Recommended
PPT
PDF
PDF
PDF
PDF
PPTX
PDF
実践・最強最速のアルゴリズム勉強会 第一回 講義資料(ワークスアプリケーションズ & AtCoder)
PDF
PDF
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PDF
PDF
PDF
PDF
PDF
PDF
二部グラフの最小点被覆と最大安定集合と最小辺被覆の求め方
PDF
勉強か?趣味か?人生か?―プログラミングコンテストとは
PDF
PPL 2022 招待講演: 静的型つき函数型組版処理システムSATySFiの紹介
PPTX
PDF
PDF
RSA暗号運用でやってはいけない n のこと #ssmjp
PDF
PDF
PDF
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
PDF
PDF
PDF
More Related Content
PPT
PDF
PDF
PDF
PDF
PPTX
PDF
実践・最強最速のアルゴリズム勉強会 第一回 講義資料(ワークスアプリケーションズ & AtCoder)
PDF
What's hot
PDF
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PDF
PDF
PDF
PDF
PDF
PDF
二部グラフの最小点被覆と最大安定集合と最小辺被覆の求め方
PDF
勉強か?趣味か?人生か?―プログラミングコンテストとは
PDF
PPL 2022 招待講演: 静的型つき函数型組版処理システムSATySFiの紹介
PPTX
PDF
PDF
RSA暗号運用でやってはいけない n のこと #ssmjp
PDF
PDF
PDF
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
PDF
Similar to ダブル配列の実装方法
PDF
PDF
KEY
Algebraic DP: 動的計画法を書きやすく
PDF
PDF
PDF
PPTX
【DELPHI / C++BUILDER STARTER チュートリアルシリーズ】 シーズン2 Delphi の部 第5回 「配列 と レコード 」
PDF
PDF
PDF
PDF
programming camp 2008, introduction of programming, algorithm
PDF
PDF
PDF
PDF
プログラミング講座 #6 競プロのテクニック(初級)
PDF
PDF
アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]
PPT
CA Japan seminar CA Easytrieve updates 2012/6/5
PDF
2011.12.10 関数型都市忘年会 発表資料「最近書いた、関数型言語と関連する?C++プログラムの紹介」
PDF
ダブル配列の実装方法 1. 2. ダブル配列(Double Array)とは
• トライ木の実装方法の一つ
• トライ木とは?
• 大語彙で前方一致検索を高速に行うことが可能なデータ構造
• 例えば形態素解析、かな漢字変換で利用される
• どこが単語の始まりでどこが単語の終わりかわからない時に有用
ハッシュテーブルを使ってルックアップする方法の場合
単語境界がわからないので一文字づつ文字数を増やしてルックアップするしかない
最後までいったら開始点を1文字ずらして再度ルックアップ O(n^2) (入力文字数がn)
わ た し の な ま え は な か の で す 。
・・・
3. ダブル配列(Double Array)とは
• トライ木の実装方法の一つ
• トライ木とは?
• 大語彙で前方一致検索を高速に行うことが可能なデータ構造
• 例えば形態素解析、かな漢字変換で利用される
• どこが単語の始まりでどこが単語の終わりかわからない時に有用
正規表現を用いる方法
語彙数が少ない場合はこれでもそれほど遅くはない
現実は何十万語を使ってのルックアップ
$reg = /(和|輪綿|腸|私|わたし|野|の|名前|なまえ|名|中|野|仲|那賀|那加| ・・・
・・・
・・・
・・・
・・・|巣|す|酢)/;
入力文字数をn, 語彙数をm, 語彙の平均文字数をkとするとO(nmk)
トライを用いればO(nk)での計算が可能!
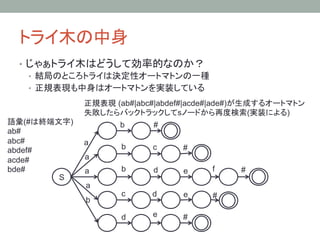
4. トライ木の中身
• じゃぁトライ木はどうして効率的なのか?
• 結局のところトライは決定性オートマトンの一種
• 正規表現も中身はオートマトンを実装している
正規表現 (ab#|abc#|abdef#|acde#|ade#)が生成するオートマトン
失敗したらバックトラックしてsノードから再度検索(実装による)
語彙(#は終端文字) b
#
ab#
abc# a
abdef# b
c
#
acde# a
bde#
a
b
d
e
f
#
S
a
c
d
e
#
b
d
e
#
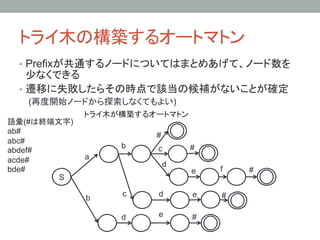
5. 6. トライ木の実装方法
遷移リストを用いた実装方法
状態遷移表を用いた実装方法
• 各ノードで遷移先ノードのポインタを • 各状態ごとに、ラベルに対応
保持 する遷移先ノード番号を保持
struct node { a
b
c
d
列:
ラベル
node *to; 1
2
×
4
×
char *labels; 2
×
×
3
×
} 3
×
×
×
◎
4
◎
×
×
×
問題点
行:ノード番号
遷移先ノードを線形探索して 問題点
調べるので遷移が遅い
遷移のない部分についても情報を保持
する必要があるためメモリを大量に消
費する
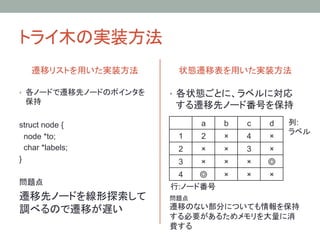
7. Double Arrayとは
• 状態遷移表を2つの配列(BASE, CHECK)に圧縮
状態遷移表で重要なのは以下の2種類
1. 遷移があるかないかという情報(CHECKで管理)
2. 遷移先のノード番号がどこかという情報(BASEで管理)
a
b
c
d
BASE配列
1
2
×
4
×
2
×
×
3
×
CHECK配列
3
×
×
×
◎
4
◎
×
×
×
状態遷移表の高速性を維持したままで、現実的なメモリ使用量での
探索が可能!
8. Double Arrayを使ったノード遷移アルゴリズム
1. 現在の状態番号(配列のインデックス 以下sとする)と入力文字を受け取る
2. 入力文字を文字コード表を用いて数字(以下cとする)に変換
(実装上はunsigned char, 終端記号はヌル文字を用いることが多い)
3. 次の状態番号(以下tとする)を下記の計算式で計算
t = base[s] + c
4. CHECK[t]が元の状態番号sと等しいか確認する
一致すれば遷移成功
文字コード表
a
b
c
d
e
#
例) 現在の状態番号を6 入力文字をaとする
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
0
0
0
0
0
8
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
6
2
0
0
0
0
0
0
9. Double Arrayを使ったノード遷移アルゴリズム
1. 現在の状態番号(配列のインデックス 以下sとする)と入力文字を受け取る
2. 入力文字を文字コード表を用いて数字(以下cとする)に変換
(実装上はunsigned char, 終端記号はヌル文字を用いることが多い)
3. 次の状態番号(以下tとする)を下記の計算式で計算
t = base[s] + c
4. CHECK[t]が元の状態番号sと等しいか確認する
一致すれば遷移成功
文字コード表
a
b
c
d
e
#
例) 現在の状態番号を6 入力文字をaとする
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
0
0
0
0
0
8
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
6
2
0
0
0
0
0
0
t = BASE[6] + 1 = 8 + 1 = 9
10. Double Arrayを使ったノード遷移アルゴリズム
1. 現在の状態番号(配列のインデックス 以下sとする)と入力文字を受け取る
2. 入力文字を文字コード表を用いて数字(以下cとする)に変換
(実装上はunsigned char, 終端記号はヌル文字を用いることが多い)
3. 次の状態番号(以下tとする)を下記の計算式で計算
t = base[s] + c
4. CHECK[t]が元の状態番号sと等しいか確認する
一致すれば遷移成功
文字コード表
a
b
c
d
e
#
例) 現在の状態番号を6 入力文字をaとする
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
0
0
0
0
0
8
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
6
2
0
0
0
0
0
0
t = BASE[6] + 1 = 8 + 1 = 9
11. Double Arrayを使ったノード遷移アルゴリズム
1. 現在の状態番号(配列のインデックス 以下sとする)と入力文字を受け取る
2. 入力文字を文字コード表を用いて数字(以下cとする)に変換
(実装上はunsigned char, 終端記号はヌル文字を用いることが多い)
3. 次の状態番号(以下tとする)を下記の計算式で計算
t = base[s] + c
4. CHECK[t]が元の状態番号sと等しいか確認する
一致すれば遷移成功
文字コード表
a
b
c
d
e
#
例) 現在の状態番号を6 入力文字をaとする
CHECK[9] =1
2
3
4
5
6
6なので
インデックス
1
2
3
4
5
6
7
8
9
遷移成功!
10
11
12
13
14
15
16
BASE
0
0
0
0
0
8
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
6
2
0
0
0
0
0
0
t = BASE[6] + 1 = 8 + 1 = 9
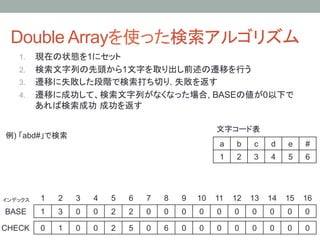
12. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
13. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[1] + N(a) = 1 + 1 = 2
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
14. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
一致!
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
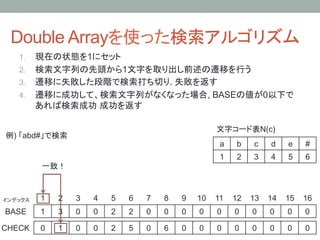
15. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[2] + N(b) = 3 + 2 = 5
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
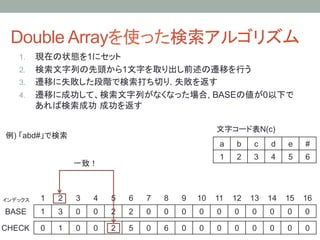
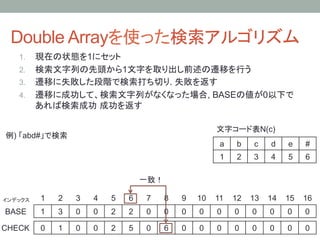
16. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
一致!
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
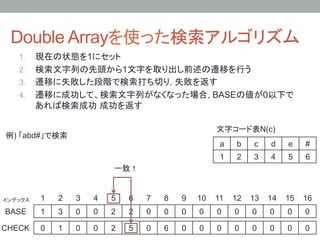
17. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[5] + N(d) = 2 + 4 = 6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
18. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
一致!
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
19. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[6] + N(#) = 2 + 6 = 8
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
20. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
一致!
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
21. Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[8] <= 0なので遷移なし 検索成功!
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0
22. Double Arrayの構築方法
1. 二つの配列は全て0で初期化する
2. 語彙を一つ一つ順次挿入していく(挿入アルゴリズムは後述)
3. 全ての語彙を挿入し終わった時点で構築終了
実用上、語彙は挿入前に全てsortしておくと、再配置が少なくなるため高速に
構築可能となる
また、静的構築の場合、より高速に構築する手法もある。
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
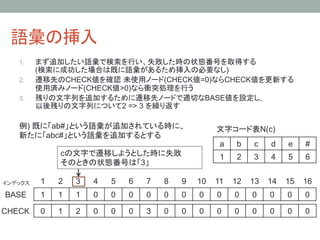
23. 語彙の挿入
1. まず追加したい語彙で検索を行い、失敗した時の状態番号を取得する
(検索に成功した場合は既に語彙があるため挿入の必要なし)
2. 遷移先のCHECK値を確認 未使用ノード(CHECK値=0)ならCHECK値を更新する
使用済みノード(CHECK値>0)なら衝突処理を行う
3. 残りの文字列を追加するために遷移先ノードで適切なBASE値を設定し,
以後残りの文字列について2 => 3 を繰り返す
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
1
2
3
4
5
6
「ab#」が追加された状態のDouble Array
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
0
0
0
3
0
0
0
0
0
0
0
0
0
24. 語彙の挿入
1. まず追加したい語彙で検索を行い、失敗した時の状態番号を取得する
(検索に成功した場合は既に語彙があるため挿入の必要なし)
2. 遷移先のCHECK値を確認 未使用ノード(CHECK値=0)ならCHECK値を更新する
使用済みノード(CHECK値>0)なら衝突処理を行う
3. 残りの文字列を追加するために遷移先ノードで適切なBASE値を設定し,
以後残りの文字列について2 => 3 を繰り返す
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
cの文字で遷移しようとした時に失敗 1
2
3
4
5
6
そのときの状態番号は「3」
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
0
0
0
3
0
0
0
0
0
0
0
0
0
25. 語彙の挿入
1. まず追加したい語彙で検索を行い、失敗した時の状態番号を取得する
(検索に成功した場合は既に語彙があるため挿入の必要なし)
2. 遷移先のCHECK値を確認 未使用ノード(CHECK値=0)ならCHECK値を更新する
使用済みノード(CHECK値>0)なら衝突処理を行う
3. 残りの文字列を追加するために遷移先ノードで適切なBASE値を設定し,
以後残りの文字列について2 => 3 を繰り返す
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
現在のBASE値から次の状態を計算
t = BASE[3] + N(c) = 1 + 3 = 4
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
0
0
0
3
0
0
0
0
0
0
0
0
0
26. 語彙の挿入(CHECKの設定)
1. まず追加したい語彙で検索を行い、失敗した時の状態番号を取得する
(検索に成功した場合は既に語彙があるため挿入の必要なし)
2. 遷移先のCHECK値を確認 未使用ノード(CHECK値=0)ならCHECK値を更新する
使用済みノード(CHECK値>0)なら衝突処理を行う
3. 残りの文字列を追加するために遷移先ノードで適切なBASE値を設定し,
以後残りの文字列について2 => 3 を繰り返す
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
CHECK[4] <= 0より未使用ノードなので
CHECK[4] = 3を設定 1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0
27. 語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
1 + N(#) = 7
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0
28. 語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
CHECK[7] > 0のため
使用済み要素
BASE値=1は不適
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0
29. 語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
2 + N(#) = 8
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0
30. 語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
CHECK[8] <= 0のため
未使用ノード
BASE値=2はOK
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0
31. 語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
BASE[4] = 2を設定
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0
32. 語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
CHECK[BASE[4]+6] = CHECK[8] = 4 を設定
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0
33. 語彙の挿入(完了)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
1
2
3
4
5
6
「abc#」全ての遷移のBASE, CHECK値の挿入が
完了したので挿入操作終了
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0
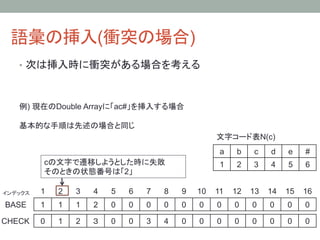
34. 語彙の挿入(衝突の場合)
• 次は挿入時に衝突がある場合を考える
例) 現在のDouble Arrayに「ac#」を挿入する場合
基本的な手順は先述の場合と同じ
文字コード表N(c)
a
b
c
d
e
#
cの文字で遷移しようとした時に失敗 1
2
3
4
5
6
そのときの状態番号は「2」
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0
35. 語彙の挿入(衝突の場合)
例) 現在のDouble Arrayに「ac#」を挿入する場合
基本的な手順は先述の場合と同じ
文字コード表N(c)
現在のBASE値から遷移先を計算
a
b
c
d
e
#
t = BASE[2] + N(c) = 1 + 3 = 4
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0
36. 語彙の挿入(衝突の場合)
例) 現在のDouble Arrayに「ac#」を挿入する場合
基本的な手順は先述の場合と同じ
文字コード表N(c)
a
b
c
d
e
#
CHECK[4] > 0のため 1
2
3
4
5
6
使用済みノード
BASE[2]の再設定が必要となる
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0
37. 語彙の挿入(衝突処理)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
衝突処理
1. 現在のノード番号から遷移している全てのラベル(文字)を取得
2. 全てのラベルが遷移可能なBASE値及び上記ラベルの新しい遷移先を求める
3. 上記ラベルについて、それぞれ古い遷移先のBASE値を新しい遷移先にコピー
4. 古い遷移先のさらに遷移される先のCHECK値も新しい遷移先に更新
5. 各ラベルの古い遷移先のノードを未使用状態に初期化
文字コード表N(c)
a
b
c
d
e
#
1
2
3
4
5
6
現在注目中のノード
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0
38. 語彙の挿入(衝突処理)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
遷移ラベル(文字)の取得
これは「CHECK[i] = 現在のノード番号」となる
ノードを線形探索すればいい
下記の図の場合「3」が該当する
文字コード表N(c)
a
b
c
d
e
#
1
2
3
4
5
6
b
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0
39. 語彙の挿入(衝突処理)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
BASE値の決定
新しいBASE[2]の値として「b」「c」の2文字が遷移可能な
BASE値を探す
手順については先述と同様 複数の遷移ラベルで確認する必要があることに注意
結果、新しいBASE値3が求まる
今までのBASE[2] = 1を一時変数に保存し、
BASE[2] = 3を設定する
文字コード表N(c)
b
a
b
c
d
e
#
1
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0
40. 語彙の挿入(衝突処理)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
遷移先CHECK値の更新
「b」「c」の新しい遷移先でCHECK値を設定する
「b」の新しい遷移先は5
「c」の遷移先は6
文字コード表N(c)
b
a
b
c
d
e
#
1
1
2
3
4
5
6
b
c
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
2
2
3
4
0
0
0
0
0
0
0
0
41. 語彙の挿入(衝突処理 辻褄合わせ)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
元遷移先のBASE値コピー
「b」の元遷移先「3」のBASE値を, 新しい遷移先「5」のBASE値ににコピー
文字コード表N(c)
a
b
c
d
e
#
b
1
2
3
4
5
6
1
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
1
2
1
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
2
2
3
4
0
0
0
0
0
0
0
0
42. 語彙の挿入(衝突処理 辻褄合わせ)
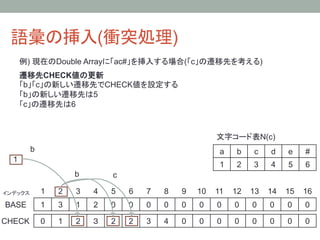
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
元遷移先からさらに遷移されるノードを確認
コピー元のBASE値が0より大きければ、
bの元遷移先「3」からさらに遷移した先が存在するので確認
(先ほどと同様に線形探索を行いCHECK[i] = 3となるノードを探す)
文字コード表N(c)
a
b
c
d
e
#
bの元遷移先
# bの新しい遷移先
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
1
2
1
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
2
2
3
4
0
0
0
0
0
0
0
0
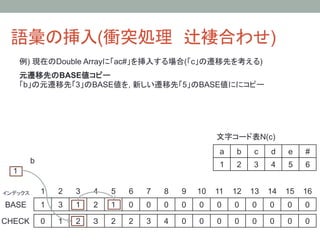
43. 語彙の挿入(衝突処理 辻褄合わせ)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
元遷移先からさらに遷移される先のCHECK値を更新
新しい遷移先5からの状態遷移となるため, CHECK[7] = 5 に更新
文字コード表N(c)
a
b
c
d
e
#
bの元遷移先
bの新しい遷移先
1
2
3
4
5
6
#
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
1
2
1
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
2
2
5
4
0
0
0
0
0
0
0
0
44. 語彙の挿入(衝突処理 辻褄合わせ)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
元遷移先を初期化
bの元遷移先を未使用ノードに設定
文字コード表N(c)
a
b
c
d
e
#
bの元遷移先
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
2
1
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
3
2
2
5
4
0
0
0
0
0
0
0
0
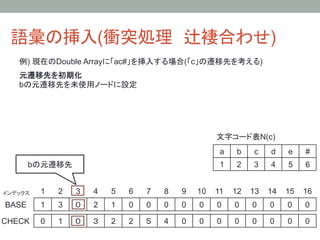
45. 語彙の挿入(残りの文字列の挿入)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「#」の遷移先を考える)
残りの文字列の挿入
残りの文字は「#」のみのため「#」を挿入すれば「ac#」の挿入処理は完了する
現在「c」で遷移した状態番号は「6」
BASE値を同様の手順で求めBASE[6] = 3を設定する
遷移先tはt = BASE[6] + N(#) = 3 + 6 = 9となるので
CHECK[9] = 6を設定する
文字コード表N(c)
a
b
c
d
e
#
cの遷移先
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
2
1
3
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
3
2
2
5
4
6
0
0
0
0
0
0
0
46.




![Double Arrayを使ったノード遷移アルゴリズム
1. 現在の状態番号(配列のインデックス 以下sとする)と入力文字を受け取る
2. 入力文字を文字コード表を用いて数字(以下cとする)に変換
(実装上はunsigned char, 終端記号はヌル文字を用いることが多い)
3. 次の状態番号(以下tとする)を下記の計算式で計算
t = base[s] + c
4. CHECK[t]が元の状態番号sと等しいか確認する
一致すれば遷移成功
文字コード表
a
b
c
d
e
#
例) 現在の状態番号を6 入力文字をaとする
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
0
0
0
0
0
8
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
6
2
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-8-320.jpg)
![Double Arrayを使ったノード遷移アルゴリズム
1. 現在の状態番号(配列のインデックス 以下sとする)と入力文字を受け取る
2. 入力文字を文字コード表を用いて数字(以下cとする)に変換
(実装上はunsigned char, 終端記号はヌル文字を用いることが多い)
3. 次の状態番号(以下tとする)を下記の計算式で計算
t = base[s] + c
4. CHECK[t]が元の状態番号sと等しいか確認する
一致すれば遷移成功
文字コード表
a
b
c
d
e
#
例) 現在の状態番号を6 入力文字をaとする
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
0
0
0
0
0
8
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
6
2
0
0
0
0
0
0
t = BASE[6] + 1 = 8 + 1 = 9](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-9-320.jpg)
![Double Arrayを使ったノード遷移アルゴリズム
1. 現在の状態番号(配列のインデックス 以下sとする)と入力文字を受け取る
2. 入力文字を文字コード表を用いて数字(以下cとする)に変換
(実装上はunsigned char, 終端記号はヌル文字を用いることが多い)
3. 次の状態番号(以下tとする)を下記の計算式で計算
t = base[s] + c
4. CHECK[t]が元の状態番号sと等しいか確認する
一致すれば遷移成功
文字コード表
a
b
c
d
e
#
例) 現在の状態番号を6 入力文字をaとする
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
0
0
0
0
0
8
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
6
2
0
0
0
0
0
0
t = BASE[6] + 1 = 8 + 1 = 9](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-10-320.jpg)
![Double Arrayを使ったノード遷移アルゴリズム
1. 現在の状態番号(配列のインデックス 以下sとする)と入力文字を受け取る
2. 入力文字を文字コード表を用いて数字(以下cとする)に変換
(実装上はunsigned char, 終端記号はヌル文字を用いることが多い)
3. 次の状態番号(以下tとする)を下記の計算式で計算
t = base[s] + c
4. CHECK[t]が元の状態番号sと等しいか確認する
一致すれば遷移成功
文字コード表
a
b
c
d
e
#
例) 現在の状態番号を6 入力文字をaとする
CHECK[9] =1
2
3
4
5
6
6なので
インデックス
1
2
3
4
5
6
7
8
9
遷移成功!
10
11
12
13
14
15
16
BASE
0
0
0
0
0
8
0
0
0
0
0
0
0
0
0
0
CHECK
0
0
0
0
0
0
0
0
6
2
0
0
0
0
0
0
t = BASE[6] + 1 = 8 + 1 = 9](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-11-320.jpg)
![Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[1] + N(a) = 1 + 1 = 2
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-13-320.jpg)
![Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[2] + N(b) = 3 + 2 = 5
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-15-320.jpg)
![Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[5] + N(d) = 2 + 4 = 6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-17-320.jpg)
![Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[6] + N(#) = 2 + 6 = 8
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-19-320.jpg)
![Double Arrayを使った検索アルゴリズム
1. 現在の状態を1にセット
2. 検索文字列の先頭から1文字を取り出し前述の遷移を行う
3. 遷移に失敗した段階で検索打ち切り. 失敗を返す
4. 遷移に成功して、検索文字列がなくなった場合, BASEの値が0以下で
あれば検索成功 成功を返す
文字コード表N(c)
例) 「abd#」で検索
a
b
c
d
e
#
1
2
3
4
5
6
BASE[8] <= 0なので遷移なし 検索成功!
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
0
2
2
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
0
2
5
0
6
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-21-320.jpg)


![語彙の挿入
1. まず追加したい語彙で検索を行い、失敗した時の状態番号を取得する
(検索に成功した場合は既に語彙があるため挿入の必要なし)
2. 遷移先のCHECK値を確認 未使用ノード(CHECK値=0)ならCHECK値を更新する
使用済みノード(CHECK値>0)なら衝突処理を行う
3. 残りの文字列を追加するために遷移先ノードで適切なBASE値を設定し,
以後残りの文字列について2 => 3 を繰り返す
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
現在のBASE値から次の状態を計算
t = BASE[3] + N(c) = 1 + 3 = 4
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
0
0
0
3
0
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-25-320.jpg)
![語彙の挿入(CHECKの設定)
1. まず追加したい語彙で検索を行い、失敗した時の状態番号を取得する
(検索に成功した場合は既に語彙があるため挿入の必要なし)
2. 遷移先のCHECK値を確認 未使用ノード(CHECK値=0)ならCHECK値を更新する
使用済みノード(CHECK値>0)なら衝突処理を行う
3. 残りの文字列を追加するために遷移先ノードで適切なBASE値を設定し,
以後残りの文字列について2 => 3 を繰り返す
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
CHECK[4] <= 0より未使用ノードなので
CHECK[4] = 3を設定 1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-26-320.jpg)
![語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
1 + N(#) = 7
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-27-320.jpg)
![語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
CHECK[7] > 0のため
使用済み要素
BASE値=1は不適
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-28-320.jpg)
![語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
2 + N(#) = 8
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-29-320.jpg)
![語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
CHECK[8] <= 0のため
未使用ノード
BASE値=2はOK
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-30-320.jpg)
![語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
BASE[4] = 2を設定
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
0
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-31-320.jpg)
![語彙の挿入(BASEの設定)
例) 既に「ab#」という語彙が追加されている時に、 文字コード表N(c)
新たに「abc#」という語彙を追加するとする
a
b
c
d
e
#
BASE値は、下記の手順で求める 1
2
3
4
5
6
(入力 現在の状態番号, 遷移文字)
1. BASE値の初期値を1に設定
2. 現在のBASE値で遷移先ノードを計算
遷移先ノードのCHECK値を確認して、未使用ノードなら3へ
使用済みノードであればBASE値をインクリメントして再度2を実行
3. BASE値をBASE[現在の状態番号]に設定
4. CHECK[遷移先ノード]に現在の状態番号を設定
CHECK[BASE[4]+6] = CHECK[8] = 4 を設定
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-32-320.jpg)

![語彙の挿入(衝突の場合)
例) 現在のDouble Arrayに「ac#」を挿入する場合
基本的な手順は先述の場合と同じ
文字コード表N(c)
現在のBASE値から遷移先を計算
a
b
c
d
e
#
t = BASE[2] + N(c) = 1 + 3 = 4
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-35-320.jpg)
![語彙の挿入(衝突の場合)
例) 現在のDouble Arrayに「ac#」を挿入する場合
基本的な手順は先述の場合と同じ
文字コード表N(c)
a
b
c
d
e
#
CHECK[4] > 0のため 1
2
3
4
5
6
使用済みノード
BASE[2]の再設定が必要となる
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-36-320.jpg)

![語彙の挿入(衝突処理)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
遷移ラベル(文字)の取得
これは「CHECK[i] = 現在のノード番号」となる
ノードを線形探索すればいい
下記の図の場合「3」が該当する
文字コード表N(c)
a
b
c
d
e
#
1
2
3
4
5
6
b
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
1
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-38-320.jpg)
![語彙の挿入(衝突処理)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
BASE値の決定
新しいBASE[2]の値として「b」「c」の2文字が遷移可能な
BASE値を探す
手順については先述と同様 複数の遷移ラベルで確認する必要があることに注意
結果、新しいBASE値3が求まる
今までのBASE[2] = 1を一時変数に保存し、
BASE[2] = 3を設定する
文字コード表N(c)
b
a
b
c
d
e
#
1
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
1
2
0
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
0
0
3
4
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-39-320.jpg)
![語彙の挿入(衝突処理 辻褄合わせ)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
元遷移先からさらに遷移されるノードを確認
コピー元のBASE値が0より大きければ、
bの元遷移先「3」からさらに遷移した先が存在するので確認
(先ほどと同様に線形探索を行いCHECK[i] = 3となるノードを探す)
文字コード表N(c)
a
b
c
d
e
#
bの元遷移先
# bの新しい遷移先
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
1
2
1
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
2
2
3
4
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-42-320.jpg)
![語彙の挿入(衝突処理 辻褄合わせ)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「c」の遷移先を考える)
元遷移先からさらに遷移される先のCHECK値を更新
新しい遷移先5からの状態遷移となるため, CHECK[7] = 5 に更新
文字コード表N(c)
a
b
c
d
e
#
bの元遷移先
bの新しい遷移先
1
2
3
4
5
6
#
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
1
2
1
0
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
2
3
2
2
5
4
0
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-43-320.jpg)
![語彙の挿入(残りの文字列の挿入)
例) 現在のDouble Arrayに「ac#」を挿入する場合(「#」の遷移先を考える)
残りの文字列の挿入
残りの文字は「#」のみのため「#」を挿入すれば「ac#」の挿入処理は完了する
現在「c」で遷移した状態番号は「6」
BASE値を同様の手順で求めBASE[6] = 3を設定する
遷移先tはt = BASE[6] + N(#) = 3 + 6 = 9となるので
CHECK[9] = 6を設定する
文字コード表N(c)
a
b
c
d
e
#
cの遷移先
1
2
3
4
5
6
インデックス
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
BASE
1
3
0
2
1
3
0
0
0
0
0
0
0
0
0
0
CHECK
0
1
0
3
2
2
5
4
6
0
0
0
0
0
0
0](https://image.slidesharecdn.com/random-110731112237-phpapp02/85/slide-45-320.jpg)













































![アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]](https://cdn.slidesharecdn.com/ss_thumbnails/random-160606142552-thumbnail.jpg?width=640&height=640&fit=bounds)


