Downloaded 386 times





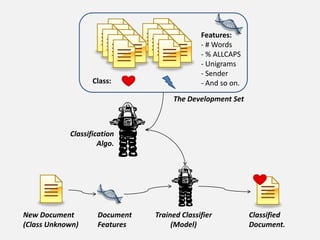







![Class[es] assigned for 1,000 randomly selected messages:](https://image.slidesharecdn.com/benhealeykiwipycon2011pressotexttospeech-110907030720-phpapp02/85/Document-Classification-using-the-Python-Natural-Language-Toolkit-14-320.jpg)
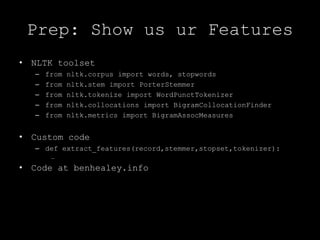
![Prep: Show us ur FeaturesFeatures in boolean or nominal formif record['num_words_in_body']<=20:features['message_length']='Very Short'elif record['num_words_in_body']<=80: features['message_length']='Short'elif record['num_words_in_body']<=300: features['message_length']='Medium'else: features['message_length']='Long'](https://image.slidesharecdn.com/benhealeykiwipycon2011pressotexttospeech-110907030720-phpapp02/85/Document-Classification-using-the-Python-Natural-Language-Toolkit-16-320.jpg)
![Prep: Show us ur FeaturesFeatures in boolean or nominal formtext=record['msg_subject']+" "+record['msg_body']tokens = tokenizer.tokenize(text)words = [stemmer.stem(x.lower()) for x in tokens if x not in stopset and len(x) > 1]for word in words: features[word]=True](https://image.slidesharecdn.com/benhealeykiwipycon2011pressotexttospeech-110907030720-phpapp02/85/Document-Classification-using-the-Python-Natural-Language-Toolkit-17-320.jpg)
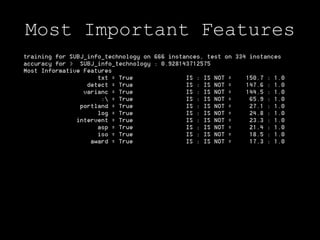
![Sit. Say. Heel.random.shuffle(dev_set)cutoff = len(dev_set)*2/3train_set=dev_set[:cutoff]test_set=dev_set[cutoff:]classifier = NaiveBayesClassifier.train(train_set)print 'accuracy for > ',subject,':', accuracy(classifier, test_set)classifier.show_most_informative_features(10)](https://image.slidesharecdn.com/benhealeykiwipycon2011pressotexttospeech-110907030720-phpapp02/85/Document-Classification-using-the-Python-Natural-Language-Toolkit-18-320.jpg)
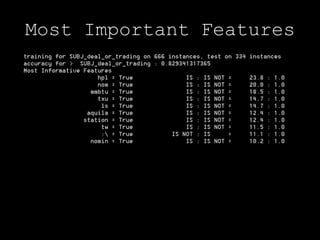
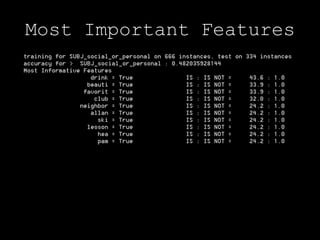
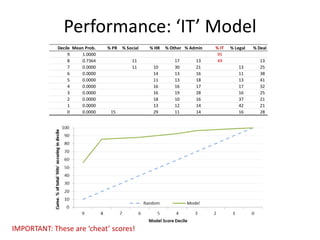
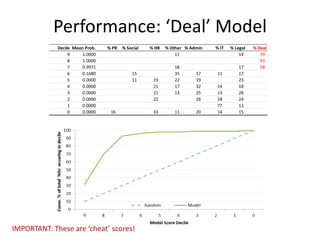
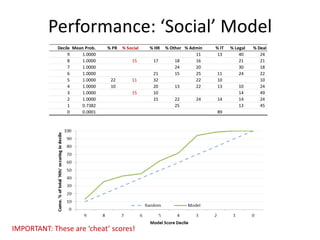



This document discusses document classification using the Natural Language Toolkit (NLTK). It describes extracting features from a dataset of Enron emails, training naive Bayes and decision tree classifiers on the features, and evaluating the classifiers' performance. Key steps include preprocessing the email data, extracting features like word counts and frequencies, training classifiers on a sample of the data, and measuring accuracy on a test set. The document cautions that the results demonstrate potential issues like biased samples and prior knowledge that require further iterative modeling.






















































































