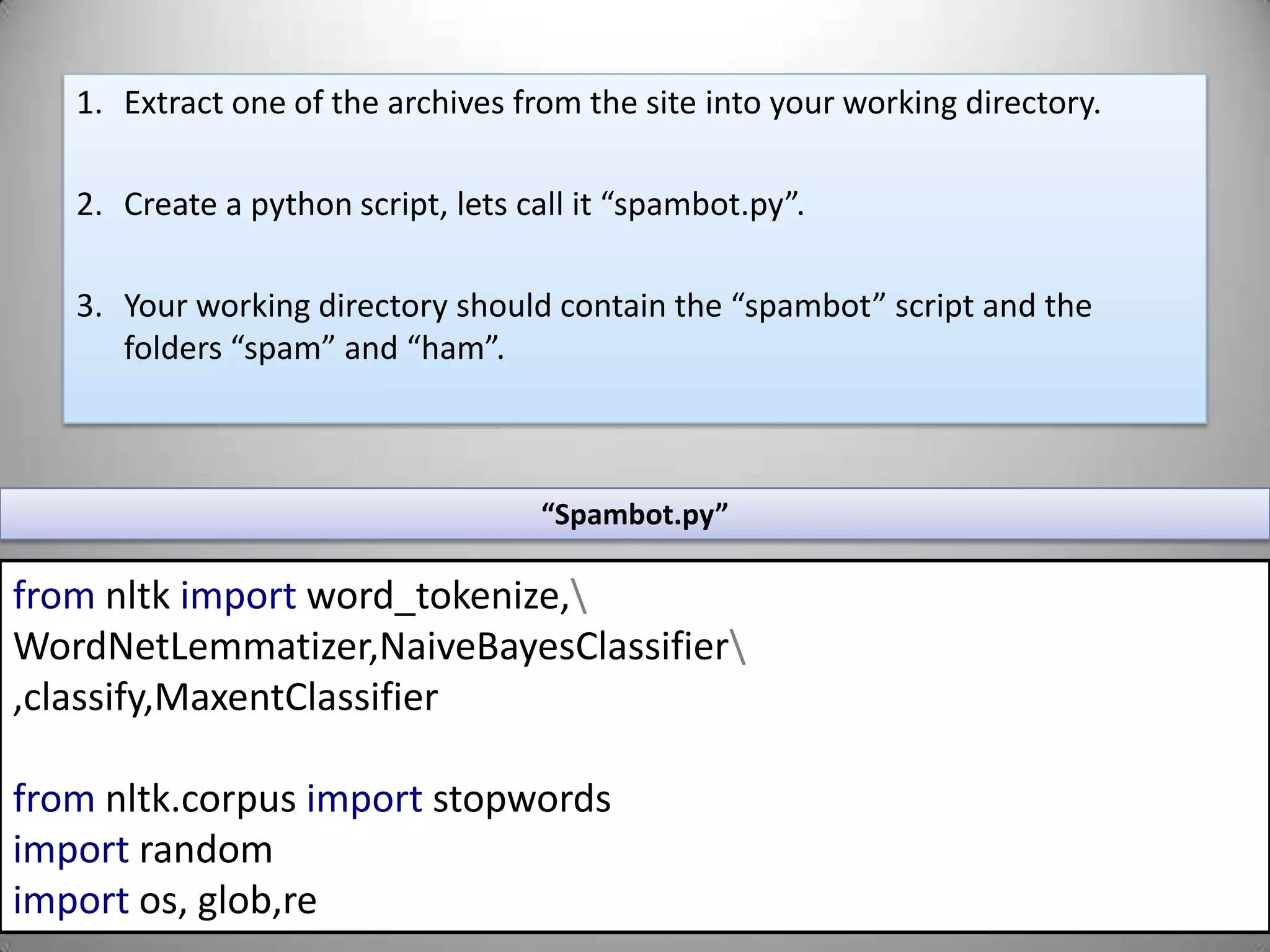
The document presents a tutorial on natural language processing (NLP) and machine learning using Python, focusing on the Natural Language Toolkit (nltk) and its applications. It covers foundational concepts, key terms, and provides step-by-step guides for creating NLP applications such as spam filters and chatbots. Additionally, it highlights challenges in communication and the risks of overfitting in machine learning models.















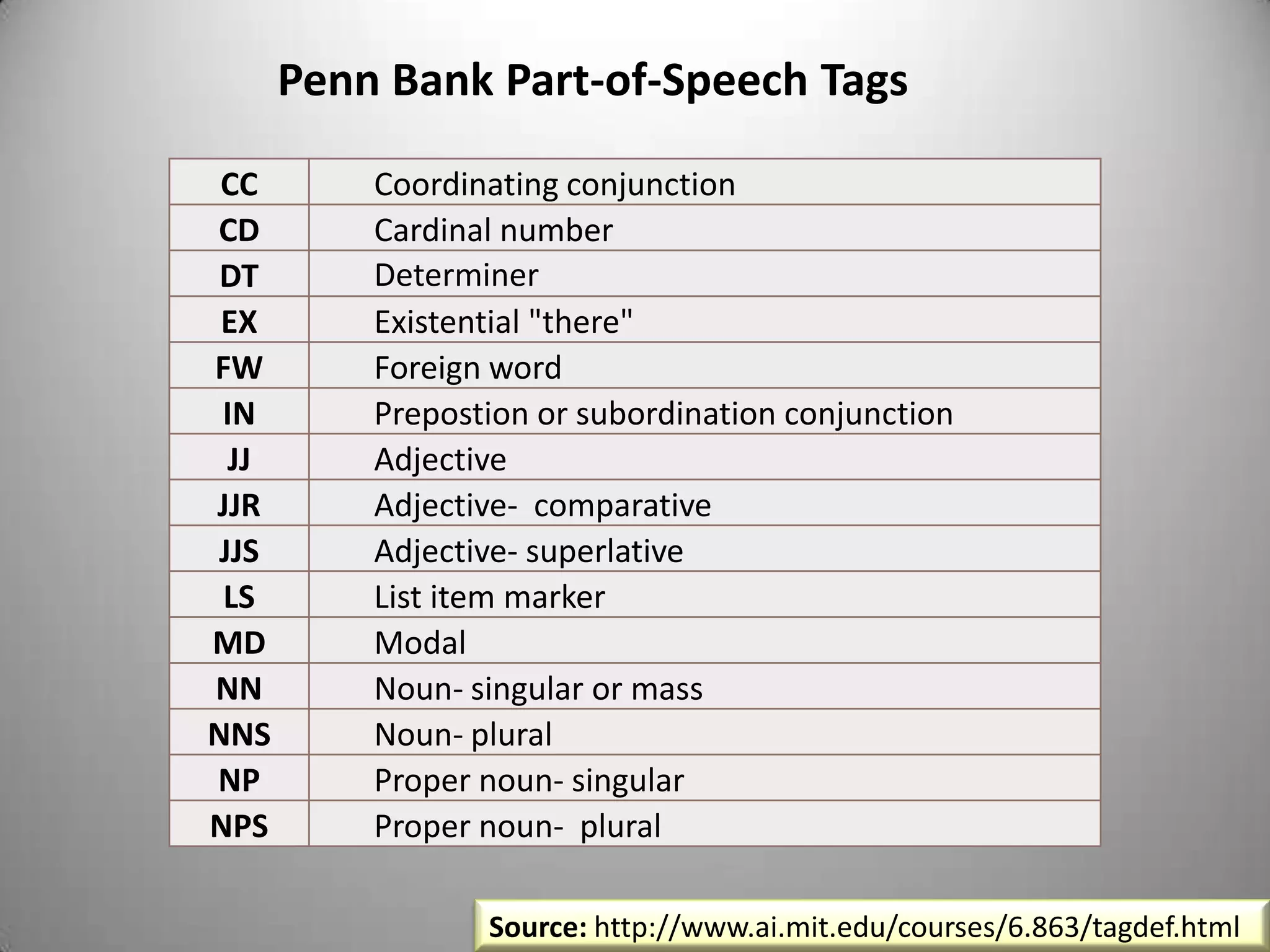
![Part of Speech Taggingfromnltkimportpos_tag,word_tokenizesentence1='this is a demo that will show you how to detects parts of speech with little effort using NLTK!'tokenized_sent=word_tokenize(sentence1)printpos_tag(tokenized_sent)[('this', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('demo', 'NN'), ('that', 'WDT'), ('will', 'MD'), ('show', 'VB'), ('you', 'PRP'), ('how', 'WRB'), ('to', 'TO'), ('detects', 'NNS'), ('parts', 'NNS'), ('of', 'IN'), ('speech', 'NN'), ('with', 'IN'), ('little', 'JJ'), ('effort', 'NN'), ('using', 'VBG'), ('NLTK', 'NNP'),('!', '.')]](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-22-2048.jpg)

![NLTK Textnltk.clean_html(rawhtml)from nltk.corpus import brownfrom nltk import Textbrown_words = brown.words(categories='humor')brownText = Text(brown_words)brownText.collocations()brownText.count("car")brownText.concordance("oil")brownText.dispersion_plot(['car', 'document', 'funny', 'oil'])brownText.similar('humor')](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-24-2048.jpg)
![Find similar terms (word definitions) using Wordnetimportnltkfromnltk.corpusimportwordnetaswnsynsets=wn.synsets('phone')print[str(syns.definition)forsynsinsynsets] 'electronic equipment that converts sound into electrical signals that can be transmitted over distances and then converts received signals back into sounds‘'(phonetics) an individual sound unit of speech without concern as to whether or not it is a phoneme of some language‘'electro-acoustic transducer for converting electric signals into sounds; it is held over or inserted into the ear‘'get or try to get into communication (with someone) by telephone'](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-25-2048.jpg)
![from nltk.corpus import wordnet as wnsynsets = wn.synsets('phone')print [str( syns.definition ) for syns in synsets]“syns.definition” can be modified to output hypernyms , meronyms, holonyms etc:](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-26-2048.jpg)





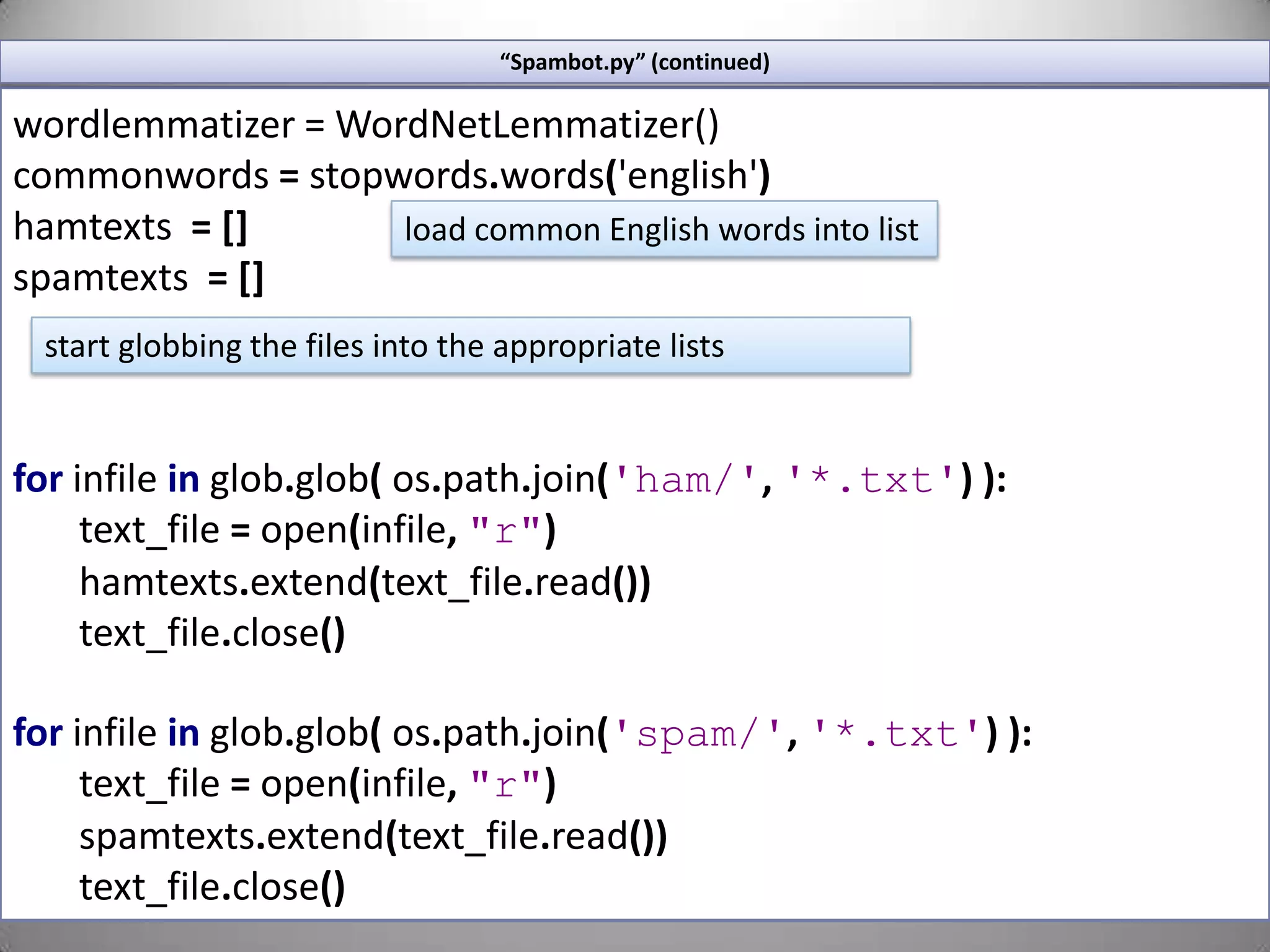

![“Spambot.py” (continued)wordlemmatizer = WordNetLemmatizer()commonwords = stopwords.words('english') hamtexts=[]spamtexts=[]forinfileinglob.glob(os.path.join('ham/','*.txt')):text_file=open(infile,"r")hamtexts.extend(text_file.read())text_file.close()forinfileinglob.glob(os.path.join('spam/','*.txt')):text_file=open(infile,"r")spamtexts.extend(text_file.read())text_file.close()load common English words into liststart globbing the files into the appropriate lists](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-35-2048.jpg)
![“Spambot.py” (continued)mixedemails=([(email,'spam')foremailinspamtexts]mixedemails+= [(email,'ham')foremailinhamtexts])random.shuffle(mixedemails)label each item with the appropriate label and store them as a list of tuplesFrom this list of random but labeled emails, we will defined a “feature extractor” which outputs a feature set that our program can use to statistically compare spam and ham. lets give them a nice shuffle](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-36-2048.jpg)
![“Spambot.py” (continued)defemail_features(sent):features={}wordtokens=[wordlemmatizer.lemmatize(word.lower())forwordinword_tokenize(sent)]forwordinwordtokens:ifwordnotincommonwords:features[word]=Truereturnfeaturesfeaturesets=[(email_features(n),g)for(n,g)inmixedemails]Normalize wordsIf the word is not a stop-word then lets consider it a “feature”Let’s run each email through the feature extractor and collect it in a “featureset” list](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-37-2048.jpg)
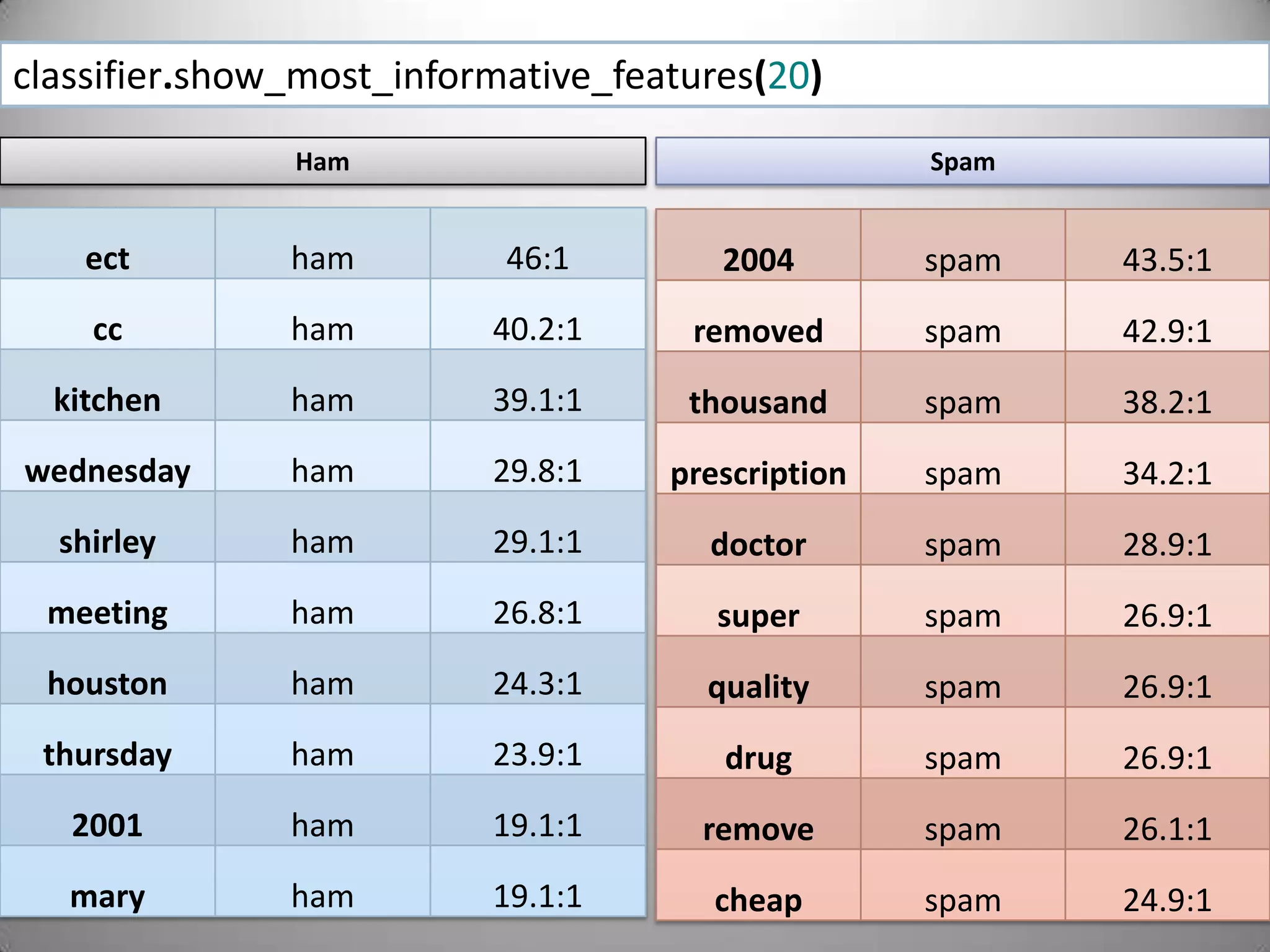
![If the feature is the number 12 the feature is: (“11<x<13”, True)“Spambot.py” (continued)Lets grab a sampling of our featureset. Changing this number will affect the accuracy of the classifier. It will be a different number for every classifier, find the most effective threshold for your dataset through experimentation.size=int(len(featuresets)*0.5)train_set,test_set=featuresets[size:],featuresets[:size]classifier=NaiveBayesClassifier.train(train_set)Using this threshold grab the first n elements of our featureset and the last n elements to populate our “training” and “test” featuresetsHere we start training the classifier using NLTK’s built in Naïve Bayes classifier](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-40-2048.jpg)
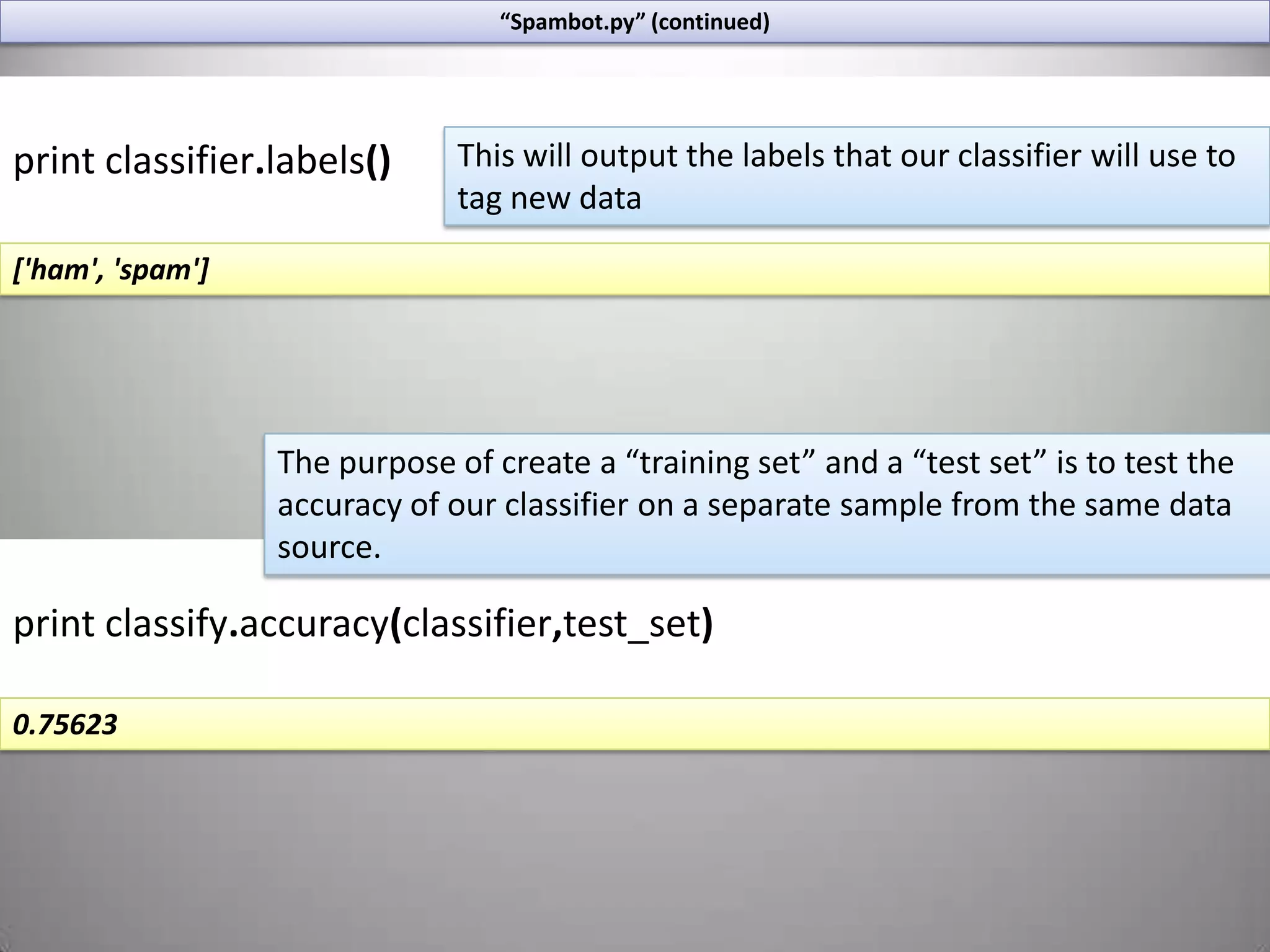
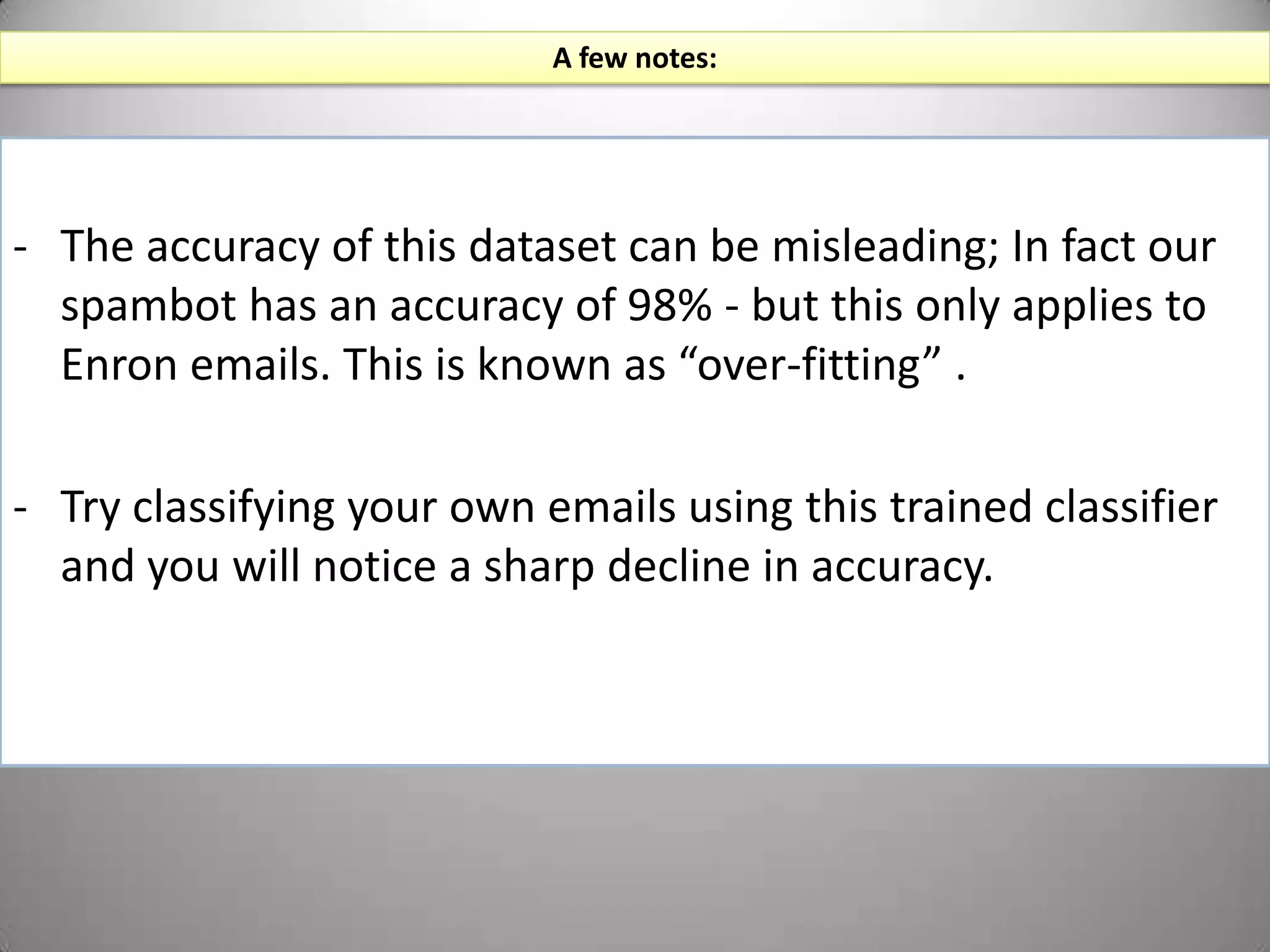
![“Spambot.py” (continued)print classifier.labels()This will output the labels that our classifier will use to tag new data['ham', 'spam']The purpose of create a “training set” and a “test set” is to test the accuracy of our classifier on a separate sample from the same data source.printclassify.accuracy(classifier,test_set)0.75623](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-41-2048.jpg)


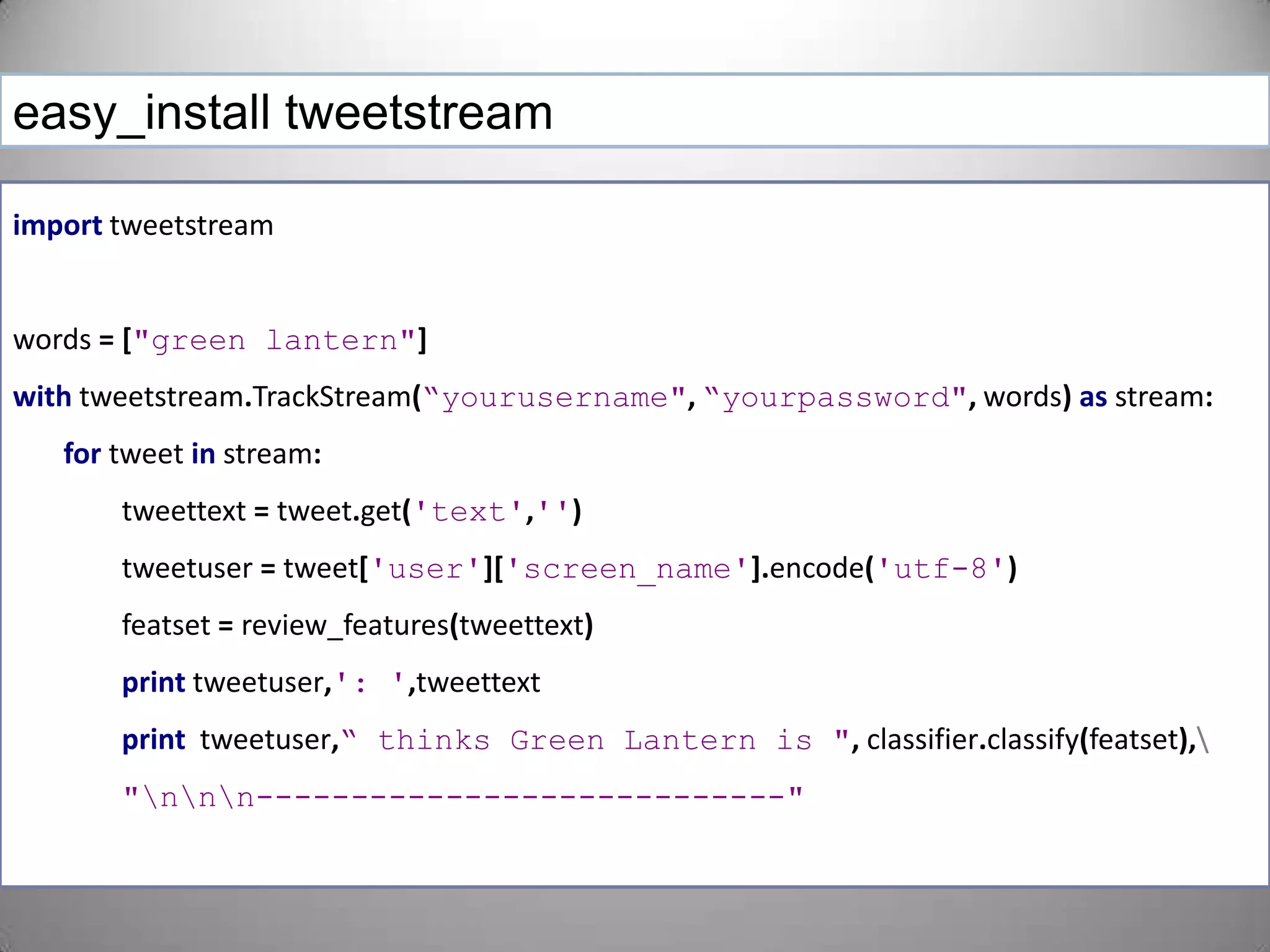
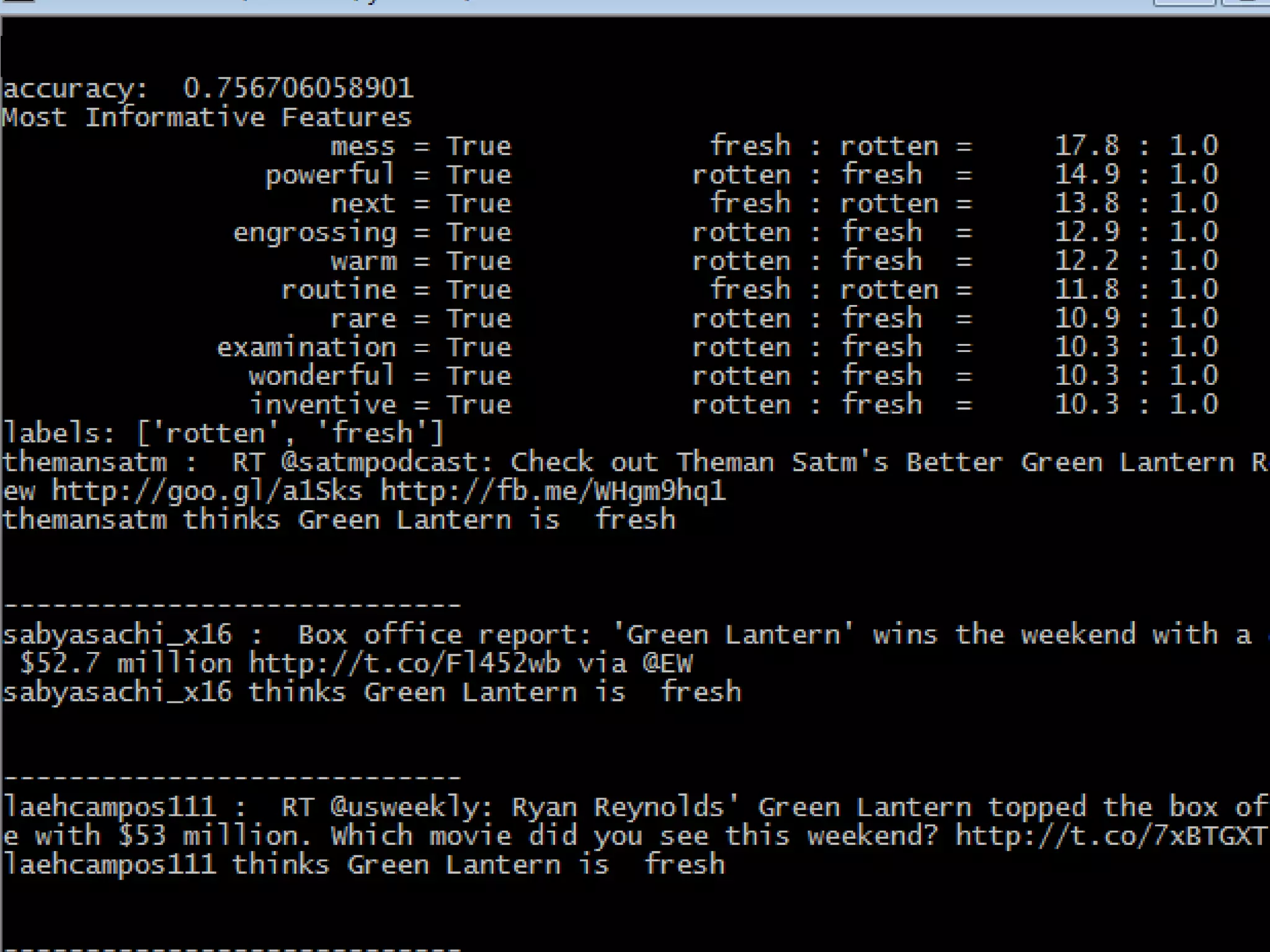

![easy_installtweetstreamimporttweetstreamwords=["green lantern"]withtweetstream.TrackStream(“yourusername",“yourpassword",words)asstream:fortweetinstream:tweettext=tweet.get('text','')tweetuser=tweet['user']['screen_name'].encode('utf-8')featset=review_features(tweettext)printtweetuser,': ',tweettextprinttweetuser,“ thinks Green Lantern is ",classifier.classify(featset),\"\n\n\n----------------------------"](https://image.slidesharecdn.com/nltktextanalytics4-110703155325-phpapp01/75/Nltk-Boston-Text-Analytics-48-2048.jpg)











































































