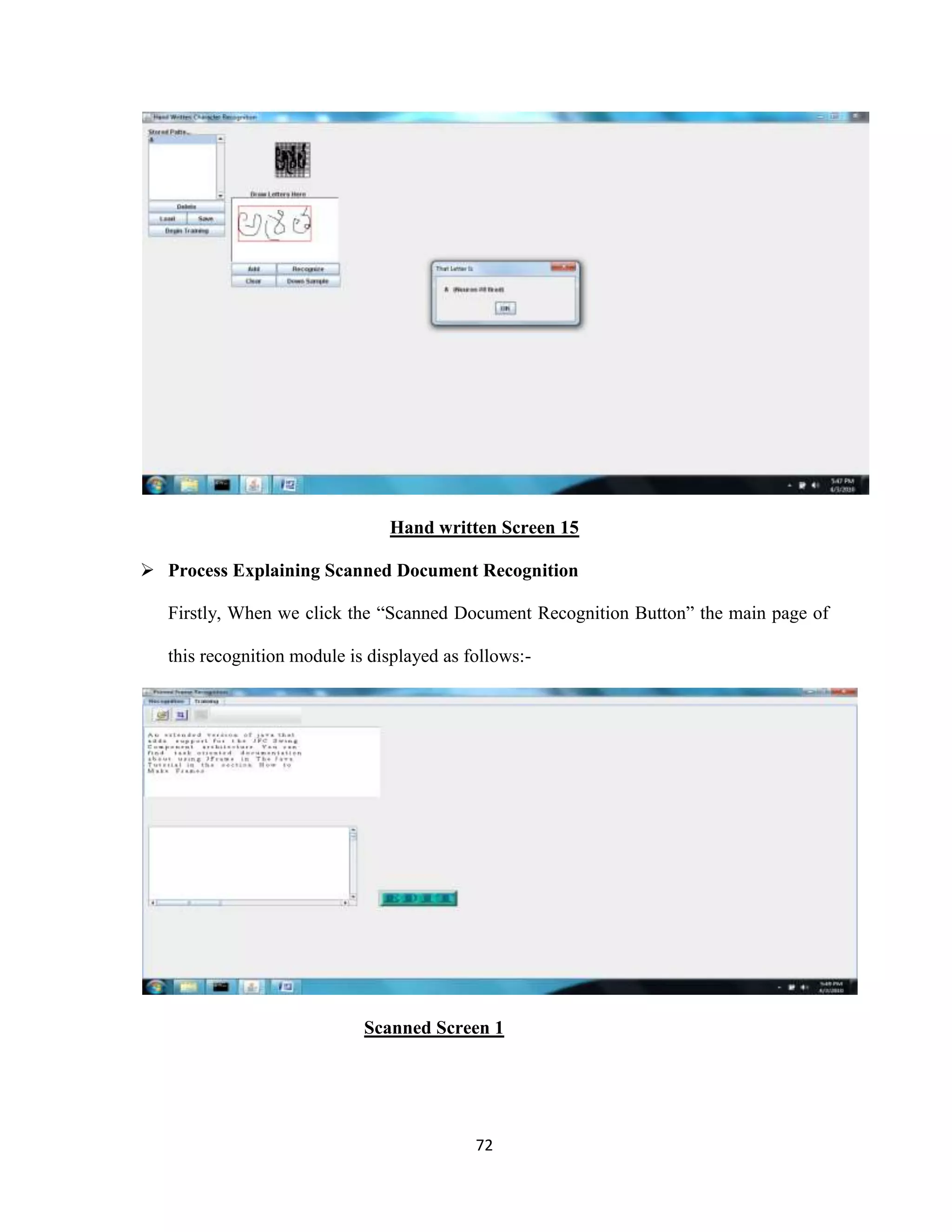
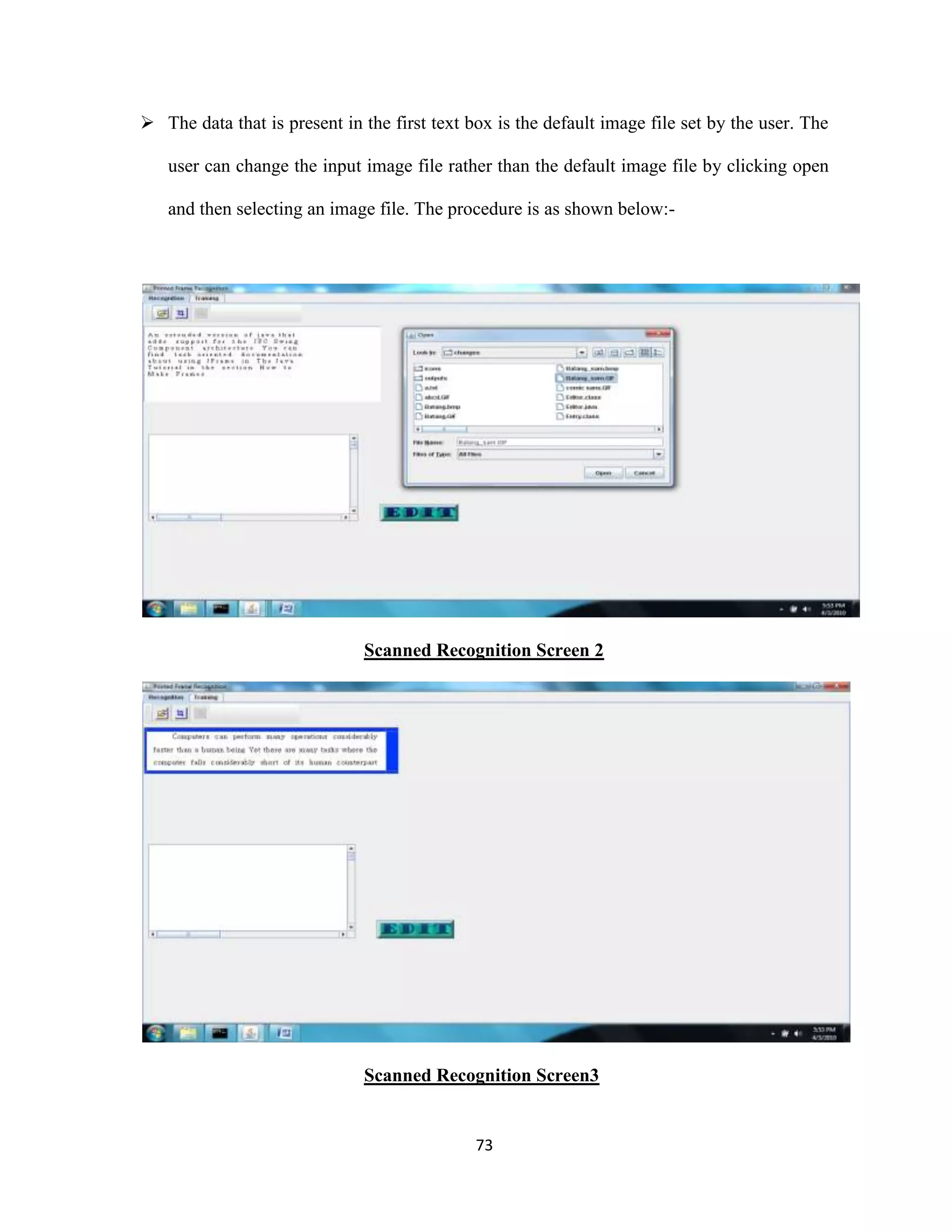

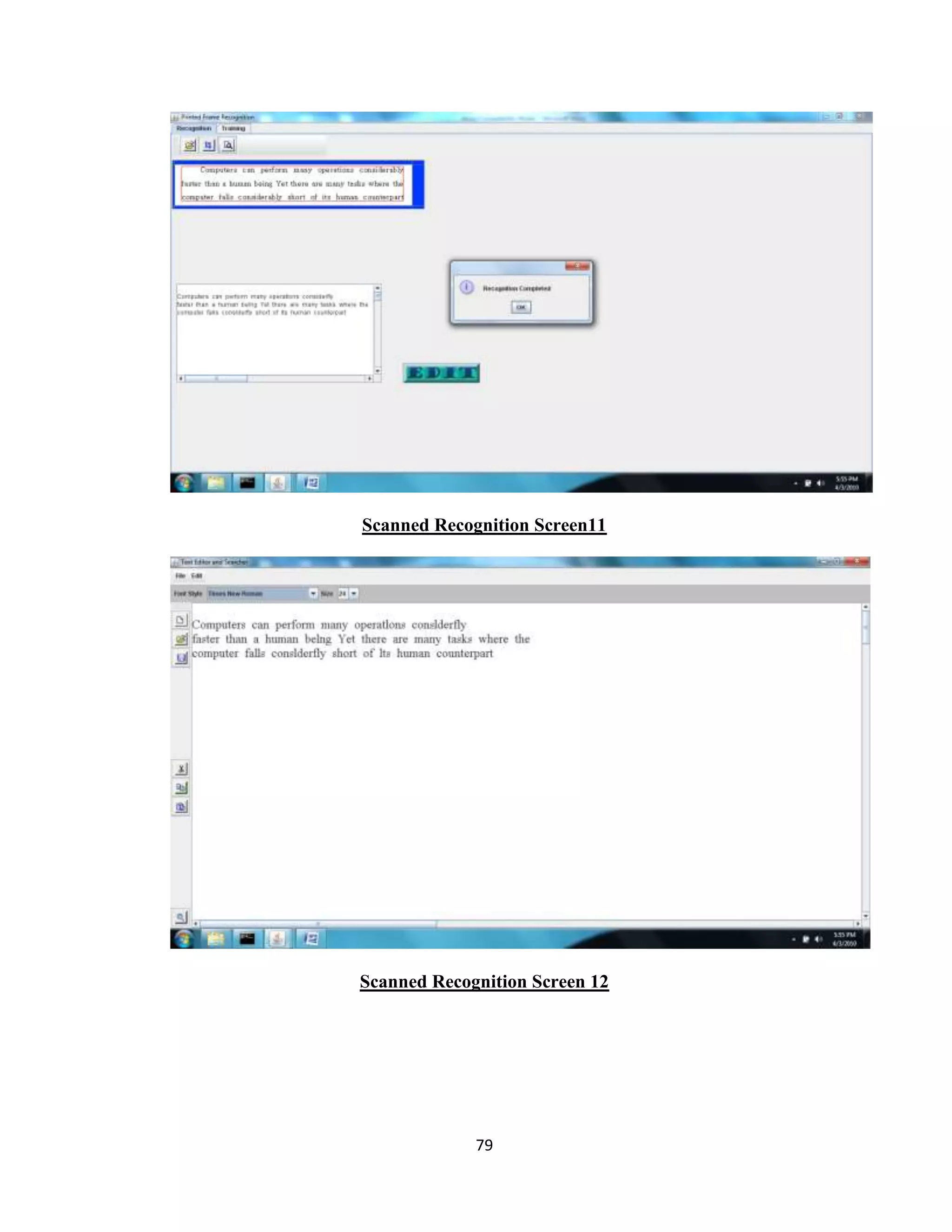
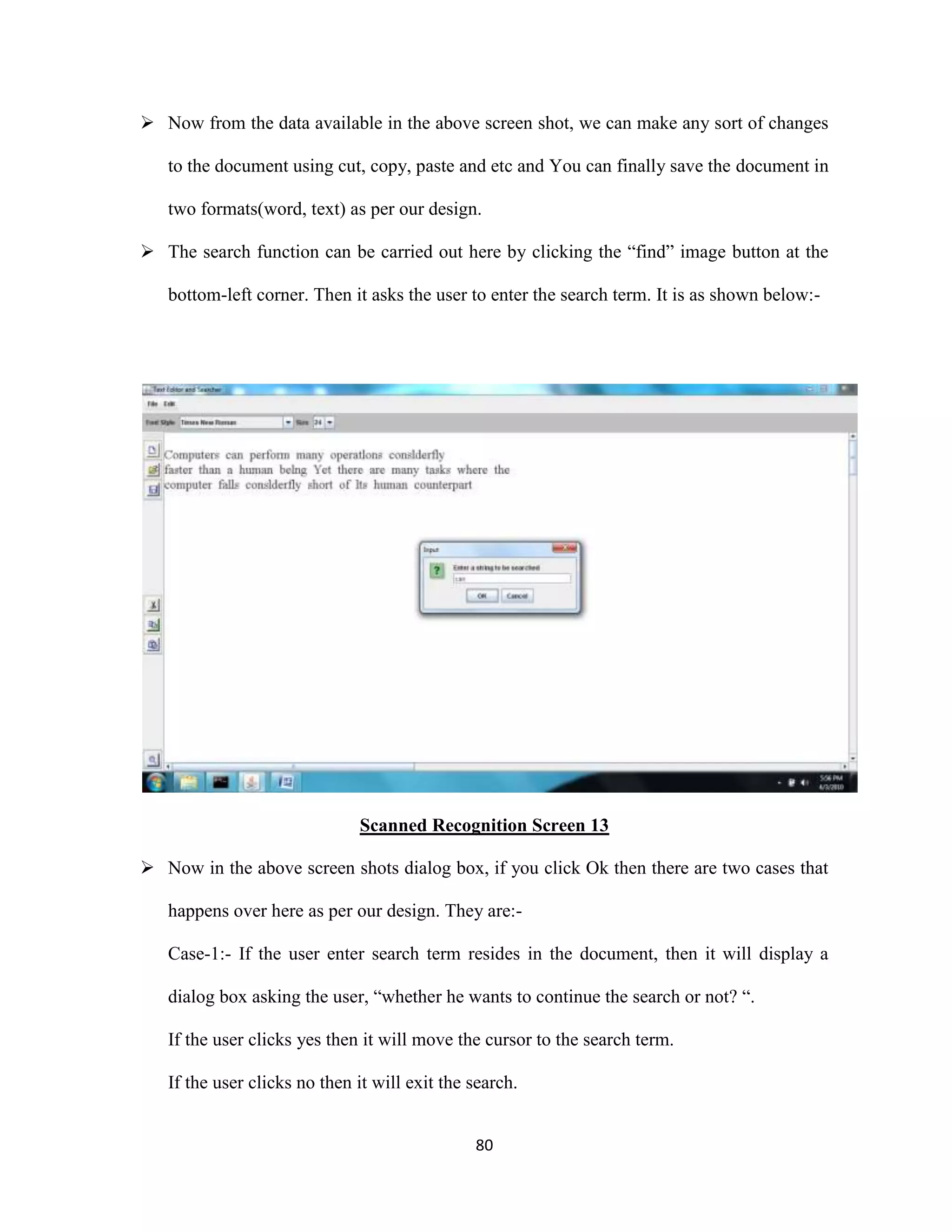
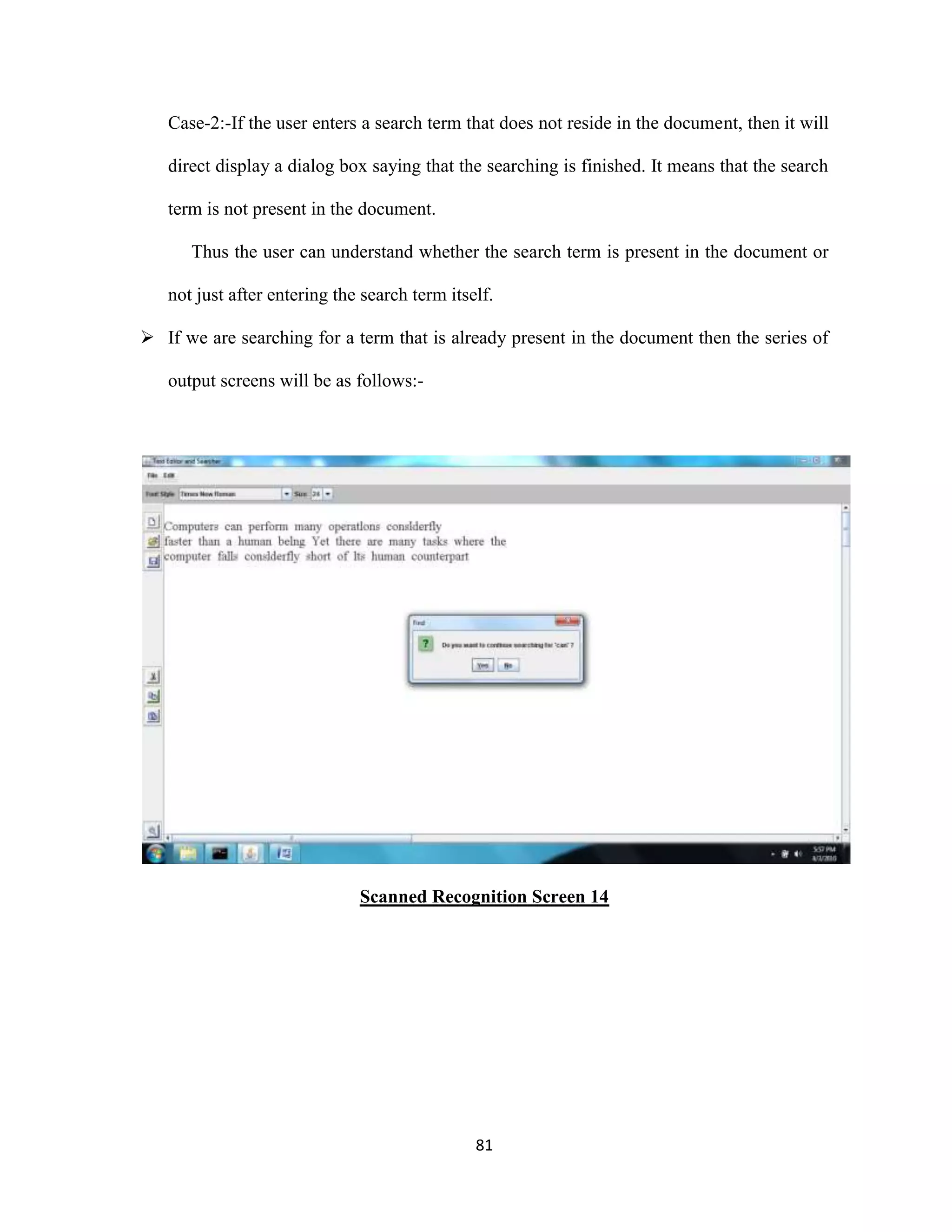
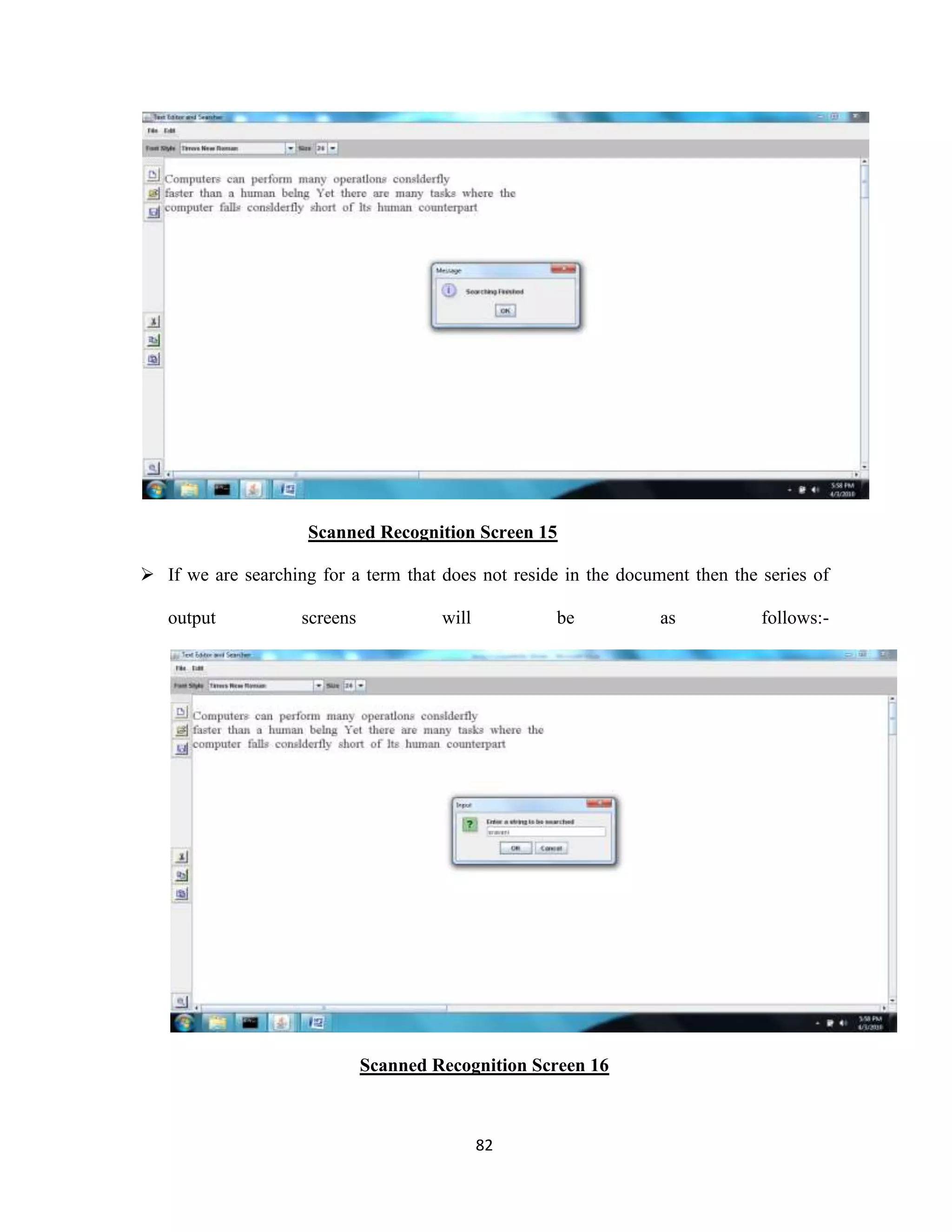
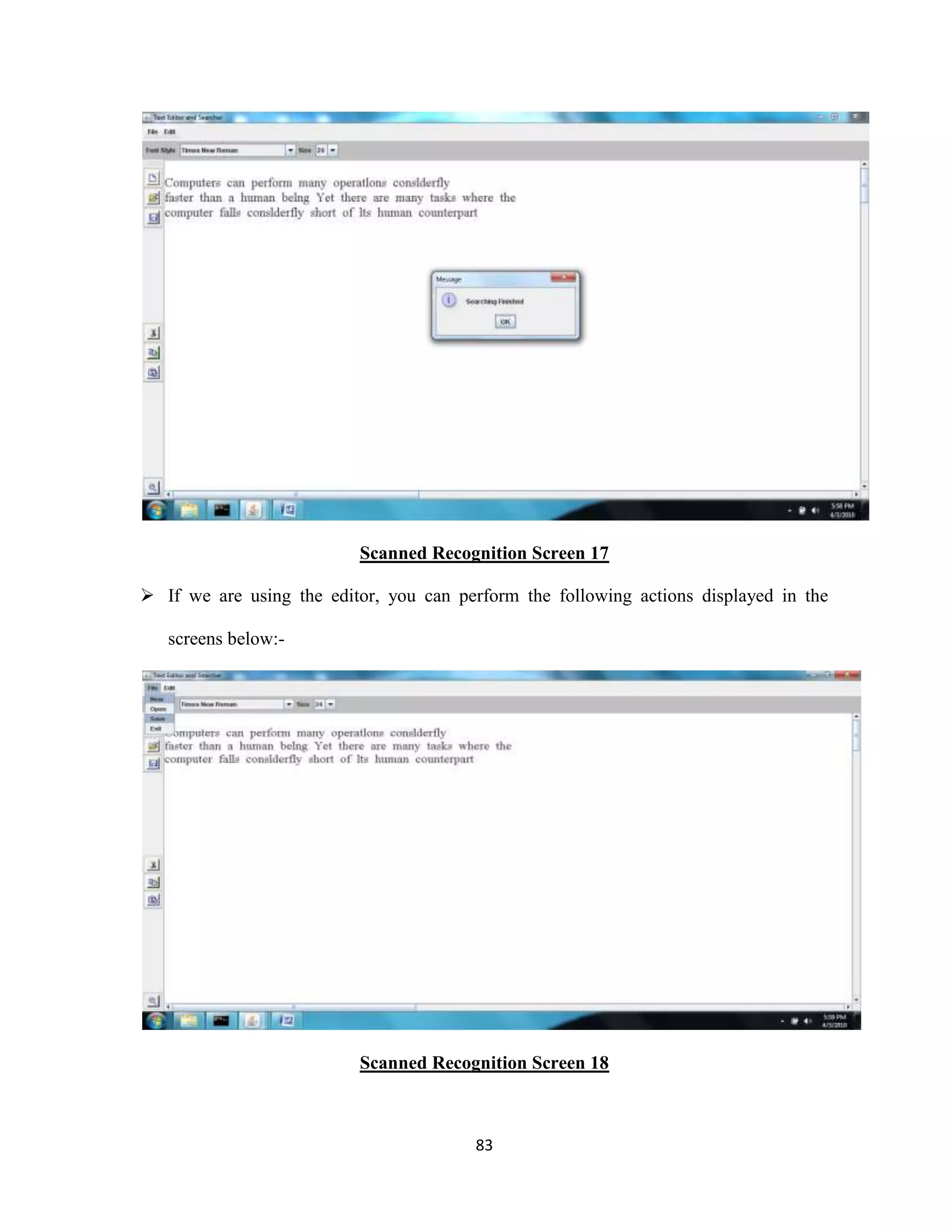






The document discusses the development of an Optical Character Recognition (OCR) system based on a grid infrastructure to improve document image analysis by recognizing characters from multiple languages efficiently. This proposed system addresses limitations of existing OCR systems, which primarily supported only a single language and lacked functionalities for searching and editing. The document outlines the technical, operational, and economic feasibility studies of this OCR system, emphasizing its benefits for research, academic, and governmental organizations.






































![Text reader [OCR]](https://cdn.slidesharecdn.com/ss_thumbnails/textreaderocr-191031162423-thumbnail.jpg?width=640&height=640&fit=bounds)






































