Downloaded 13 times




![concurrentKernels.exe
[C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥concurrentKernels.exe] - Starting...
GPU Device 0: "GeForce GTX 560 Ti" with compute capability 2.1
> Detected Compute SM 2.1 hardware with 8 multi-processors
Expected time for serial execution of 8 kernels = 0.080s
Expected time for concurrent execution of 8 kernels = 0.010s
Measured time for sample = 0.010s
Test passed](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-4-320.jpg)

![convolutionFFT2D.exe 1/2
[C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥convolutionFFT2D.exe] - Starting...
GPU Device 0: "GeForce GTX 560 Ti" with compute capability 2.1
Testing built-in R2C / C2R FFT-based convolution
...allocating memory
...generating random input data
...creating R2C & C2R FFT plans for 2048 x 2048
...uploading to GPU and padding convolution kernel and input data
...transforming convolution kernel
...running GPU FFT convolution: 1267.922657 MPix/s (3.154767 ms)
...reading back GPU convolution results
...running reference CPU convolution
...comparing the results: rel L2 = 7.179421E-008 (max delta = 4.808732E-007)
L2norm Error OK
...shutting down
Testing custom R2C / C2R FFT-based convolution
...allocating memory
...generating random input data
...creating C2C FFT plan for 2048 x 1024
...uploading to GPU and padding convolution kernel and input data
...transforming convolution kernel
...running GPU FFT convolution: 1261.058719 MPix/s (3.171938 ms)
...reading back GPU FFT results
...running reference CPU convolution
...comparing the results: rel L2 = 7.505000E-008 (max delta = 4.873593E-007)
L2norm Error OK
...shutting down](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-7-320.jpg)

![convolutionSeparable.exe
[C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥convolutionSeparable.exe] -
Starting...
GPU Device 0: "GeForce GTX 560 Ti" with compute capability 2.1
Image Width x Height = 3072 x 3072
Allocating and initializing host arrays...
Allocating and initializing CUDA arrays...
Running GPU convolution (16 identical iterations)...
convolutionSeparable, Throughput = 3179.0263 MPixels/sec, Time = 0.00297 s, Size = 9437184 Pixels,
NumDevsUsed = 1, Work
group = 0
Reading back GPU results...
Checking the results...
...running convolutionRowCPU()
...running convolutionColumnCPU()
...comparing the results
...Relative L2 norm: 0.000000E+000
Shutting down...
Test passed](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-9-320.jpg)
![convolutionTexture.exe
[C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥convolutionTexture.exe] - Starting...
GPU Device 0: "GeForce GTX 560 Ti" with compute capability 2.1
Initializing data...
Running GPU rows convolution (10 identical iterations)...
Average convolutionRowsGPU() time: 1.427774 msecs; //3304.859282 Mpix/s
Copying convolutionRowGPU() output back to the texture...
cudaMemcpyToArray() time: 0.481161 msecs; //9806.674660 Mpix/s
Running GPU columns convolution (10 iterations)
Average convolutionColumnsGPU() time: 1.429637 msecs; //3300.552071 Mpix/s
Reading back GPU results...
Checking the results...
...running convolutionRowsCPU()
...running convolutionColumnsCPU()
Relative L2 norm: 0.000000E+000
Shutting down...
Test passed](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-10-320.jpg)

![cudaDecodeD3D9.exe (runaway)
Command Line Arguments:
argv[0] = C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥cudaDecodeD3D9.exe](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-12-320.jpg)
![cudaDecodeGL.exe 1/2
[CUDA/OpenGL Video Decode]
Command Line Arguments:
argv[0] = C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥cudaDecodeGL.exe
[cudaDecodeGL]: input file: <../../../3_Imaging/cudaDecodeGL/data/plush1_720p_10s.m2v>
VideoCodec : MPEG-2
Frame rate : 30000/1001fps ~ 29.97fps
Sequence format : Progressive
Coded frame size: [1280, 720]
Display area : [0, 0, 1280, 720]
Chroma format : 4:2:0
Bitrate : 14116kBit/s
Aspect ratio : 16:9
argv[0] = C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥cudaDecodeGL.exe
> Device 0: <GeForce GTX 560 Ti >, Compute SM 2.1 detected
-> GPU 0: < GeForce GTX 560 Ti > driver mode is: WDDM
>> initGL() creating window [1280 x 720]
> Using CUDA/GL Device [0]: GeForce GTX 560 Ti
> Using GPU Device: GeForce GTX 560 Ti has SM 2.1 compute capability
Total amount of global memory: 1024.0000 MB
>> modInitCTX<NV12ToARGB_drvapi_x64.ptx > initialized OK
>> modGetCudaFunction< CUDA file: NV12ToARGB_drvapi_x64.ptx >
CUDA Kernel Function (0x0a4c6660) = < NV12ToARGB_drvapi >
>> modGetCudaFunction< CUDA file: NV12ToARGB_drvapi_x64.ptx >
CUDA Kernel Function (0x0a4c6210) = < Passthru_drvapi >
> VideoDecoder::cudaVideoCreateFlags = <1>Use CUDA decoder](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-13-320.jpg)
![cudaDecodeGL.exe 2/2
setTextureFilterMode(GL_NEAREST,GL_NEAREST)
ImageGL::CUcontext = 02047fd0
ImageGL::CUdevice = 00000000
reshape() glViewport(0, 0, 1280, 720)
[cudaDecodeGL] - [Frame: 0016, 00.0 fps, frame time: 98854.47 (ms) ]
[cudaDecodeGL] - [Frame: 0032, 736.9 fps, frame time: 1.36 (ms) ]
[cudaDecodeGL] - [Frame: 0048, 687.3 fps, frame time: 1.45 (ms) ]
[cudaDecodeGL] - [Frame: 0064, 788.9 fps, frame time: 1.27 (ms) ]
[cudaDecodeGL] - [Frame: 0080, 748.5 fps, frame time: 1.34 (ms) ]
[cudaDecodeGL] - [Frame: 0096, 724.5 fps, frame time: 1.38 (ms) ]
[cudaDecodeGL] - [Frame: 0112, 747.5 fps, frame time: 1.34 (ms) ]
[cudaDecodeGL] - [Frame: 0128, 738.9 fps, frame time: 1.35 (ms) ]
[cudaDecodeGL] - [Frame: 0144, 749.4 fps, frame time: 1.33 (ms) ]
[cudaDecodeGL] - [Frame: 0160, 764.7 fps, frame time: 1.31 (ms) ]
[cudaDecodeGL] - [Frame: 0176, 802.6 fps, frame time: 1.25 (ms) ]
[cudaDecodeGL] - [Frame: 0192, 766.6 fps, frame time: 1.30 (ms) ]
[cudaDecodeGL] - [Frame: 0208, 827.8 fps, frame time: 1.21 (ms) ]
[cudaDecodeGL] - [Frame: 0224, 774.1 fps, frame time: 1.29 (ms) ]
[cudaDecodeGL] - [Frame: 0240, 793.3 fps, frame time: 1.26 (ms) ]
[cudaDecodeGL] - [Frame: 0256, 742.5 fps, frame time: 1.35 (ms) ]
[cudaDecodeGL] - [Frame: 0272, 789.0 fps, frame time: 1.27 (ms) ]
[cudaDecodeGL] - [Frame: 0288, 803.1 fps, frame time: 1.25 (ms) ]
[cudaDecodeGL] - [Frame: 0304, 723.6 fps, frame time: 1.38 (ms) ]
[cudaDecodeGL] - [Frame: 0320, 728.5 fps, frame time: 1.37 (ms) ]
[cudaDecodeGL] statistics
Video Length (hh:mm:ss.msec) = 00:00:00.440
Frames Presented (inc repeats) = 326
Average Present Rate (fps) = 739.44
Frames Decoded (hardware) = 327
Average Rate of Decoding (fps) = 741.71](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-14-320.jpg)
![cudaDecodeD3D9.exe 1/2
Command Line Arguments:
argv[0] = C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥cudaDecodeD3D9.exe
[cudaDecodeD3D9]: input file: <../../../3_Imaging/cudaDecodeD3D9/data/plush1_720p_10s.m2v>
VideoCodec : MPEG-2
Frame rate : 30000/1001fps ~ 29.97fps
Sequence format : Progressive
Coded frame size: [1280, 720]
Display area : [0, 0, 1280, 720]
Chroma format : 4:2:0
Bitrate : 14116kBit/s
Aspect ratio : 16:9
> Using GPU Device 0: GeForce GTX 560 Ti has SM 2.1 compute capability
Total amount of global memory: 1024.0000 MB
>> modInitCTX<NV12ToARGB_drvapi_x64.ptx> initialized SUCCESS!
>> modGetCudaFunction<NV12ToARGB_drvapi_x64.ptx>
CUDA Kernel Function = <NV12ToARGB_drvapi, 0x04439d20>
>> modGetCudaFunction<NV12ToARGB_drvapi_x64.ptx>
CUDA Kernel Function = <Passthru_drvapi, 0x044398d0>
> VideoDecoder::cudaVideoCreateFlags = <1>Use CUDA decoder](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-15-320.jpg)
![cudaDecodeD3D9.exe 2/2
[cudaDecodeD3D9] - [Frame: 0016, 833.6 fps, time: 1.20 (ms) ]
[cudaDecodeD3D9] - [Frame: 0032, 1031.0 fps, time: 0.97 (ms) ]
[cudaDecodeD3D9] - [Frame: 0048, 843.8 fps, time: 1.19 (ms) ]
[cudaDecodeD3D9] - [Frame: 0064, 864.4 fps, time: 1.16 (ms) ]
[cudaDecodeD3D9] - [Frame: 0080, 850.9 fps, time: 1.18 (ms) ]
[cudaDecodeD3D9] - [Frame: 0096, 819.0 fps, time: 1.22 (ms) ]
[cudaDecodeD3D9] - [Frame: 0112, 844.0 fps, time: 1.18 (ms) ]
[cudaDecodeD3D9] - [Frame: 0128, 815.6 fps, time: 1.23 (ms) ]
[cudaDecodeD3D9] - [Frame: 0144, 821.0 fps, time: 1.22 (ms) ]
[cudaDecodeD3D9] - [Frame: 0160, 874.7 fps, time: 1.14 (ms) ]
[cudaDecodeD3D9] - [Frame: 0176, 960.4 fps, time: 1.04 (ms) ]
[cudaDecodeD3D9] - [Frame: 0192, 947.7 fps, time: 1.06 (ms) ]
[cudaDecodeD3D9] - [Frame: 0208, 896.7 fps, time: 1.12 (ms) ]
[cudaDecodeD3D9] - [Frame: 0224, 872.5 fps, time: 1.15 (ms) ]
[cudaDecodeD3D9] - [Frame: 0240, 922.7 fps, time: 1.08 (ms) ]
[cudaDecodeD3D9] - [Frame: 0256, 943.2 fps, time: 1.06 (ms) ]
[cudaDecodeD3D9] - [Frame: 0272, 936.6 fps, time: 1.07 (ms) ]
[cudaDecodeD3D9] - [Frame: 0288, 899.8 fps, time: 1.11 (ms) ]
[cudaDecodeD3D9] - [Frame: 0304, 901.0 fps, time: 1.11 (ms) ]
[cudaDecodeD3D9] - [Frame: 0320, 813.1 fps, time: 1.23 (ms) ]
[cudaDecodeD3D9] statistics
Video Length (hh:mm:ss.msec) = 00:00:00.375
Frames Presented (inc repeats) = 326
Average Present FPS = 868.73
Frames Decoded (hardware) = 327
Average Decoder FPS = 871.40](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-16-320.jpg)
![cudaEncode.exe (runaway)
Starting cudaEncode...
[ CUDA H.264 Encoder ]
argv[0] = C:¥ProgramData¥NVIDIA Corporation¥CUDA Samples¥v5.0¥bin¥win64¥Release¥cudaEncode.exe](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-17-320.jpg)
![dct8x8.exe
dct8x8.exe Starting...
GPU Device 0: "GeForce GTX 560 Ti" with compute capability 2.1
CUDA sample DCT/IDCT implementation
===================================
Loading test image: barbara.bmp... [512 x 512]... Success
Running Gold 1 (CPU) version... Success
Running Gold 2 (CPU) version... Success
Running CUDA 1 (GPU) version... Success
Running CUDA 2 (GPU) version... 10459.499992 MPix/s //0.025063 ms
Success
Running CUDA short (GPU) version... Success
Dumping result to barbara_gold1.bmp... Success
Dumping result to barbara_gold2.bmp... Success
Dumping result to barbara_cuda1.bmp... Success
Dumping result to barbara_cuda2.bmp... Success
Dumping result to barbara_cuda_short.bmp... Success
Processing time (CUDA 1) : 0.209782 ms
Processing time (CUDA 2) : 0.025063 ms
Processing time (CUDA short): 0.170617 ms
PSNR Original <---> CPU(Gold 1) : 32.777073
PSNR Original <---> CPU(Gold 2) : 32.777046
PSNR Original <---> GPU(CUDA 1) : 32.777092
PSNR Original <---> GPU(CUDA 2) : 32.777077
PSNR Original <---> GPU(CUDA short): 32.749447
PSNR CPU(Gold 1) <---> GPU(CUDA 1) : 64.019310
PSNR CPU(Gold 2) <---> GPU(CUDA 2) : 71.777740
PSNR CPU(Gold 2) <---> GPU(CUDA short): 42.258053
Test Summary...
Test passed](https://image.slidesharecdn.com/nvidiacuda5sampleevaluationresult2-130423111513-phpapp02/85/Nvidia-cuda-5-sample-evaluationresult_2-18-320.jpg)










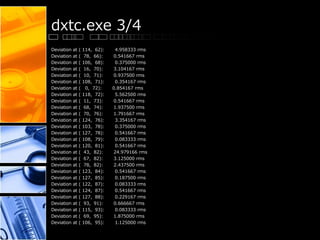
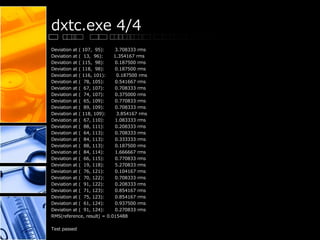


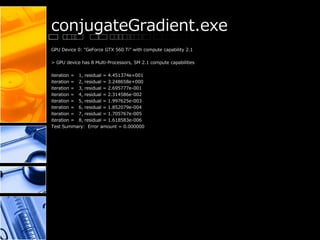
This document provides performance results for various CUDA samples programs using an NVIDIA GeForce GTX 560 Ti GPU. It tests programs for concurrent kernels, conjugate gradient, convolution using FFTs, separable convolution, CUDA integration with C++ and decoding video to OpenGL and DirectX. Frame rates for video decoding ranged from 723-1031 fps. Convolution tests showed throughput of up to 1588 MPix/s. Conjugate gradient achieved convergence within 8 iterations.










































![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[03 2][gpu용 개발자 도구 - parallel nsight 및 axe] gateau parallel-nsight](https://cdn.slidesharecdn.com/ss_thumbnails/03-2gpu-parallelnsightaxegateauparallelnsight-110106231414-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















































