Downloaded 70 times


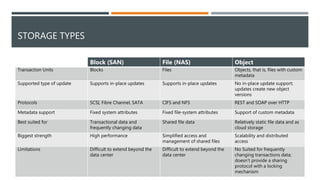








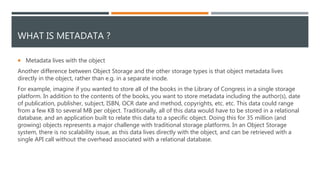

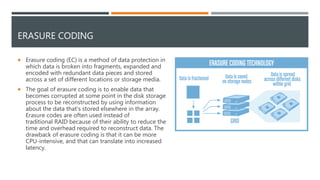
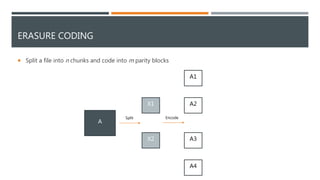
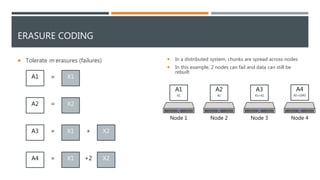
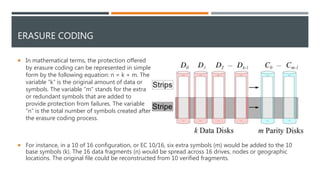


The document provides an overview of different storage types, including block, file, and object storage, detailing their definitions, characteristics, and applications. It emphasizes object storage's advantages like scalability and simplified management while also noting its limitations, such as lack of random access. Additionally, it discusses data protection methods, including RAID and erasure coding, and outlines use cases suited for object storage.












![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)