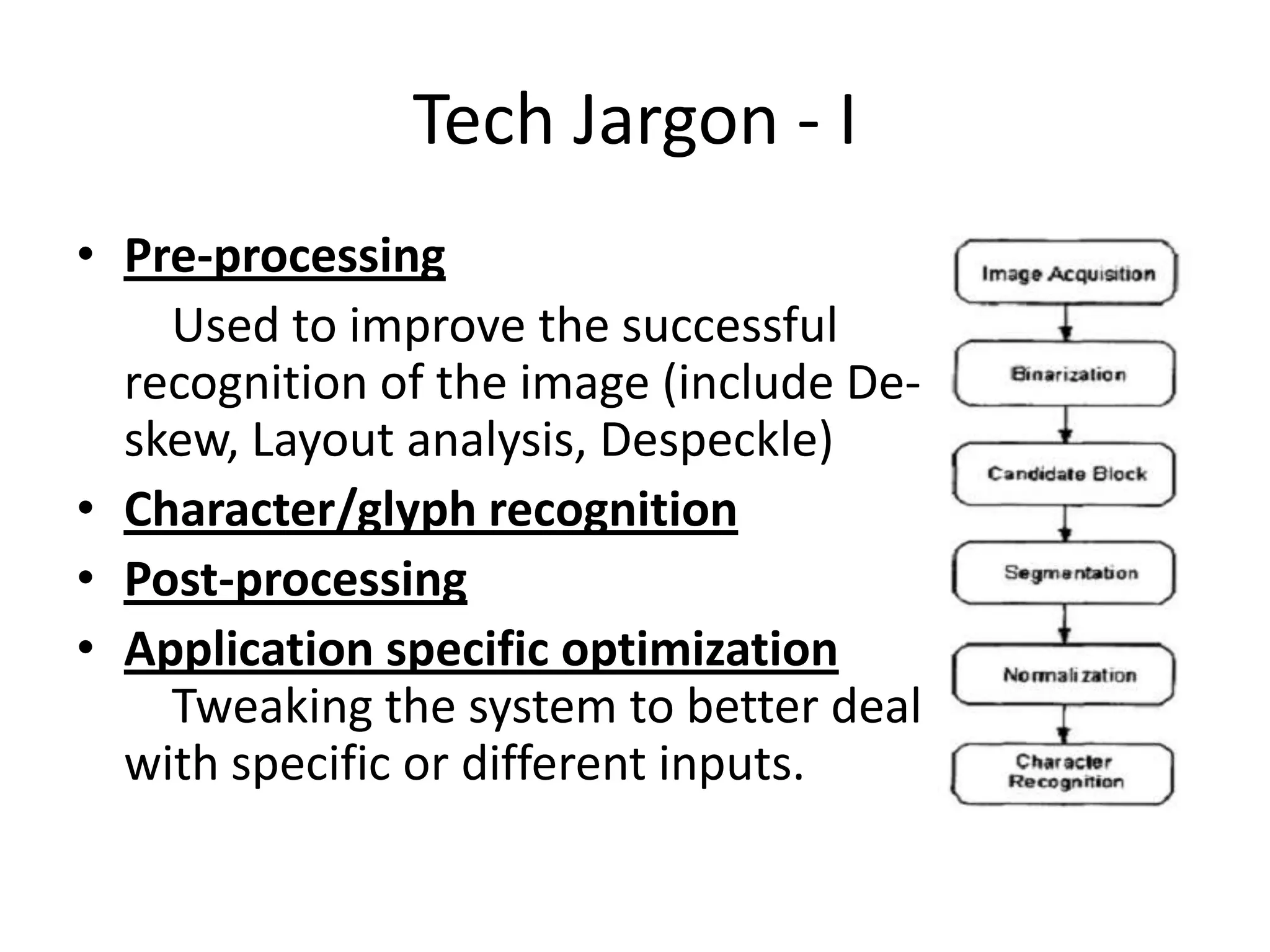
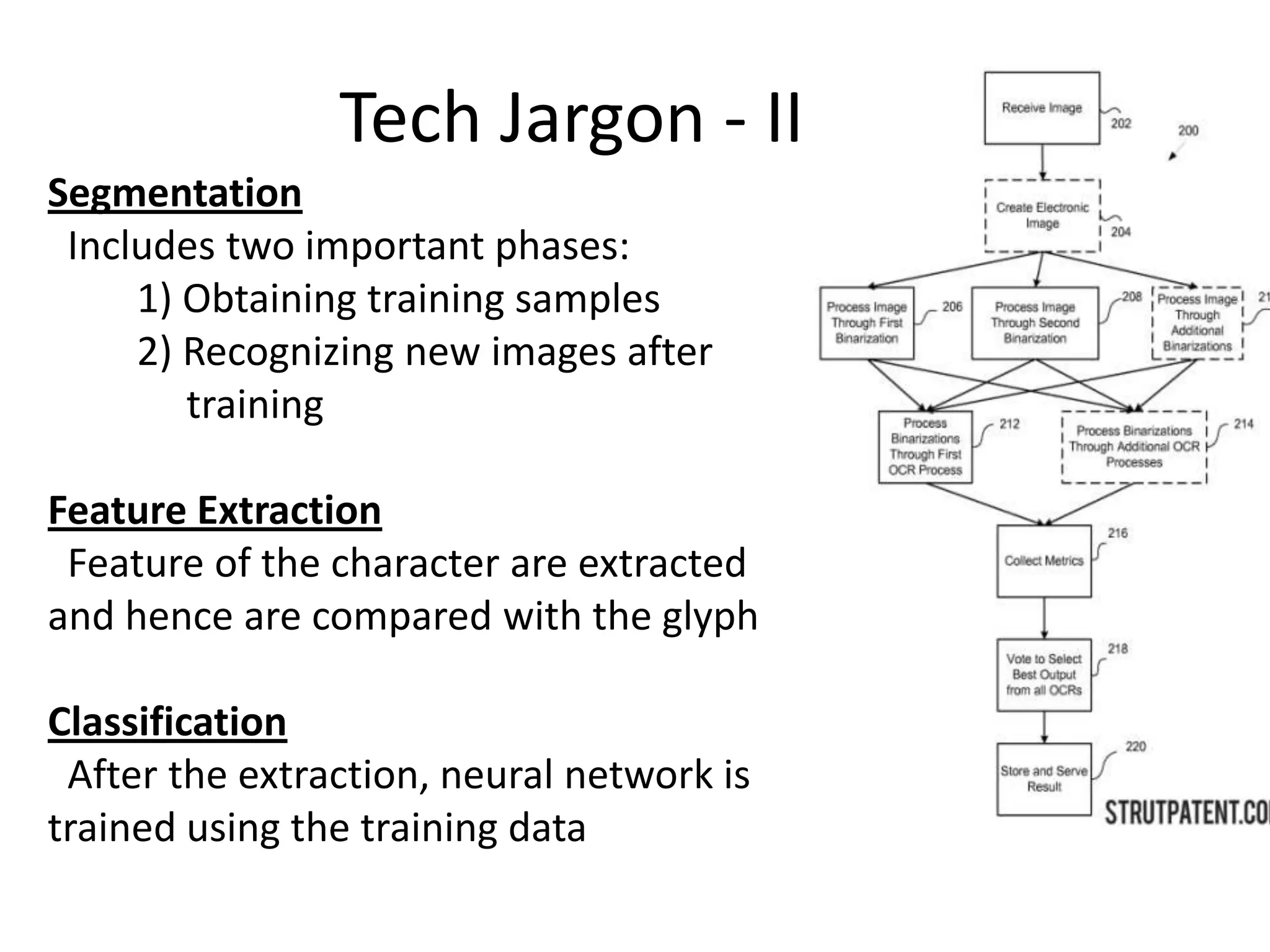
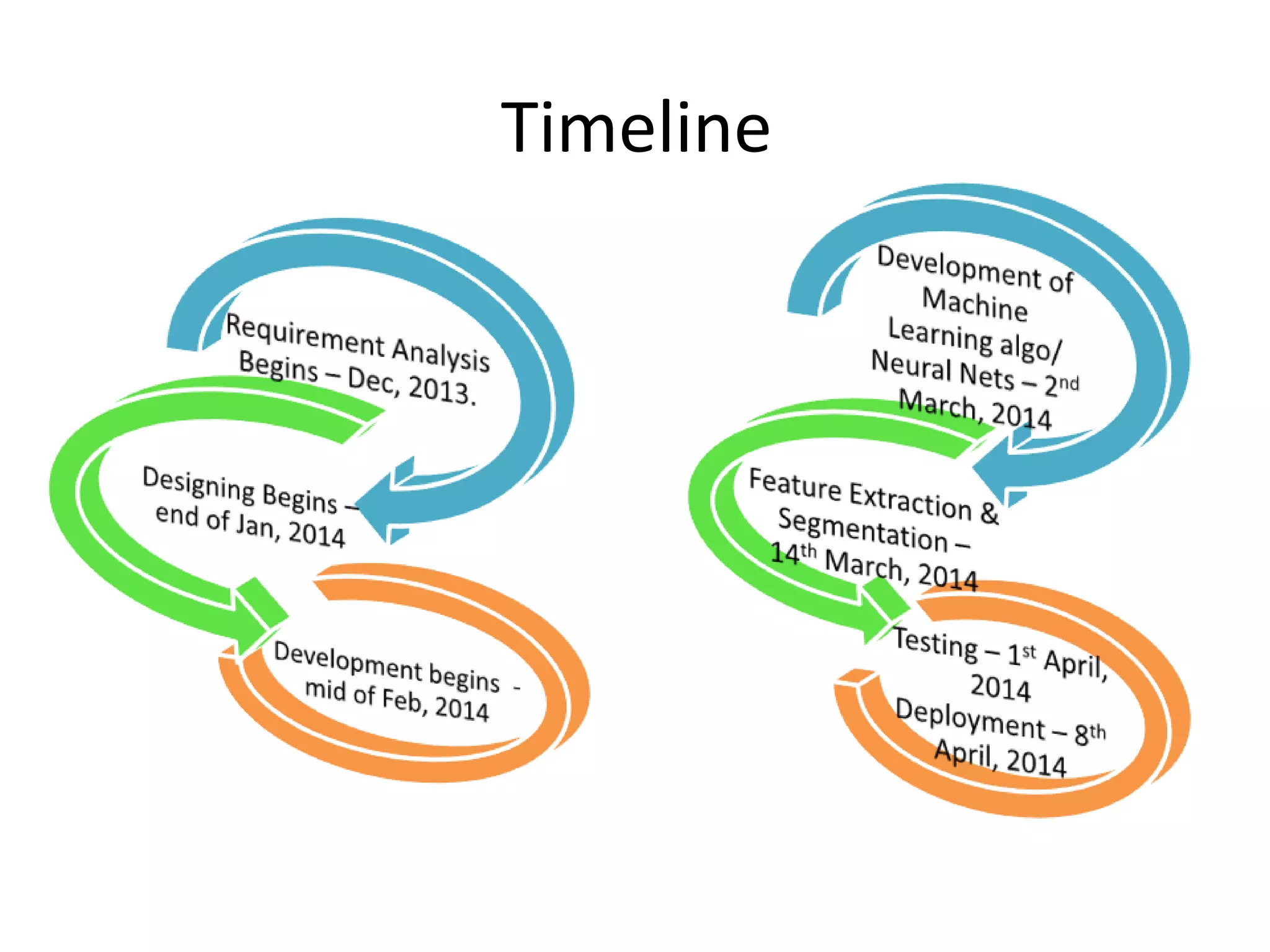
Optical Character Recognition (OCR) involves the conversion of scanned images of printed text into machine-readable text. It is heavily used in industry for applications like editing, scanning, searching, and compact storage. The document discusses developing an OCR system using machine learning, artificial intelligence, and neural networks to recognize characters despite variations in image quality, orientation, and language. It outlines the technologies, current progress implementing linear and logistic regression models, and future plans for character segmentation and feature extraction.