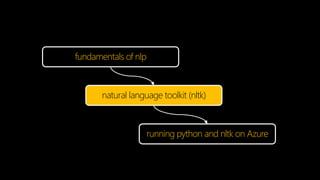
The document discusses large-scale natural language processing (NLP) using Python's NLTK on Azure, outlining the fundamental processes including language recognition, tokenization, and entity detection. It highlights the use of Azure's cloud services for running Python and NLTK jobs, detailing setup procedures like downloading necessary corpora and configuring web jobs. Additionally, it presents communication methods through queues and debugging strategies in both local and cloud environments.






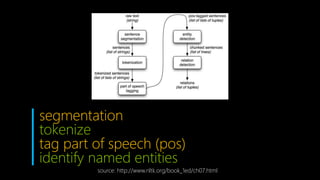

![text as a sequence of words and punctuation
represented as a list
sent = [‘I', ‘love', ‘Dublin', ‘!']
upper_sent = [w.upper() for w in sent]](https://image.slidesharecdn.com/largescalenlpusingpythonsnltkonazure-160507093517/85/Large-scale-nlp-using-python-s-nltk-on-azure-13-320.jpg)






![language recognition
import langid
lang = langid.classify(text)[0]](https://image.slidesharecdn.com/largescalenlpusingpythonsnltkonazure-160507093517/85/Large-scale-nlp-using-python-s-nltk-on-azure-22-320.jpg)



![configuration settings
key = os.environ["STORAGE_KEY"]](https://image.slidesharecdn.com/largescalenlpusingpythonsnltkonazure-160507093517/85/Large-scale-nlp-using-python-s-nltk-on-azure-27-320.jpg)


![downloading corpus
D:localAppDatanltk_data
if os.getenv("DOWNLOAD", True) == True :
dest = os.environ[“NLTK_DATA_DIR"]
nltk.download('all', dest)](https://image.slidesharecdn.com/largescalenlpusingpythonsnltkonazure-160507093517/85/Large-scale-nlp-using-python-s-nltk-on-azure-30-320.jpg)































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















