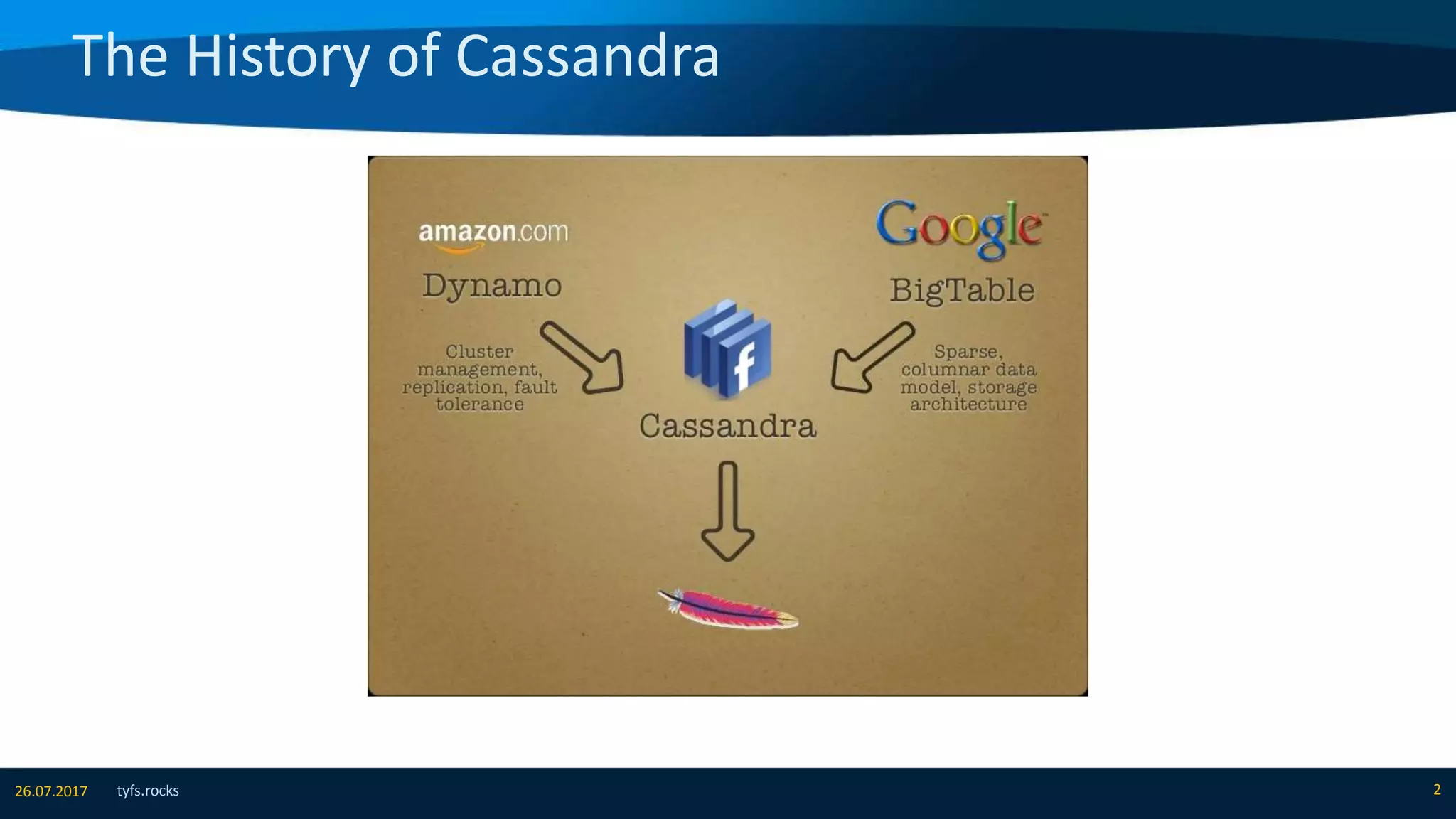
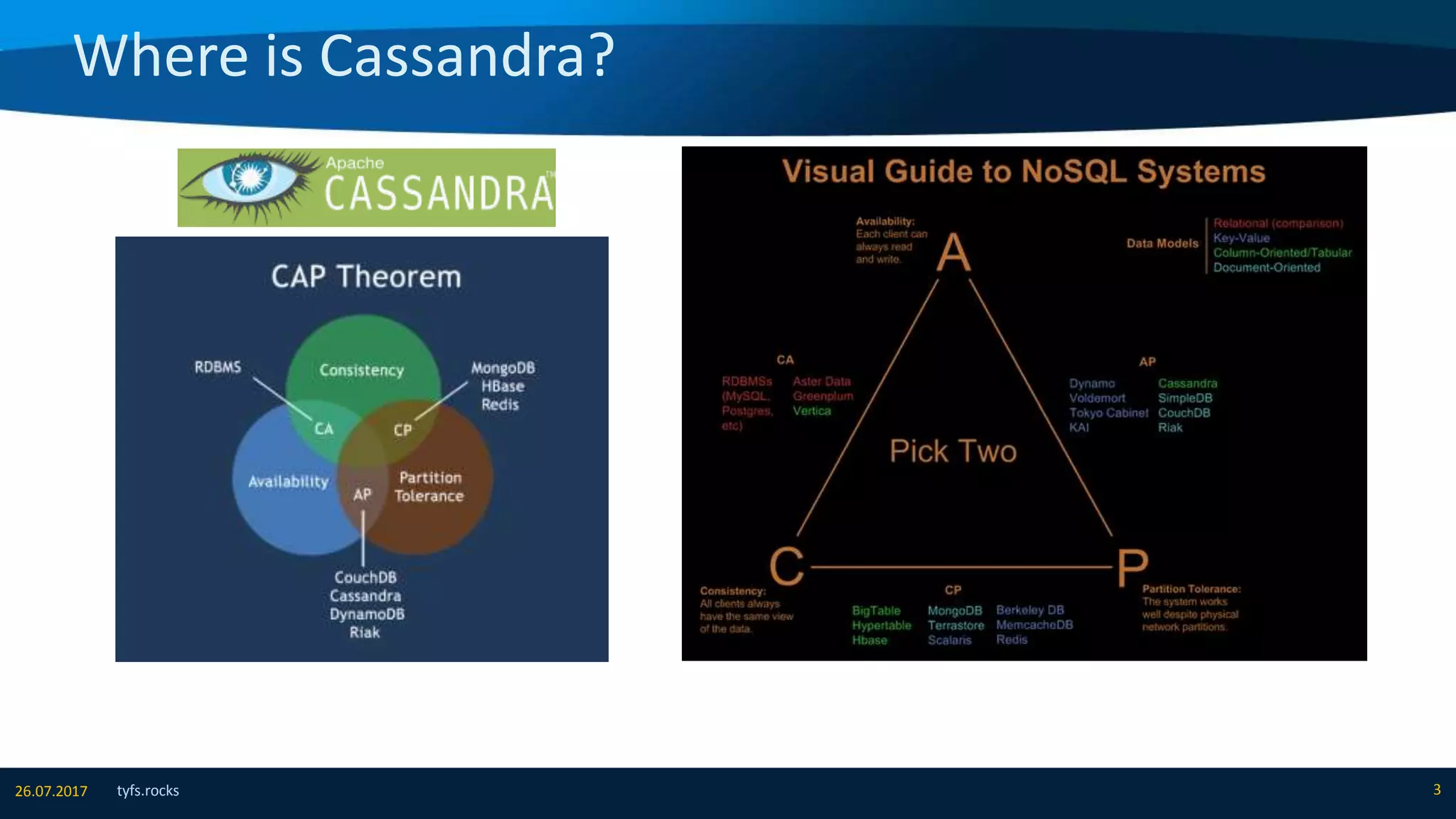
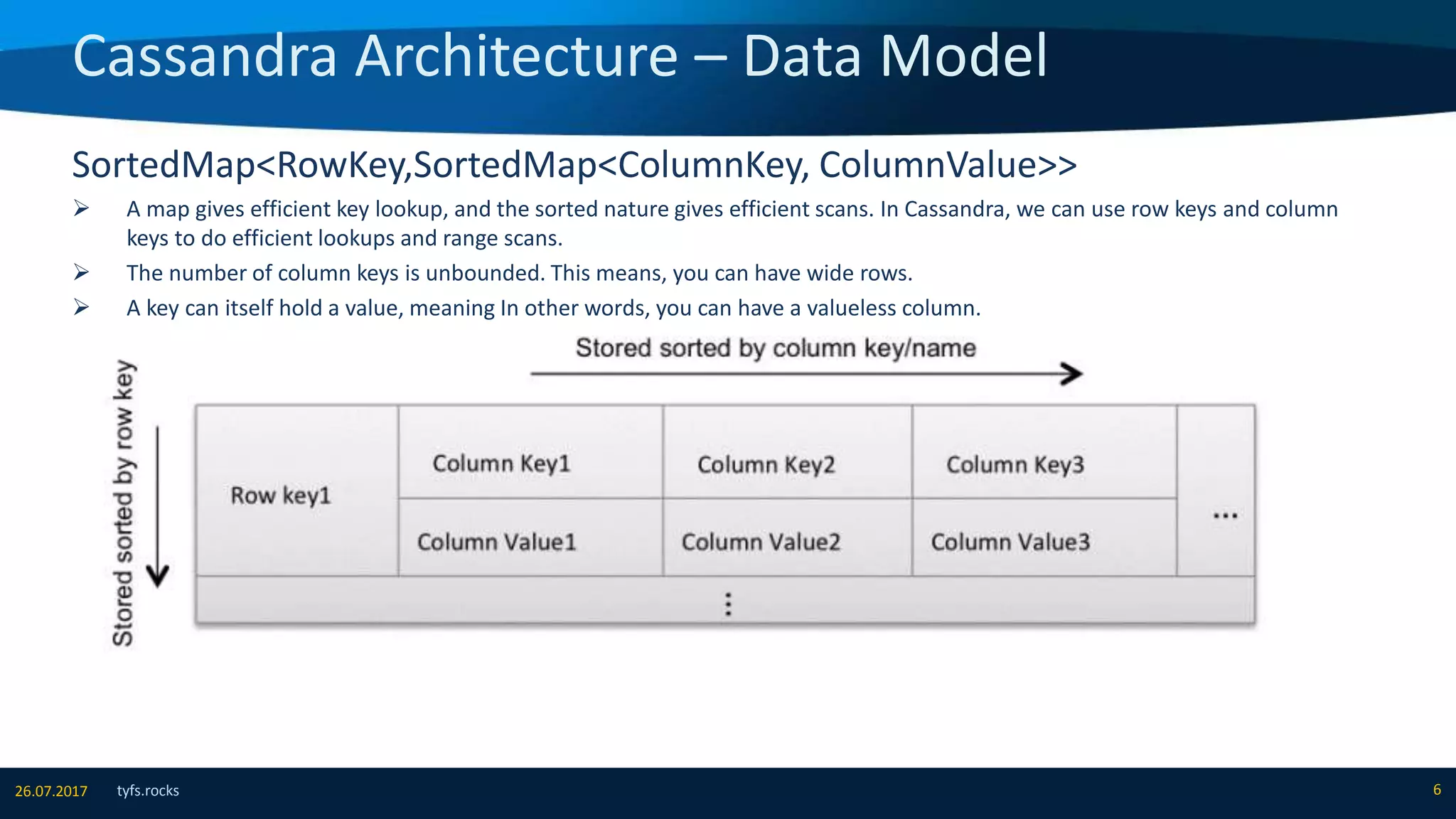
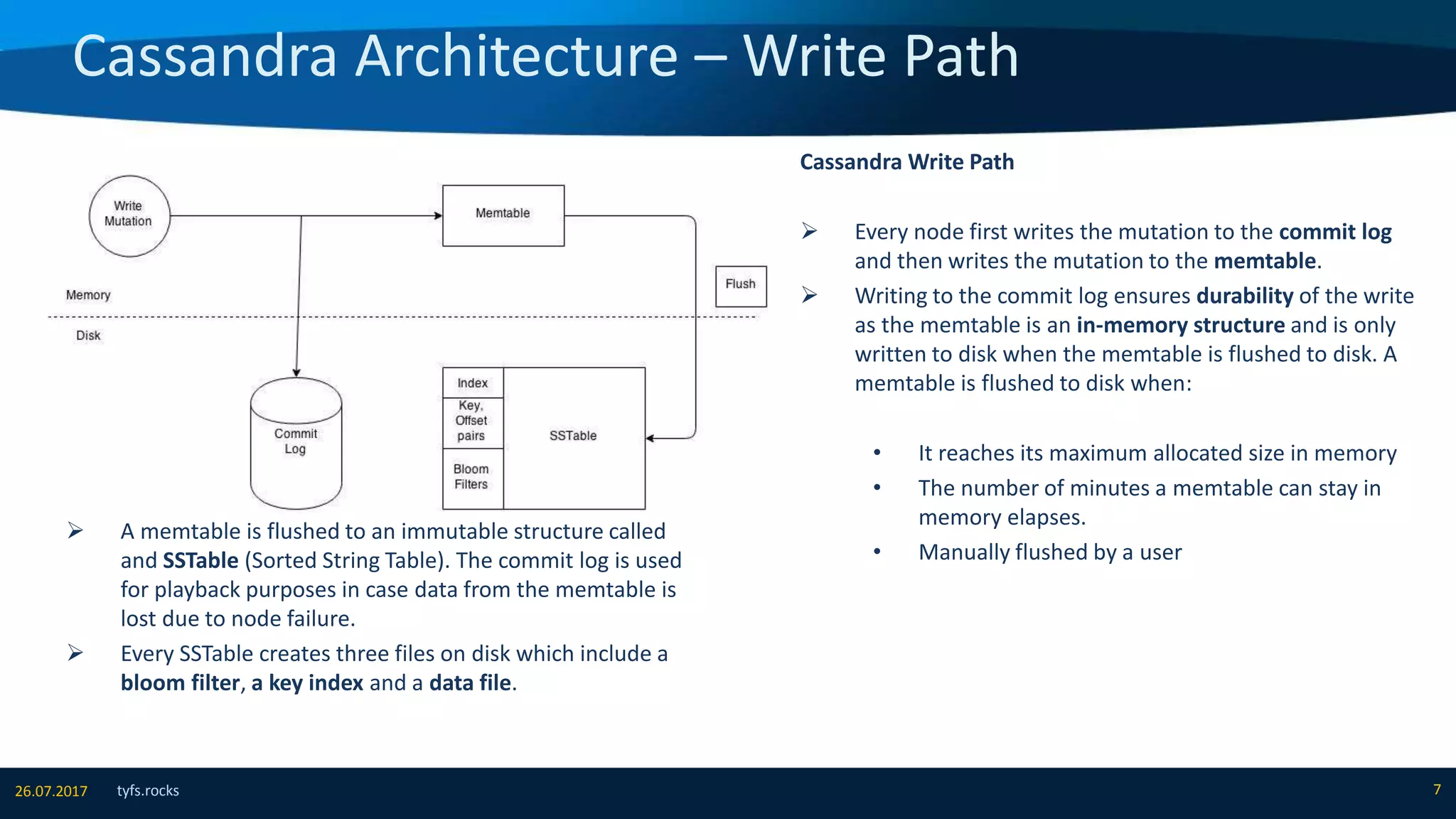
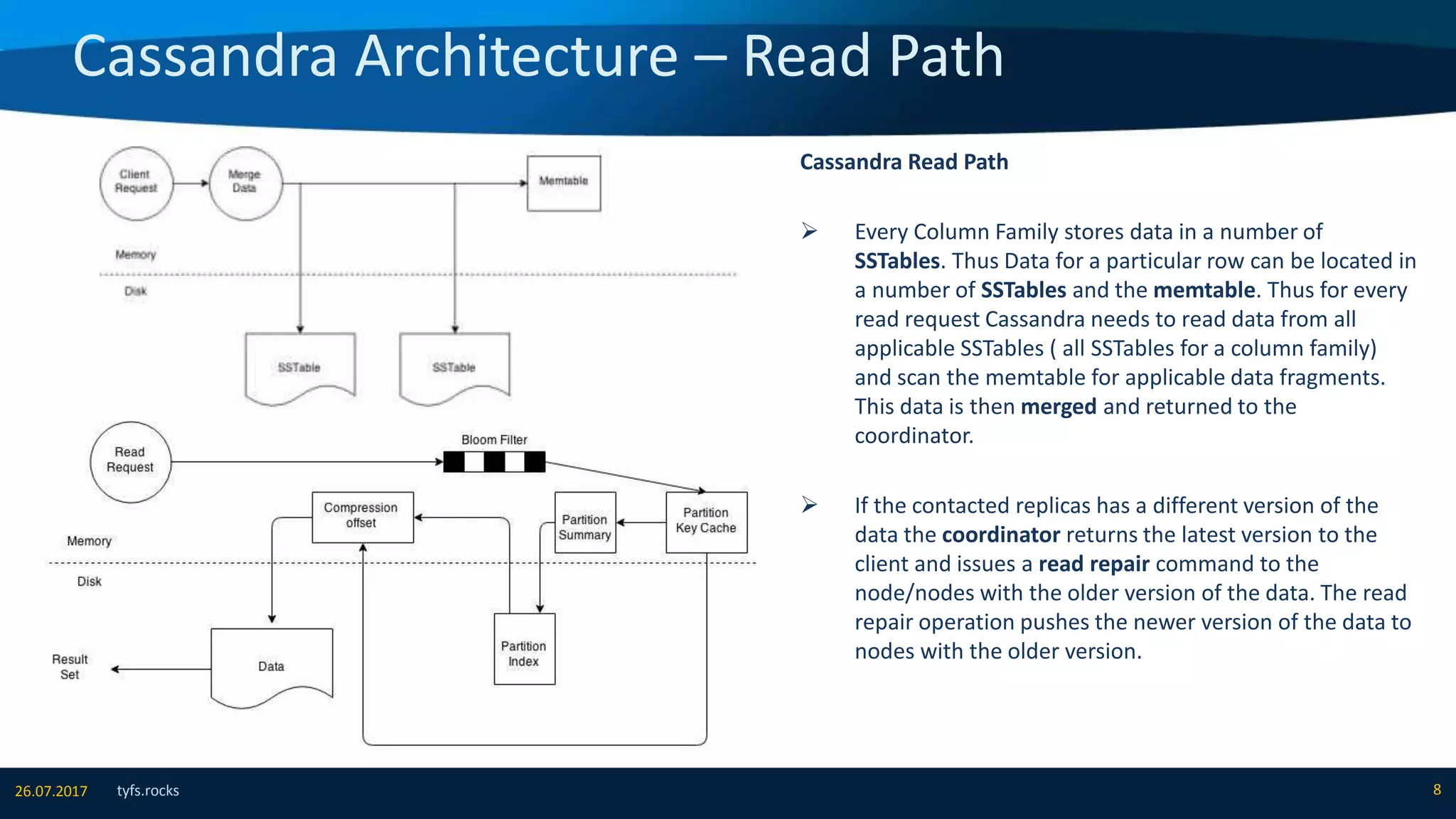
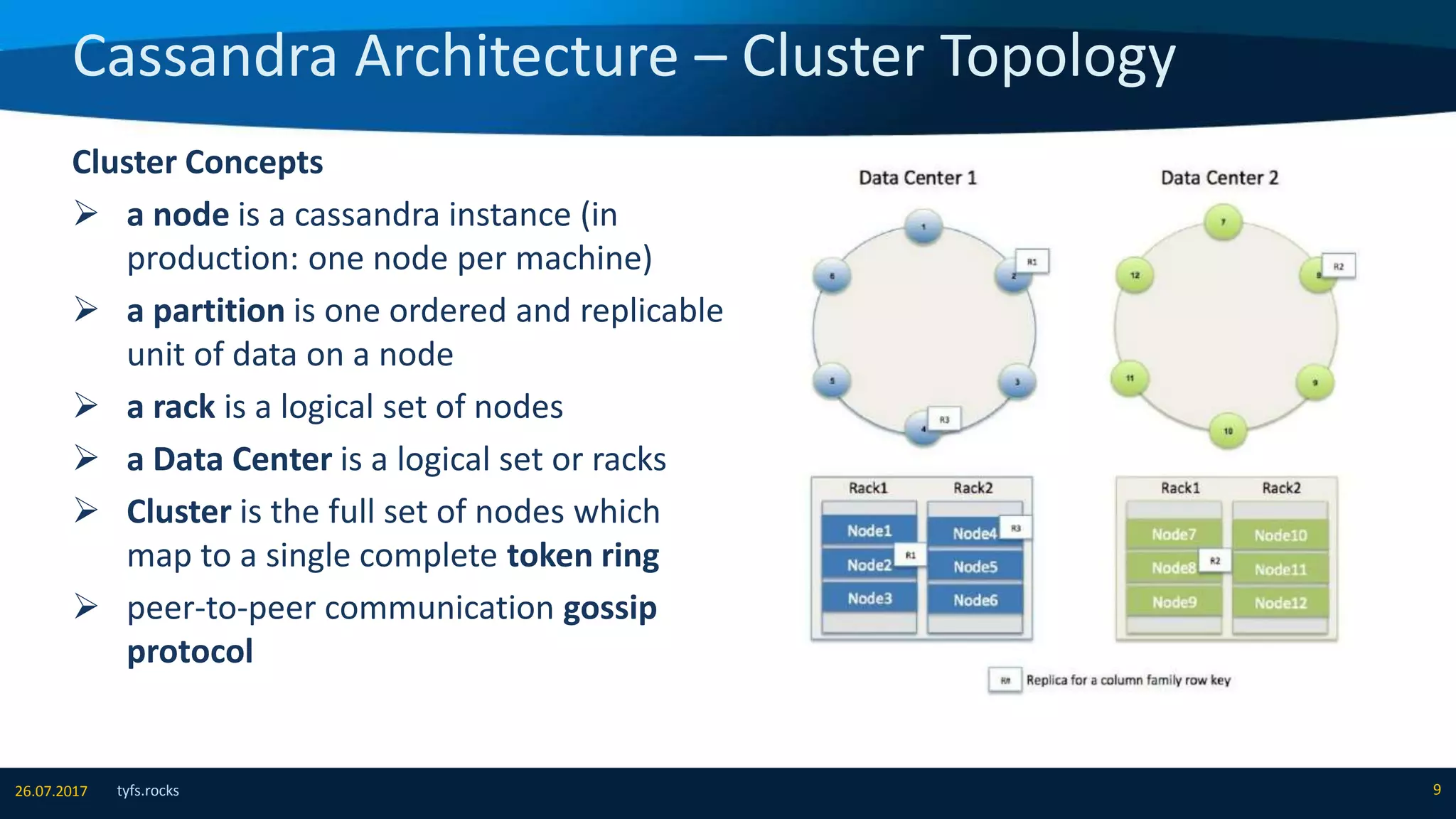
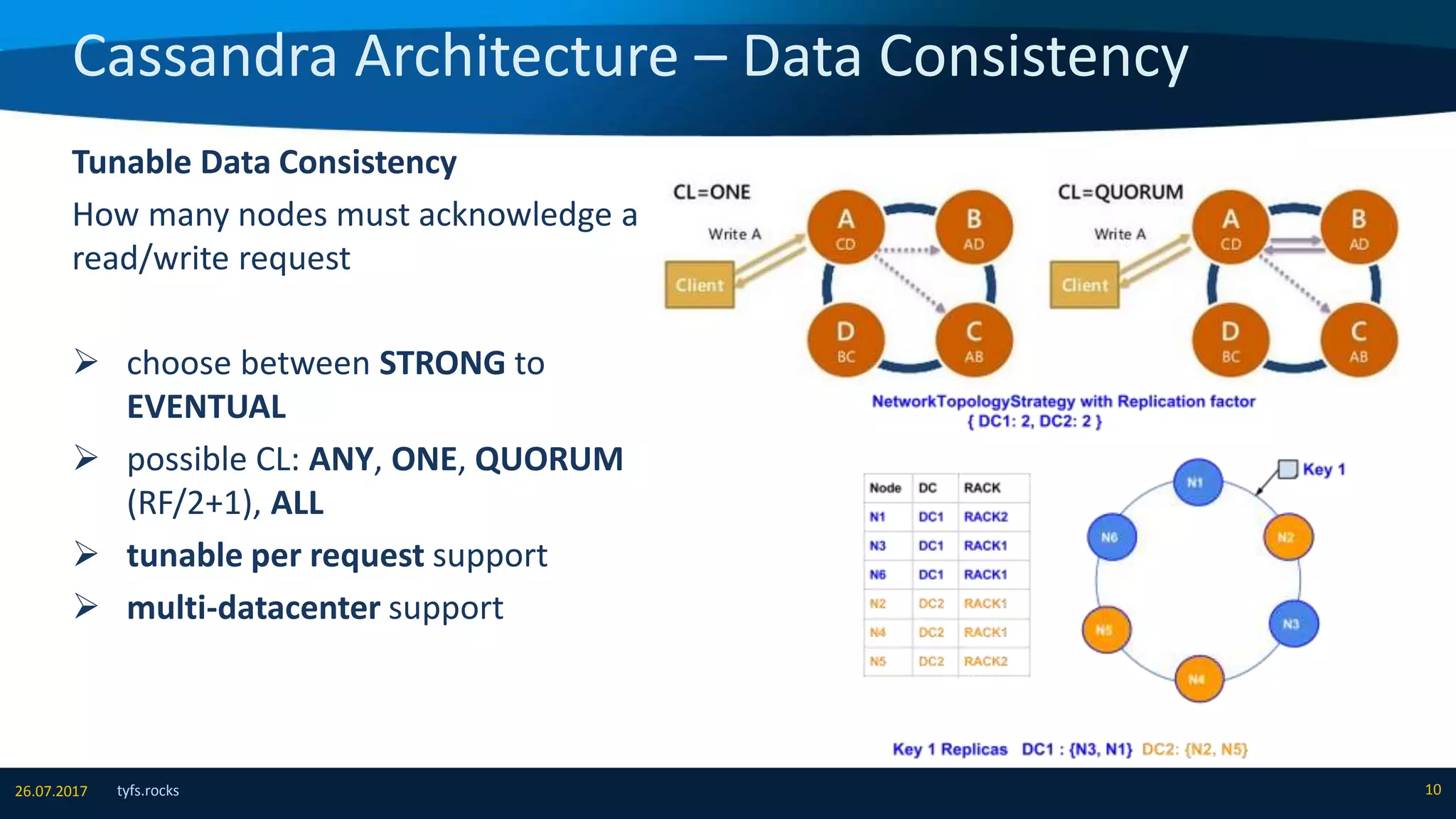
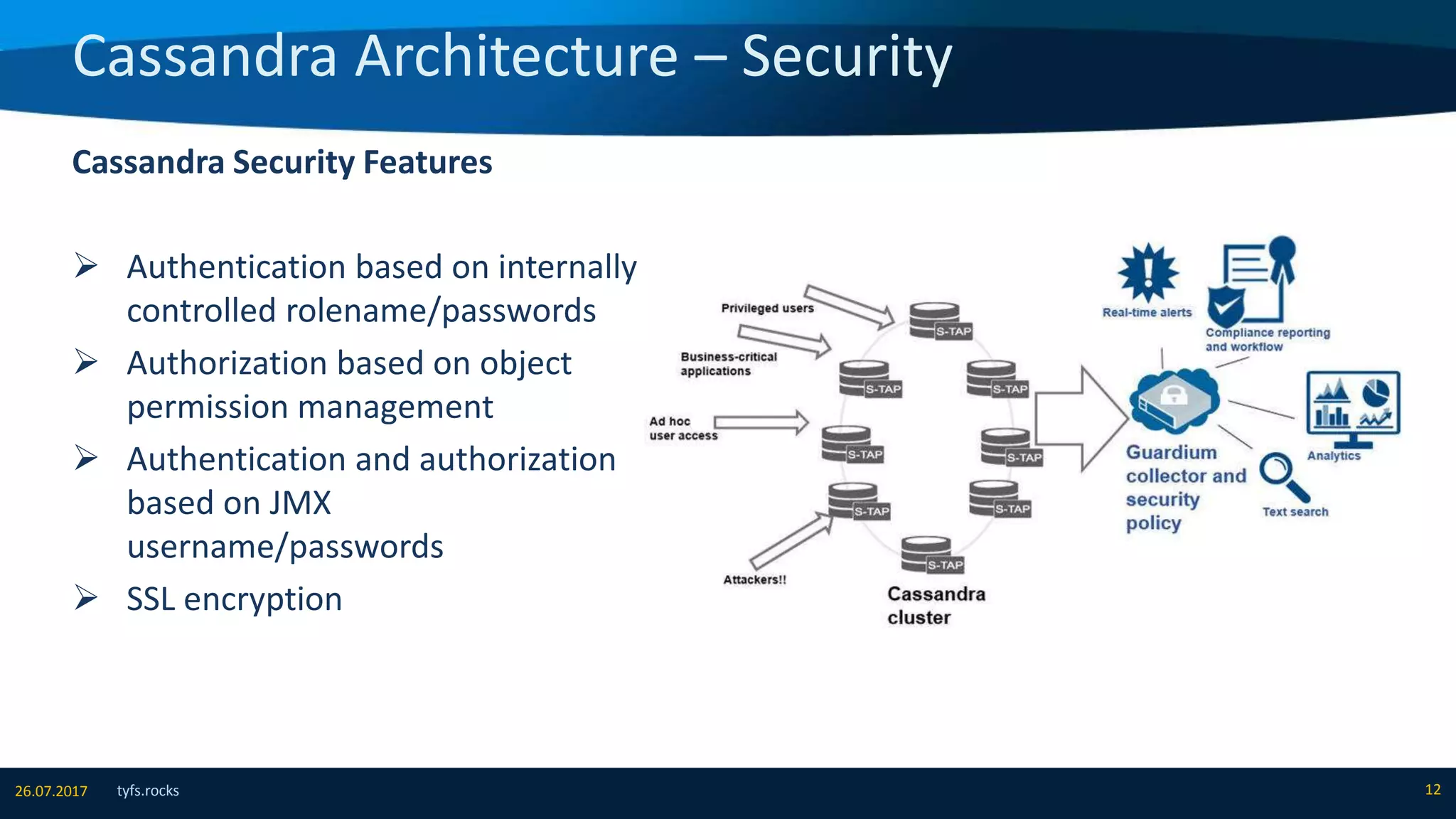
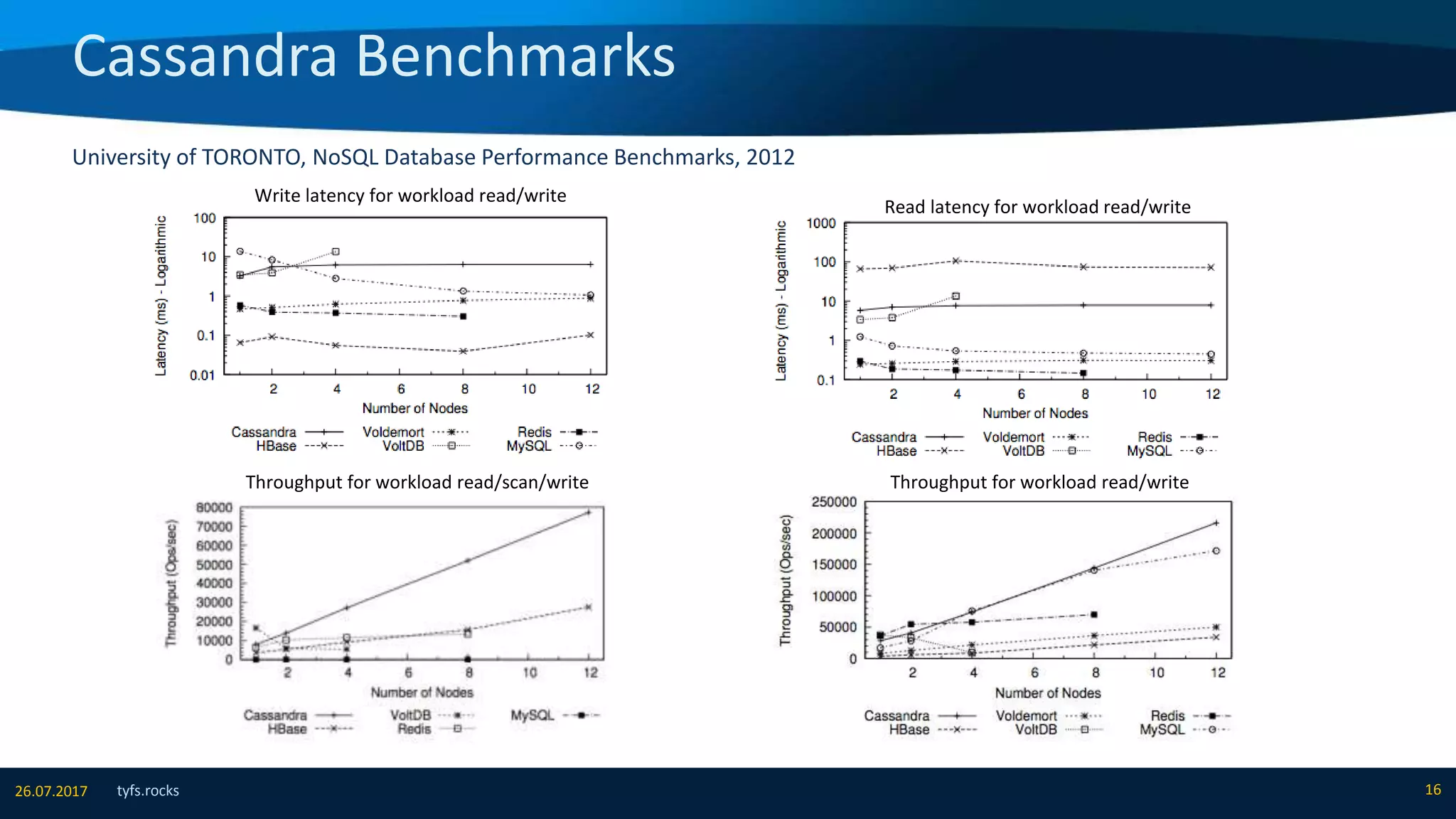
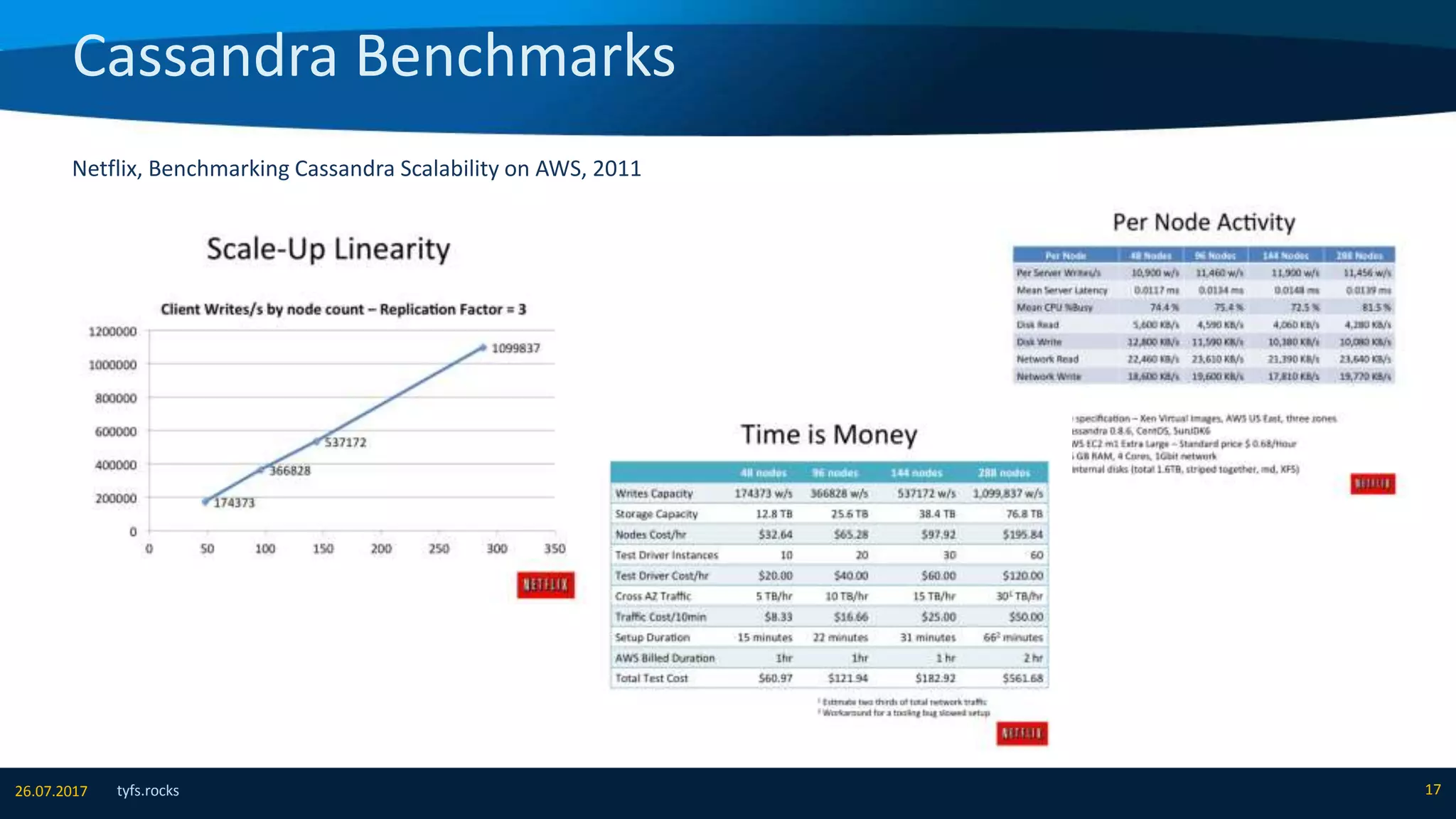
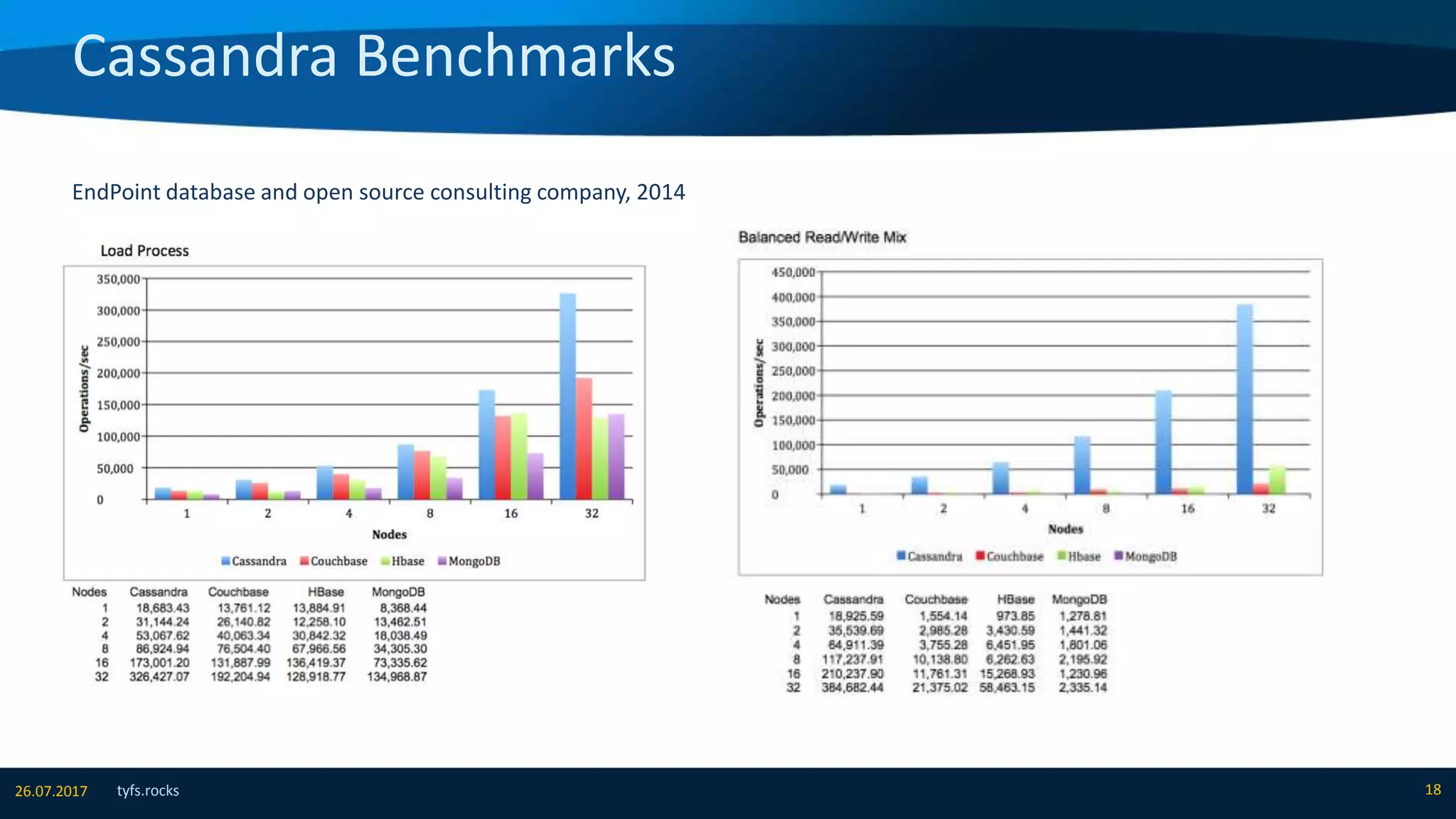
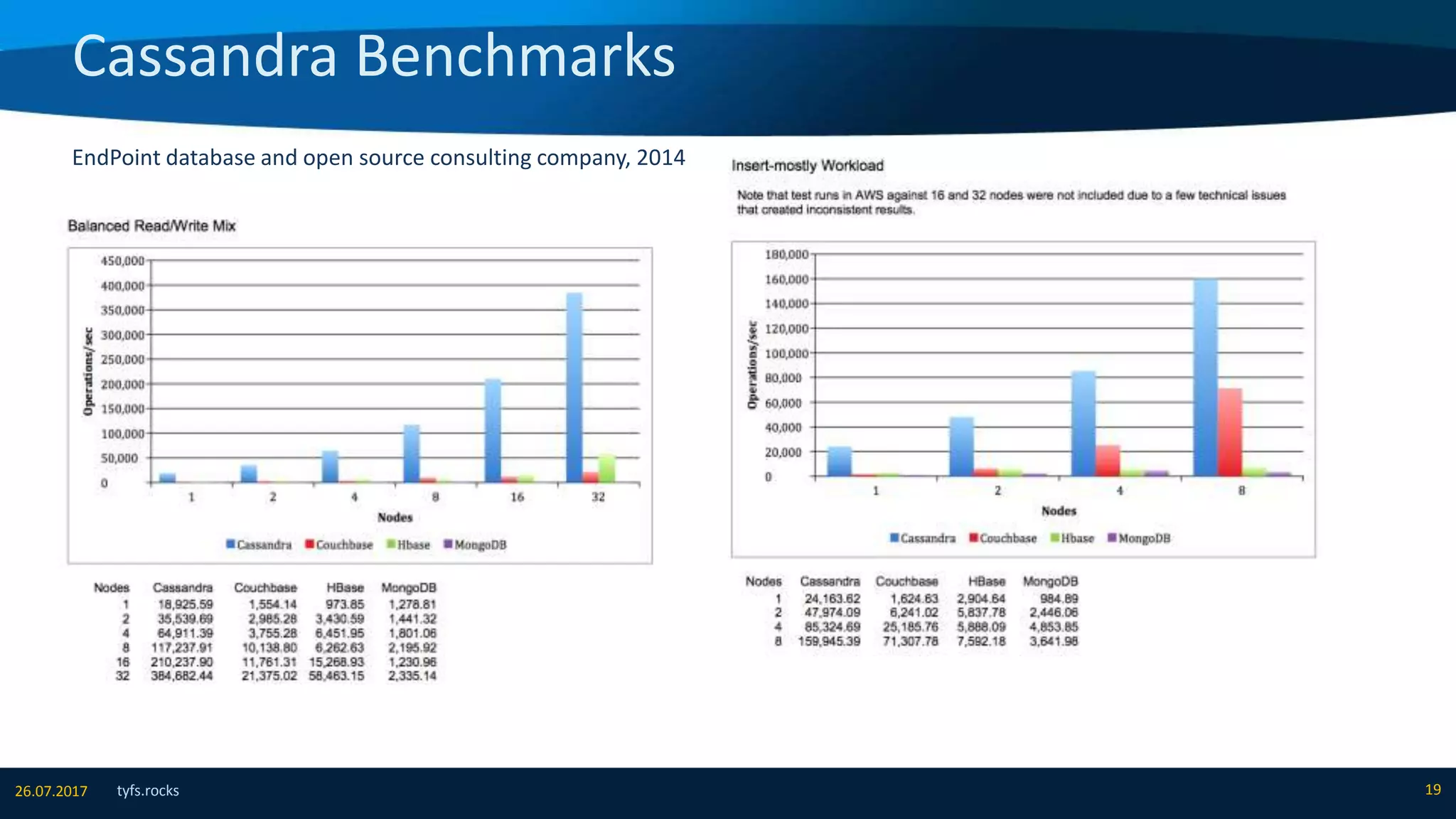
The document provides an overview of Apache Cassandra, detailing its architecture, data model, write and read paths, cluster topology, and consistency mechanisms. It highlights Cassandra's capabilities, including linear scalability, fault tolerance, and ease of administration, making it suitable for applications like messaging, IoT, and retail. Additionally, the document discusses Cassandra's query language, security features, and multiple use cases where it excels.