The document introduces the Natural Language Toolkit (NLTK), an open-source library for natural language processing (NLP) in Python, covering topics such as Python data structures, NLP concepts, and functions of NLTK. It emphasizes various applications of NLP, including stemming, part-of-speech tagging, parsing, and the challenges associated with human language processing. Additionally, it outlines how to utilize corpora and modules in NLTK to work with text data for NLP tasks.







![List A list in Python is an ordered group of items (or elements ). It is a very general structure, and list elements don't have to be of the same type. listOfWords = [‘this’,’is’,’a’,’list’,’of’,’words’] listOfRandomStuff = [1,’pen’,’costs’,’Rs.’,6.50]](https://image.slidesharecdn.com/nltk-090308034532-phpapp02/85/NLTK-Natural-Language-Processing-made-easy-7-320.jpg)



![Sets Python also has an implementation of the mathematical set. Unlike sequence objects such as lists and tuples, in which each element is indexed, a set is an unordered collection of objects. Sets also cannot have duplicate members - a given object appears in a set 0 or 1 times. SetOfBrowsers=set([‘IE’,’Firefox’,’Opera’,’Chrome’])](https://image.slidesharecdn.com/nltk-090308034532-phpapp02/85/NLTK-Natural-Language-Processing-made-easy-11-320.jpg)























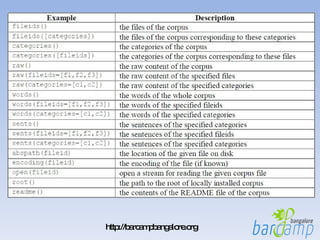
![Loading your own corpus >>> from nltk.corpus import PlaintextCorpusReader corpus_root = ‘C:\text\’ >>> wordlists = PlaintextCorpusReader(corpus_root, '.*‘) >>> wordlists.fileids() ['README', 'connectives', 'propernames', 'web2', 'web2a', 'words'] >>> wordlists.words('connectives') ['the', 'of', 'and', 'to', 'a', 'in', 'that', 'is', ...]](https://image.slidesharecdn.com/nltk-090308034532-phpapp02/85/NLTK-Natural-Language-Processing-made-easy-38-320.jpg)

![Computing with Language: Simple Statistics Frequency Distributions >>> fdist1 = FreqDist(text1) >>> fdist1 [2] <FreqDist with 260819 outcomes> >>> vocabulary1 = fdist1.keys() >>> vocabulary1[:50] [',', 'the', '.', 'of', 'and', 'a', 'to', ';', 'in', 'that', "'", '-', 'his', 'it', 'I', 's', 'is', 'he', 'with', 'was', 'as', '"', 'all', 'for', 'this', '!', 'at', 'by', 'but', 'not', '--', 'him', 'from', 'be', 'on', 'so', 'whale', 'one', 'you', 'had', 'have', 'there', 'But', 'or', 'were', 'now', 'which', '?', 'me', 'like'] >>> fdist1['whale'] 906](https://image.slidesharecdn.com/nltk-090308034532-phpapp02/85/NLTK-Natural-Language-Processing-made-easy-40-320.jpg)


















































![codin9cafe[2015.03. 18]Python learning for natural language processing - 홍은기(...](https://cdn.slidesharecdn.com/ss_thumbnails/pythonlearningfornaturallanguageprocessing-160712053838-thumbnail.jpg?width=640&height=640&fit=bounds)






















