The document discusses three main storage models for big data: block-based, file-based, and object-based storage. Each model has distinct characteristics; block-based storage focuses on performance and scalability, file-based storage organizes data in a hierarchical structure for easier access, and object-based storage manages data as flexible objects with metadata. The document concludes that the choice of a storage model should depend on specific application requirements and contexts.



![Architecture
stored as blocks which normally have a fixed size yet with no additional
information (metadata). A unique identifier is used to access each block. The
identifier is mapped to the exact location of actual data blocks through access
interfaces. Traditionally, block-based storage is bound to physical storage
protocols, such as SCSI [4], iSCSI, ATA [5] and SATA [6].](https://image.slidesharecdn.com/bda141-241222035709-1aa3579c/75/Different-Storage-Models-in-Big-Data-Analytics-4-2048.jpg)
![1.2 File-Based Storage
File-based storage inherits from the traditional file system architecture, considers data as files
that are maintained in a hierarchical structure. It is the most common storage model and is
relatively easy to implement and use. In big data scenario, a file-based storage system could be
built on some other low-level abstraction (such as Block-based and Object-based model) to
improve its performance and scalability.
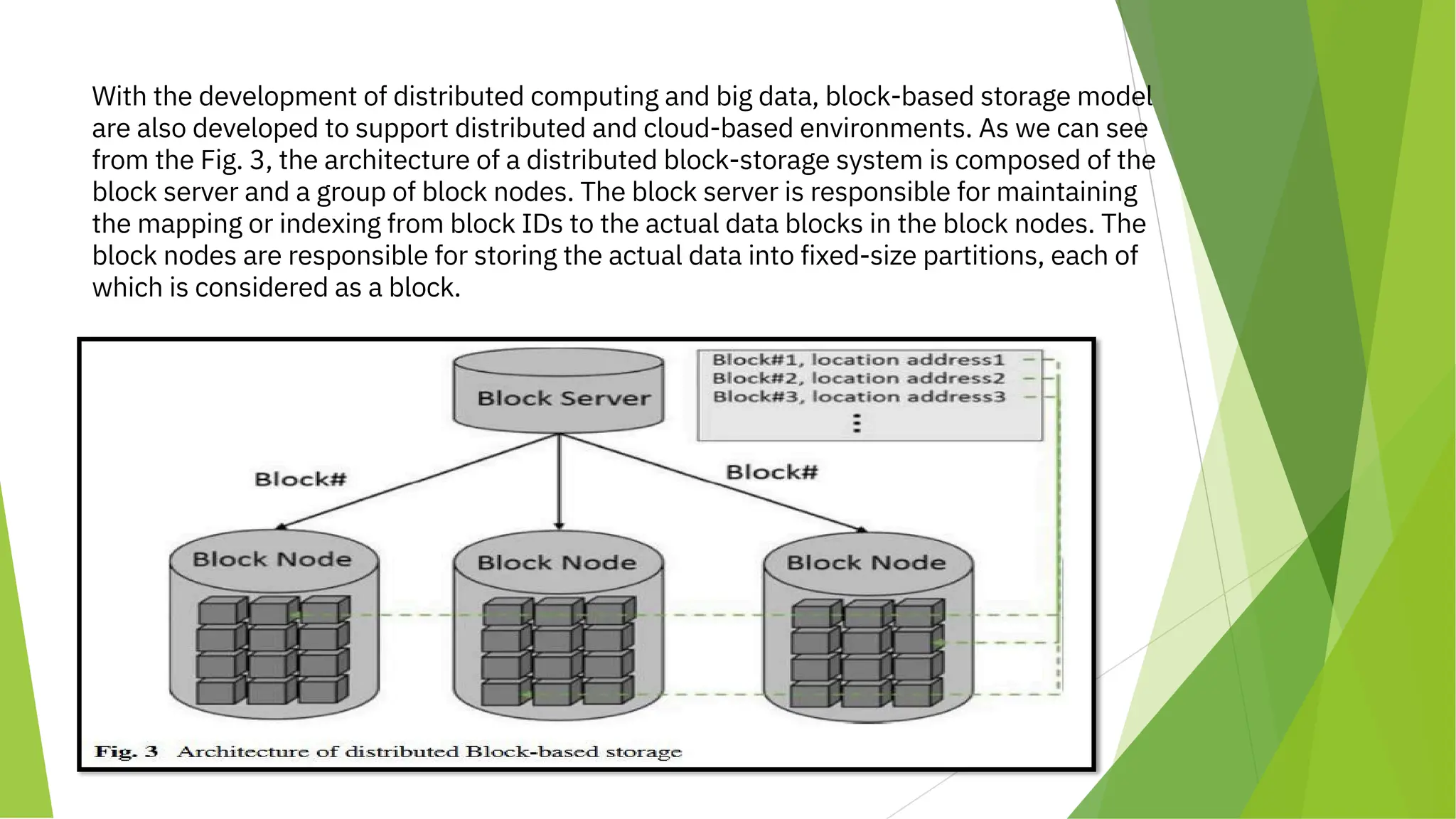
Architecture
The tile-based storage paradigm is shown in Fig. 4. File paths are organized in a hierarchy and
are used as the entries for accessing data in the physical storage. For a big data scenario,
distributed file systems (DFS) are commonly used as basic storage systems. Figure 5 shows a
typical architecture of a distributed file system which normally contains one or several name
nodes and a bunch of data nodes. The name node is responsible for maintaining the file entries
hierarchy for the entire system while the data nodes are responsible for the persistence of file
data.
In a file based system, a user would need to know of the namespaces and paths in order to
access the stored files. For sharing files across systems, the path or namespace of a file would
include three main parts: the protocol, the domain name and the path of the file. For example, a
HDFS [15] file can be indicated as: "[hdfs://][ServerAddress:ServerPort]/[FilePath]" (Fig. 6).](https://image.slidesharecdn.com/bda141-241222035709-1aa3579c/75/Different-Storage-Models-in-Big-Data-Analytics-6-2048.jpg)

![1.3 Object-Based Storage
The object-based storage model was firstly introduced on Network Attached Secure
devices [17] for providing more flexible data containers objects. For the past decade,
object-based storage has been further developed with further investments being made by
both system vendors such as EMC, HP, IBM and Redhat, ete, and cloud providers such as
Amazon, Microsoft and Google, etc. In the object-based storage model, data is managed as
objects.
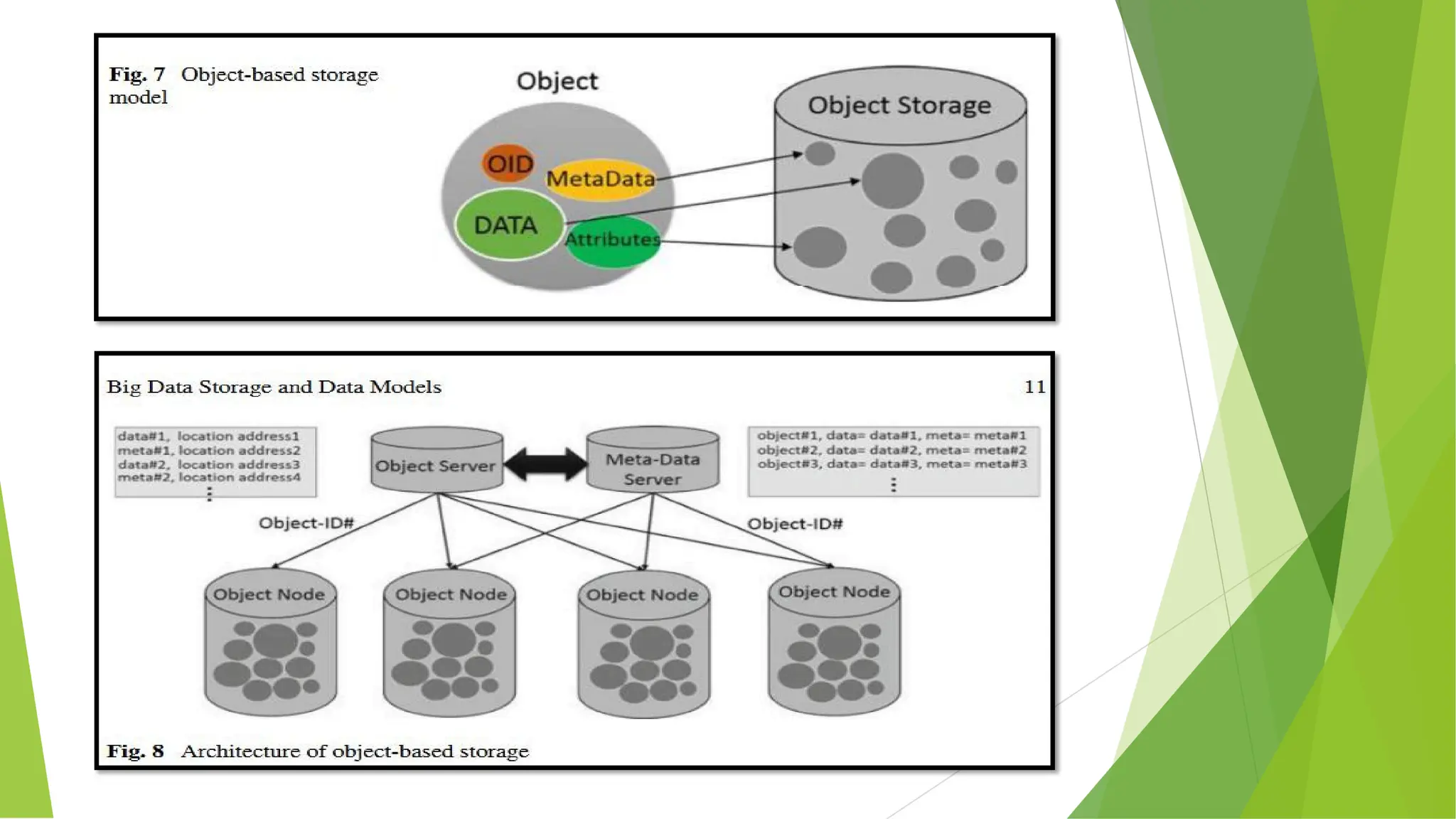
As shown in Fig. 7. every object includes the data itself, some meta-data, attributes and a
globally unique object identifier (OID). Object-based storage model abstracts the lower
layers of storage away from the administrators and applications. Object storage systems
can be implemented at different levels, including at the device level, system level and
interface level.
Data is exposed and managed as objects which includes additional descriptive meta-data
that can be used for better indexing or management. Meta-data can be anything from
security, privacy and authentication properties to any applications associated information.
](https://image.slidesharecdn.com/bda141-241222035709-1aa3579c/75/Different-Storage-Models-in-Big-Data-Analytics-9-2048.jpg)
![Architecture
The typical architecture of an object-based storage system is shown in Fig. 8. As we can see
from the figure, the object-based storage system normally uses a flat namespace, in which the
identifier of data and their locations are usually maintained as key-value pairs in the object
server. In principle, the object server provides location-independent addressing and constant
lookup latency for reading every object. In addition, meta-data of the data is separated from
data and is also maintained as objects in a meta-data server (might be co-located with the
object server).
As a result, it provides a standard and easier way of processing, analyzing and manipulating
of the meta-data without affecting the data itself. Due to the flat architecture, it is very easy to
scale out object-based storage systems by adding additional storage nodes to the system.
Besides, the added storage can be automatically expanded as capacity that is available for all
users. Drawing on the object container and meta-data maintained, it is also able to provide
much more flexible and line-grained data policies at different levels, for example, Amazon S3
[18] provides bucket level policy. Azure (19) provides storage account level policy, Atmos
[20] provides per-object policy.](https://image.slidesharecdn.com/bda141-241222035709-1aa3579c/75/Different-Storage-Models-in-Big-Data-Analytics-11-2048.jpg)

















































