Download to read offline







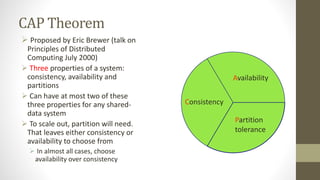
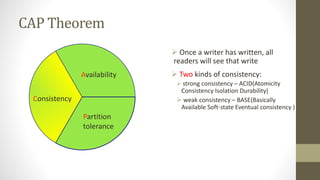
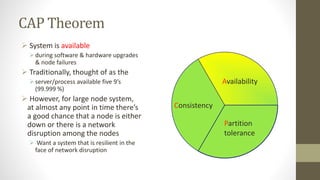
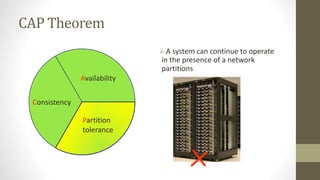
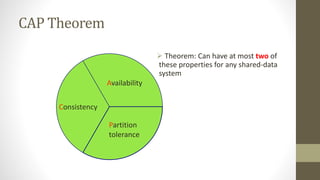
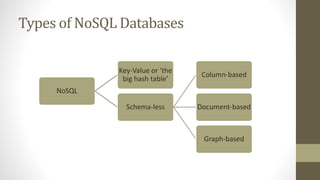



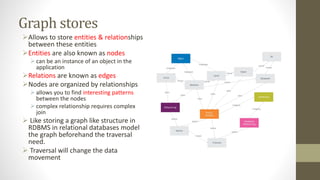
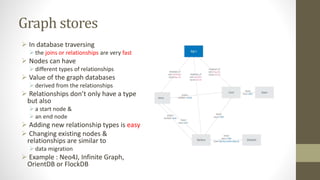

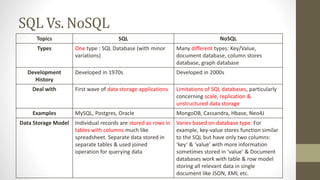
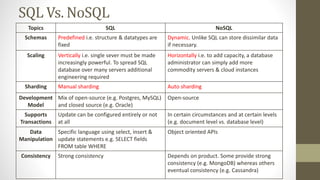






NoSQL databases are non-relational data storage systems that are designed for large volumes of data across many servers. They are schema-less, support document or key-value data models, and are distributed, open source, and designed for scalability. Common types include key-value stores, document databases, column-family stores, and graph databases. NoSQL databases sacrifice consistency guarantees and transactions for horizontal scalability and high availability.


















































































