逆誤差伝播諸公式メモ
大邦将猛
2019 年 5月 19 日
1 順伝播の式
a
(l+1)
i =
n∑
j=1
W
(l+1)
ij z
(l)
j (i = 1, 2, 3, ..., m l = 1, 2, 3, ..., N − 1) (1.1)
z
(l)
i = ReLUα(a
(l)
i ) (i = 1, 2, 3, ..., n l = 1, 2, 3, ..., N − 1) (1.2)
z
(N)
i =
ea
(N)
i
∑c
k=1 ea
(N)
k
(i = 1, 2, 3, ..., c) (1.3)
y = ReLUα(x) =
{
x (x ≥ 0)
αx (x < 0 0 ≤ α < 1)
(1.4)
2 順伝播の式から得られる偏微分
式 (1.1) から
∂a
(l)
i
∂z
(l−1)
j
= W
(l)
ij (l = 2, 3, ..., N) (2.1)
∂a
(l)
i
∂W
(l)
jk
=
{
z
(l−1)
k (i = j)
0 (i ̸= j)
(l = 2, 3, ..., N) (2.2)
式 (1.2) から
∂z
(l)
i
∂a
(l)
j
=
1 (i = j x ≥ 0)
α (i = j x < 0)
0 (i ̸= j)
(l = 1, 2, 3, ..., N − 1) (2.3)
式 (1.3) から
∂z
(N)
i
∂a
(N)
j
が求められるがやや複雑なので場合分けして求める
まず η を次式のようにおき、a
(N)
1 , a
(N)
2 , a
(N)
3 , ..., a
(N)
c の変数に依存する関数とみなす。
η = f(a
(N)
1 , a
(N)
2 , a
(N)
3 , ..., a(N)
c ) =
c∑
k=1
ea
(N)
k (2.4)
1
2.
(i ̸= j)のとき、式 (1.3) の分子 ea
(N)
i は a
(N)
j
に依存しないから、
∂z
(N)
i
∂a
(N)
j
=
∂
∂a
(N)
j
(
ea
(N)
i
η
) = ea
(N)
i
∂
∂a
(N)
j
(
1
η
) = ea
(N)
i
∂η
∂a
(N)
j
∂
∂η
(
1
η
) = ea
(N)
i
∂η
∂a
(N)
j
(
−1
η2
) (2.5)
ところで ∂η
∂a
(N)
j
は単純に
∂η
∂a
(N)
j
= ea
(N)
j (2.6)
なので式 (2.5) は結局
∂z
(N)
i
∂a
(N)
j
= (
−ea
(N)
i ea
(N)
j
η2
) (2.7)
(i = j) のとき、今度は分子 ea
(N)
i は a
(N)
i に依存するので、
∂z
(N)
i
∂a
(N)
i
=
∂
∂a
(N)
i
(
ea
(N)
i
η
) = (
∂
∂a
(N)
i
ea
(N)
i )
1
η
+ ea
(N)
i (
∂
∂a
(N)
i
1
η
) =
ea
(N)
i
η
−
(ea
(N)
i )2
η2
(2.8)
ここで
Iij =
{
1 (i = j のとき)
0 (i ̸= j のとき)
(2.9)
のような記号を導入すれば式 (2.5) と式 (2.8) は合わせて以下の偏微分の式を与える
∂z
(N)
i
∂a
(N)
j
=
Iijea
(N)
i
η
−
ea
(N)
i ea
(N)
j
η2
(2.10)
3 クロスエントロピーの式再掲
ミニバッチ平均
H(Y, y) = −
∑P Hmax
P H=1 Y<P H>
log(y<P H>
)
PHmax
(3.1)
サンプル一つについて
H(Y, y) = −Y<P H>
log(y<P H>
) = −
c∑
k=1
Y <P H>
k log(y<P H>
k ) (3.2)
以下サンプル一つの勾配をしばらく計算するので式 (3.2) のサンプル番号 < PH > を省略する
ここで教師データ Y は分類クラス CP H のデータであるとする
2
3.
このとき Y は以下のOne-hot 表現になっている。すなわち YCP H
の成分のみが1でその他の成分
がすべて0のベクトルである。式 (2.9) で導入した記号で成分を IiCP H
と書くことができる。
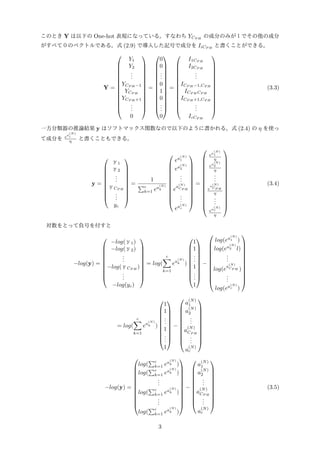
Y =
Y1
Y2
...
YCP H −1
YCP H
YCP H +1
...
0
=
0
0
...
0
1
0
...
0
=
I1CP H
I2CP H
...
ICP H −1,CP H
ICP H CP H
ICP H +1,CP H
...
IcCP H
(3.3)
一方分類器の推論結果 y はソフトマックス関数なので以下のように書かれる。式 (2.4) の η を使っ
て成分を ea
(N)
i
η と書くこともできる。
y =
y1
y2
...
yCP H
...
yc
=
1
∑c
k=1 ea
(N)
k
ea
(N)
1
ea
(N)
2
...
e
a
(N)
CP H
...
ea(N)
c
=
ea
(N)
1
η
ea
(N)
2
η
...
e
a
(N)
CP H
η
...
ea
(N)
c
η
(3.4)
対数をとって負号を付すと
−log(y) =
−log(y1)
−log(y2)
...
−log(yCP H
)
...
−log(yc)
= log(
c∑
k=1
ea
(N)
k )
1
1
...
1
...
1
−
log(ea
(N)
1 )
log(ea
(N)
2 l)
...
log(e
a
(N)
CP H )
...
log(ea(N)
c )
= log(
c∑
k=1
ea
(N)
k )
1
1
...
1
...
1
−
a
(N)
1
a
(N)
2
...
a
(N)
CP H
...
a
(N)
c
−log(y) =
log(
∑c
k=1 ea
(N)
k )
log(
∑c
k=1 ea
(N)
k )
...
log(
∑c
k=1 ea
(N)
k )
...
log(
∑c
k=1 ea
(N)
k )
−
a
(N)
1
a
(N)
2
...
a
(N)
CP H
...
a
(N)
c
(3.5)
3
4.
式 (3.3) と(3.5) の内積をとればクロスエントロピー式 (3.2) が求まる。
H(Y, y) = −Y<P H>
log(y<P H>
) = log(
c∑
k=1
ea
(N)
k ) − a
(N)
CP H
(3.6)
4 クロスエントロピーの勾配を求めていく
まずなにを求めたかったのか再度言及する
クロスエントロピーはニューラルネットワークのトポロジー中に存在するニューロンとニューロン
の間の重み係数 Wl
ij (i, j = 1, 2, 3, ....かつ l = 1, 2, 3, ..., N) すべてで構成された非常に次元数の
大きい空間のベクトルに依存する関数である。この空間におけるクロスエントロピーの勾配が求め
たい
具体的には以下のようにすべてのニューラルネットワークの層のすべてのニューロンをつなぐ重み
での偏微分
∂H
∂W
(1)
11
,
∂H
∂W
(1)
12
,
∂H
∂W
(1)
13
, .....
∂H
∂W
(1)
n2n1
,
∂H
∂W
(2)
11
,
∂H
∂W
(2)
12
,
∂H
∂W
(2)
13
, .....
∂H
∂W
(2)
n3n2
,
....
∂H
∂W
(N)
11
,
∂H
∂W
(N)
12
,
∂H
∂W
(N)
13
, .....
∂H
∂W
(N)
cnN−1
をすべて求めなければならない
しかし式 (3.6) は第 N 層の活性 a
(
iN) への依存しかないのですぐには求まらない。そこで式
(2.1),(2.2),(2.3),(2.10) とチェーンルールを用いて、上のすべての偏微分を求めていく
式 (3.6) は層の N に関してのみ変数を含むのでまず第 N 層の偏微分が求められる
∂
∂W
(N)
ij
H =
∂a
(N)
i
∂W
(N)
ij
∂
∂a
(N)
i
H =
∂H
∂a
(N)
i
z
(N−1)
j (4.1)
ここでは式 (2.2) を使っている
つぎに ∂H
∂a
(N)
i
を求める方法はないか考える。
式 (2.4) を使い η を経由してチェーンルールを使うと (i ̸= CP H のとき, 式 (3.6) の第二項が定
数としてみなせるので式 (2.9) の記号を使えることに注意する)
∂H
∂a
(N)
i
=
∂η
∂a
(N)
i
∂H
∂η
− IiCP H
=
ea
(N)
i
η
− IiCP H
(4.2)
δ
(N)
i = ∂H
∂a
(N)
i
を定義し、上の式 (4.2) に式 (3.3) と式 (3.4) の結果を代入すると
δ
(N)
i =
∂H
∂a
(N)
i
= yi − Yi (4.3)
式 (4.3) は重要な意味を持つ式でクロスエントロピーを最終層の活性 a
(N)
i で偏微分するとこの分
類器の推論 yi と真の答え Yi の差がでてくる。そのため誤差をイメージする δ が文字として充てら
4
5.
れているのである。
第 N 層以外にもδ
(l)
i = ∂H
∂a
(l)
i
を定義してみる。ここでもう一度式 (4.1) をみると実はこれは第 N
層にかぎらず成立することに気づく。なぜなら式 (2.2) がすべての層で成り立つからである。
∂
∂W
(l)
ij
H =
∂H
∂a
(l)
i
z
(l−1)
j = δ
(l)
i z
(l−1)
j (4.4)
そして式 (2.1) を使うと第 l 層の a と第 l − 1 層の z の関係を使ってニューラルネットワークの
出力側から入力側に誤差 δ を引き継ぐ漸化式がつくれることがわかる。実際
δ
(l)
i =
∂H
∂a
(l)
i
=
lmax∑
j=1
l+1max∑
k=1
∂z
(l)
j
∂a
(l)
i
∂a
(l+1)
k
∂z
(l)
j
∂H
∂a
(l+1)
k
=
lmax∑
j=1
l+1max∑
k=1
∂z
(l)
j
∂a
(l)
i
∂a
(l+1)
k
∂z
(l)
j
δ
(l+1)
k (4.5)
式 (2.1) を代入して
δ
(l)
i =
lmax∑
j=1
l+1max∑
k=1
∂z
(l)
j
∂a
(l)
i
W
(l+1)
kj δ
(l+1)
k
さらに式 (2.3) を代入して、(ただし後述する αSTEP 関数を導入する)次式を得る。
δ
(l)
i =
l+1max∑
k=1
αSTEP(a
(l)
i )W
(l+1)
ki δ
(l+1)
k (4.6)
αSTEP(x)=
{
1 (x ≥ 0)
α (x < 0 0 ≤ α < 1)
(4.7)
5 誤差逆伝播のアルゴリズムまとめ
これで誤差逆伝播に必要なすべての式を得た
式 (3.1) と (3.2) の関係をもう一度注意するため、再度サンプル番号 < PH > をつけてアルゴリズ
ムをまとめる
【サンプル毎にする処理】1. 順伝播計算し、途中の層の z
(l)<P H>
i をすべて保存しておく
2. 最終層の誤差 δ
(N)<P H>
i = y<P H>
i − Y <P H>
i を計算する【式 (4.3)】
3. 漸化式を用いてすべての層の誤差 δ
(l)<P H>
i を求める【式 (4.6)】
δ
(l)<P H>
i =
l+1max∑
k=1
αSTEP(a
(l)<P H>
i )W
(l+1)
ki δ
(l+1)<P H>
k
4.「1.」の z と「2-3.」の δ を使いクロスエントロピーのすべての変数に関する偏微分を求める【式
(4.4)】
∂H<P H>
∂W
(l)
ij
= δ
(l)<P H>
i z
(l−1)<P H>
j
【ミニバッチ毎にする処理】5.「1-4.」の計算をすべてのサンプル(PH = 1, 2, 3, ..., PHmax) でお
こない平均値の勾配を求める
∇H =
∑P Hma x
P H=1
∂H<P H>
∂W
(l)
ij
PHmax
=
∑P Hma x
P H=1 δ
(l)<P H>
i z
(l−1)<P H>
j
PHmax
(5.1)
5



























![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)























