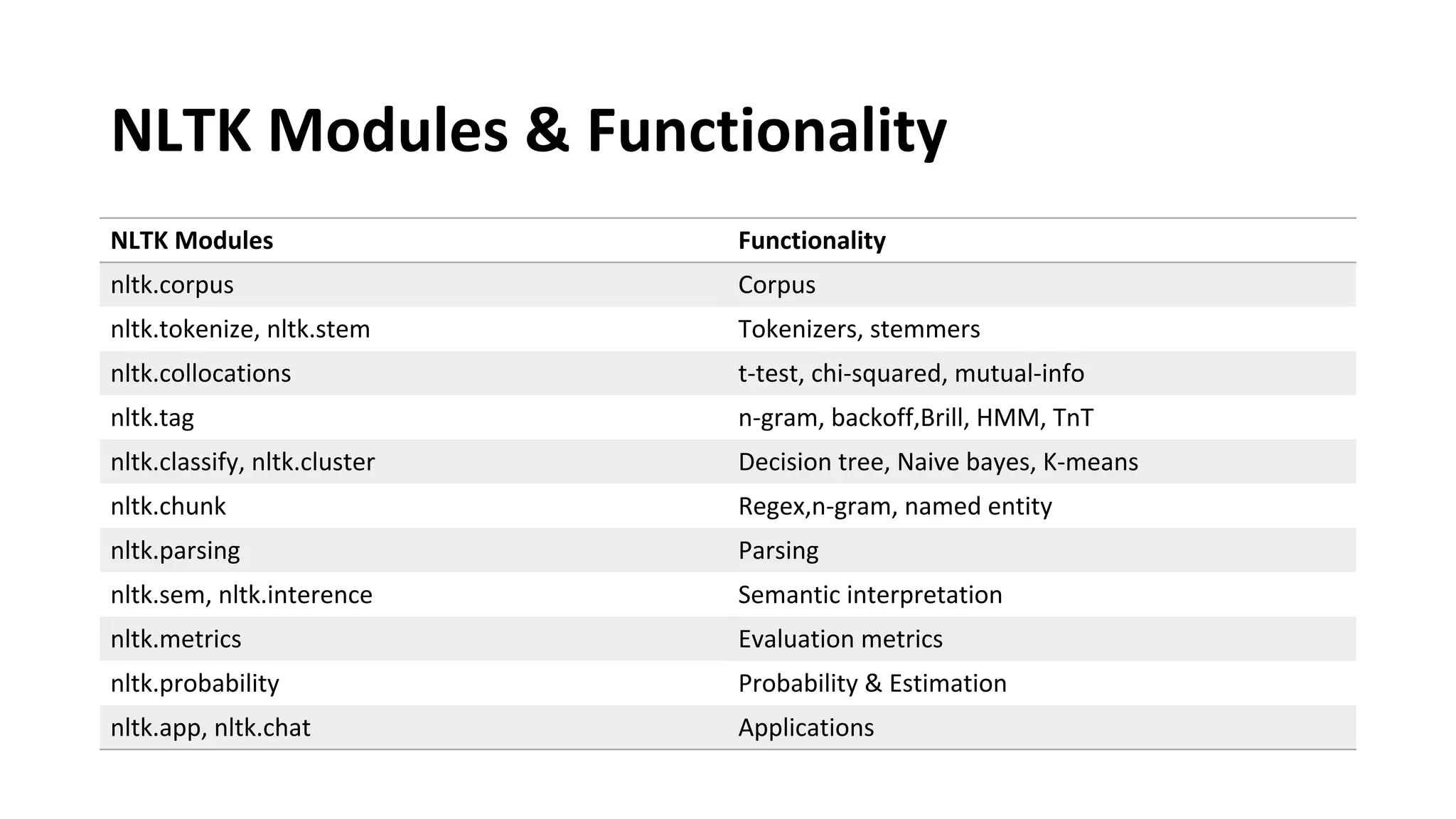
Downloaded 111 times







![Accessing Text Corpora & Lexical Resources
•NLTK provides over 50 corpora and lexical resources.
>>> from nltk.corpus import brown
>>> brown.categories()
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies',
'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance',
'science_fiction']
>>> len(brown.sents())
57340
>>> len(brown.words())
1161192
•http://www.nltk.org/book/ch02.html](https://image.slidesharecdn.com/nltkatoolfornlp-pycon-dhaka-2014-140622215544-phpapp02/75/Nltk-a-tool-for_nlp-py_con-dhaka-2014-9-2048.jpg)
![Tokenization
• Tokenization is the process of breaking a stream of text up into words, phrases,
symbols, or other meaningful elements called tokens.
>>> from nltk.tokenize import word_tokenize, wordpunct_tokenize, sent_tokenize
>>> s = '''Good muffins cost $3.88nin New York. Please buy me two of them.nnThanks.'''
• Word Punctuation Tokenization
>>> wordpunct_tokenize(s)
['Good', 'muffins', 'cost', '$', '3', '.', '88', 'in', 'New', 'York', '.', 'Please', 'buy', 'me', 'two', 'of', 'them', '.', 'Thanks', '.']
• Sentence Tokenization
>>> sent_tokenize(s)
['Good muffins cost $3.88nin New York.', 'Please buy mentwo of them.', 'Thanks.']
• Word Tokenization
>>> [word_tokenize(t) for t in sent_tokenize(s)]
[['Good', 'muffins', 'cost', '$', '3.88', 'in', 'New', 'York', '.'], ['Please', 'buy', 'me', 'two', 'of',
'them', '.'], ['Thanks', '.']]](https://image.slidesharecdn.com/nltkatoolfornlp-pycon-dhaka-2014-140622215544-phpapp02/75/Nltk-a-tool-for_nlp-py_con-dhaka-2014-10-2048.jpg)



![Part-of-speech Tagging
•Part-of-speech Tagging is the process of marking up a word in a text
(corpus) as corresponding to a particular part of speech
>>> from nltk.tokenize import word_tokenize
>>> from nltk.tag import pos_tag
>>> words = word_tokenize('And now for something completely different')
>>> pos_tag(words)
[('And', 'CC'), ('now', 'RB'), ('for', 'IN'), ('something', 'NN'), ('completely', 'RB'), ('different',
'JJ')]
•https://www.ling.upenn.
edu/courses/Fall_2003/ling001/penn_treebank_pos.html](https://image.slidesharecdn.com/nltkatoolfornlp-pycon-dhaka-2014-140622215544-phpapp02/75/Nltk-a-tool-for_nlp-py_con-dhaka-2014-14-2048.jpg)
![Named-entity Recognition
•Named-entity recognition is a subtask of information extraction that
seeks to locate and classify elements in text into pre-defined
categories such as the names of persons, organizations, locations,
expressions of times, quantities, monetary values, percentages, etc.
>>> from nltk import pos_tag, ne_chunk
>>> from nltk.tokenize import wordpunct_tokenize
>>> sent = 'Jim bought 300 shares of Acme Corp. in 2006.'
>>> ne_chunk(pos_tag(wordpunct_tokenize(sent)))
Tree('S', [Tree('PERSON', [('Jim', 'NNP')]), ('bought', 'VBD'), ('300', 'CD'), ('shares', 'NNS'),
('of', 'IN'), Tree('ORGANIZATION', [('Acme', 'NNP'), ('Corp', 'NNP')]), ('.', '.'), ('in', 'IN'),
('2006', 'CD'), ('.', '.')])](https://image.slidesharecdn.com/nltkatoolfornlp-pycon-dhaka-2014-140622215544-phpapp02/75/Nltk-a-tool-for_nlp-py_con-dhaka-2014-15-2048.jpg)
![Language model
•A statistical language model assigns a probability to a sequence of m
words P(w1, w2, …., wm) by means of a probability distribution.
>>> import nltk
>>> from nltk.corpus import gutenberg
>>> from nltk.model import NgramModel
>>> from nltk.probability import LidstoneProbDist
>>> ssw=[w.lower() for w in gutenberg.words('austen-sense.txt')]
>>> ssm=NgramModel(3, ssw, True, False, lambda f,b:LidstoneProbDist(f,0.01,f.B()+1))
>>> ssm.prob('of',('the','name'))
0.907524932004
>>> ssm.prob('if',('the','name'))
0.0124444830775](https://image.slidesharecdn.com/nltkatoolfornlp-pycon-dhaka-2014-140622215544-phpapp02/75/Nltk-a-tool-for_nlp-py_con-dhaka-2014-16-2048.jpg)



NLTK is a popular Python library for natural language processing. It provides tools for tasks like tokenization, stemming, lemmatization, part-of-speech tagging, named entity recognition, parsing, and language models. NLTK includes functions, classes, and sample datasets to support research and development in NLP. It is open source, easy to use, well documented, and supports many common NLP tasks and algorithms.























































































