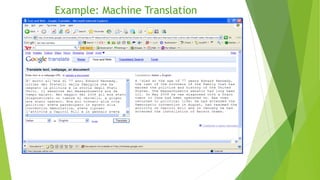
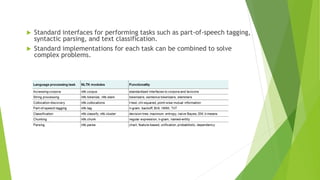
This document provides an introduction to natural language processing (NLP) and the Natural Language Toolkit (NLTK) module for Python. It discusses how NLP aims to develop systems that can understand human language at a deep level, lists common NLP applications, and explains why NLP is difficult due to language ambiguity and complexity. It then describes how corpus-based statistical approaches are used in NLTK to tackle NLP problems by extracting features from text corpora and using statistical models. The document gives an overview of the main NLTK modules and interfaces for common NLP tasks like tagging, parsing, and classification. It provides an example of word tokenization and discusses tokens and types in NLTK.
































































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)





![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)