More Related Content

PDF
文法圧縮入門:超高速テキスト処理のためのデータ圧縮(NLP2014チュートリアル) 
PDF

PDF
Data-Intensive Text Processing with MapReduce ch4 
PDF
ディープラーニングフレームワーク とChainerの実装 
PDF

PDF

PDF

PDF
20180830 implement dqn_platinum_data_meetup_vol1 What's hot
![[DLHacks]Fast and Accurate Entity Recognition with Iterated Dilated Convoluti...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-180604045159-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DLHacks]Fast and Accurate Entity Recognition with Iterated Dilated Convoluti... 
PDF

PDF

PDF

PPTX

PDF

PDF
あなたのScalaを爆速にする7つの方法(日本語版) 
PDF

PDF

PDF

PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜 Viewers also liked

PPTX
今さら聞けないHadoop勉強会第3回 セントラルソフト株式会社(20120327) 
PDF

PDF
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会) 
PDF

PDF
Devsumi2010-01-Suc3rum-20100218 
PPTX
今さら聞けないHadoop セントラルソフト株式会社(20120119) 
PDF
Similar to 今さら聞けないHadoop勉強会第2回 セントラルソフト株式会社(20120228)

PDF

PDF
MapReduceによる大規模データを利用した機械学習 
PDF
CloudSpiral 2014年度 ビッグデータ講義 
PDF
Data-Intensive Text Processing with MapReduce(Ch1,Ch2) 
PDF
OSC2011 Tokyo/Spring Hadoop入門 
PPTX
Nttr study 20130206_share 
PDF

PDF

PPT

PDF
PFI Christmas seminar 2009 
PDF

PDF

PDF

PDF

PDF

PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料) 
PDF
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter) 
PPTX

PDF

PPTX
今さら聞けないHadoop勉強会第2回 セントラルソフト株式会社(20120228)
- 1.
- 2.
- 3.
本セミナーの目的
Hadoop に関連する技術や培ったノウハウを、勉強会に参加された方
と
共有する SlideShare で公開
「今さら聞けないhadoop セントラ
ルソフト」で見つかります
スケジュール
第1回 Hadoop 基礎(1月19日開催)
HDFS と MapReduce の概念
ロールプレイ
第2回 アルゴリズム(本日2月28日開催)
k-means アルゴリズム
TF-IDF アルゴリズム
第3回 「MapReduce 実装テクニック」を予定(3月予定)
ワードカウント
k-means
TF-IDF
第4回 「理論・エコシステム編」を予定(4月予定)
HDFS
HBase
Hive
3
- 4.
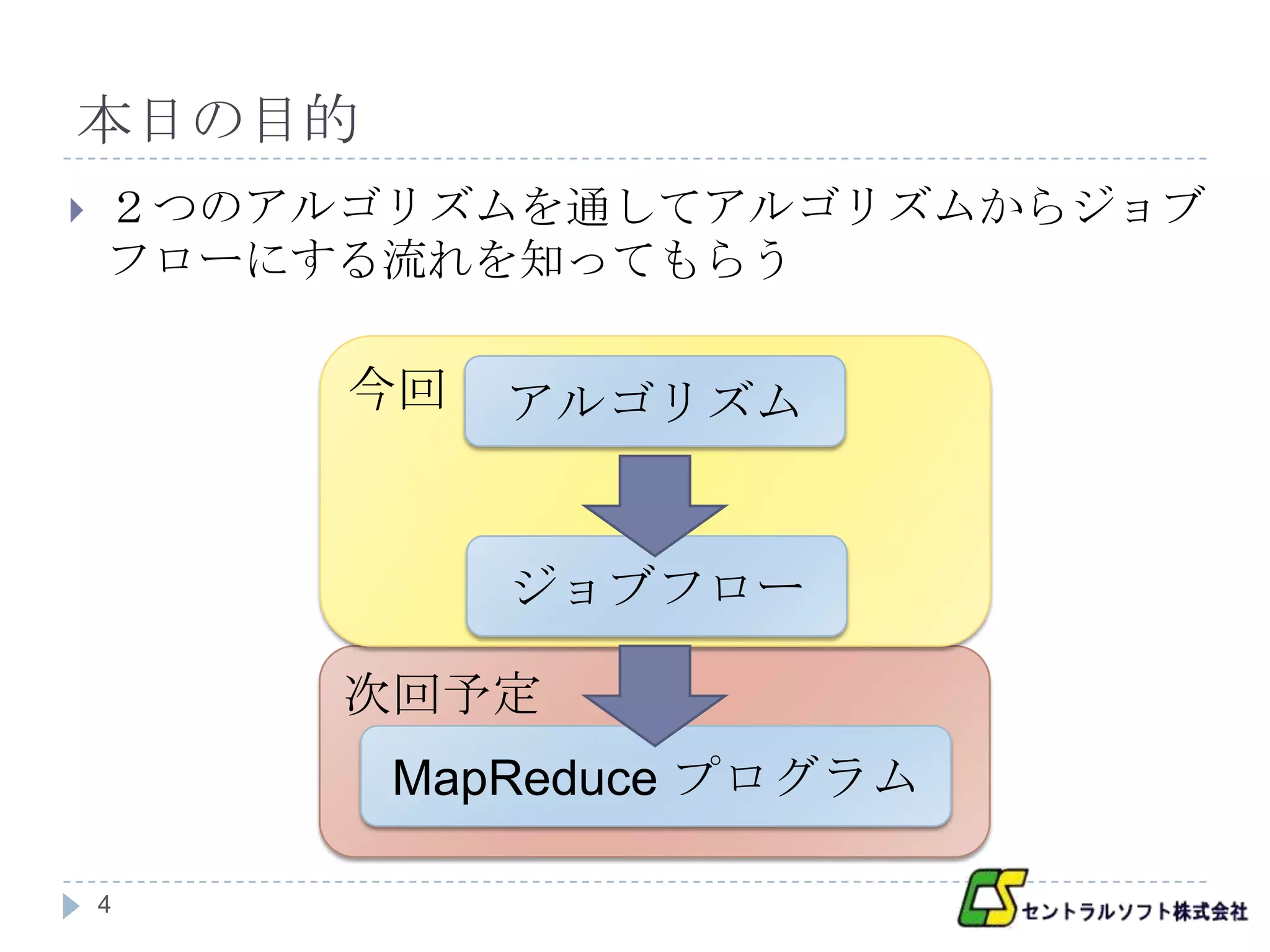
本日の目的
2つのアルゴリズムを通してアルゴリズムからジョブ
フローにする流れを知ってもらう
今回 アルゴリズム
ジョブフロー
次回予定
MapReduce プログラム
4
- 5.
目次
k-means アルゴリズム
アルゴリズムからジョブフローへ
TF-IDF アルゴリズム
アルゴリズムからジョブフローへ
まとめと次回の予定
5
- 6.
- 7.
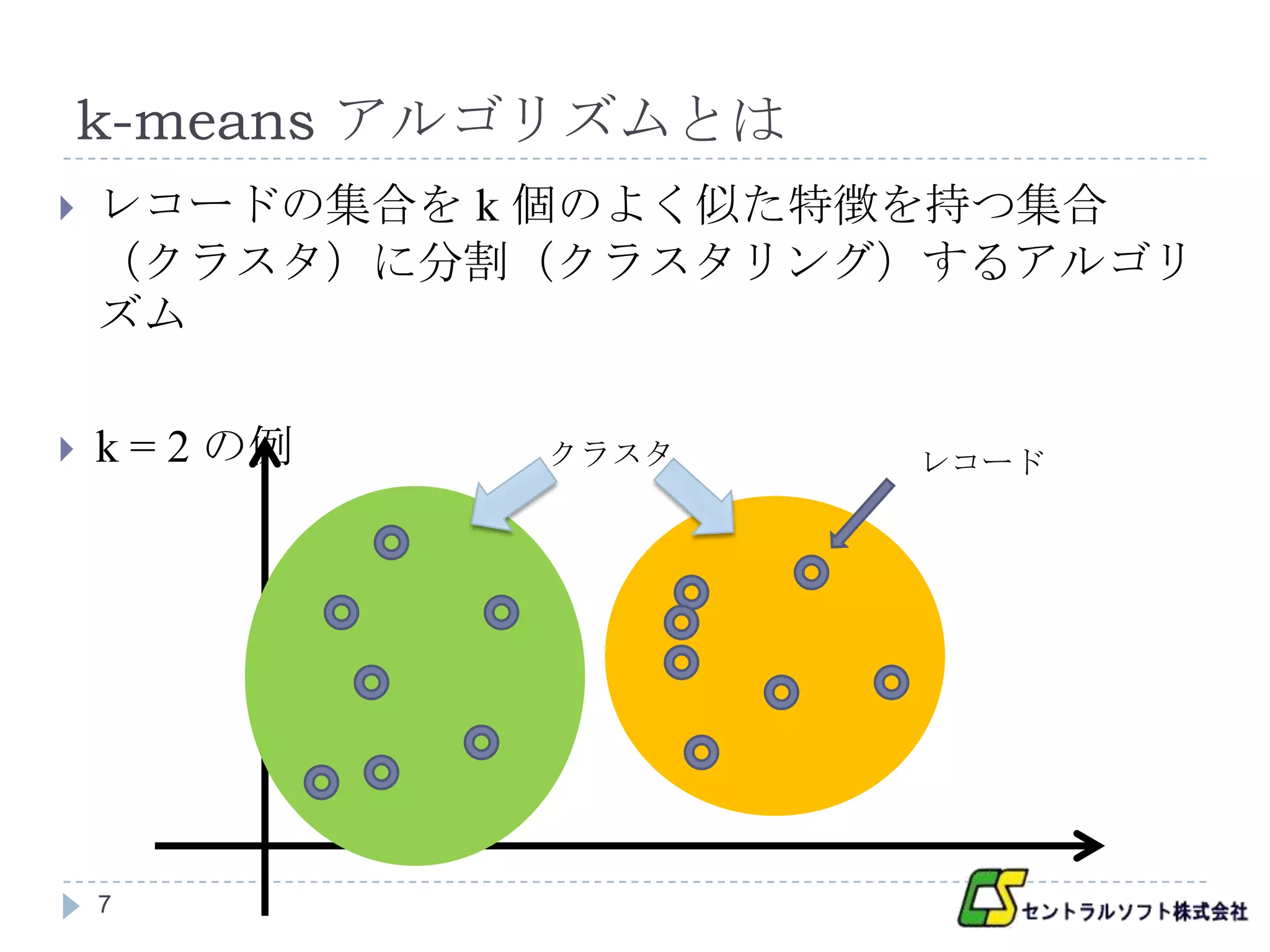
k-means アルゴリズムとは
レコードの集合を k 個のよく似た特徴を持つ集合
(クラスタ)に分割(クラスタリング)するアルゴリ
ズム
k = 2 の例 クラスタ レコード
7
- 8.
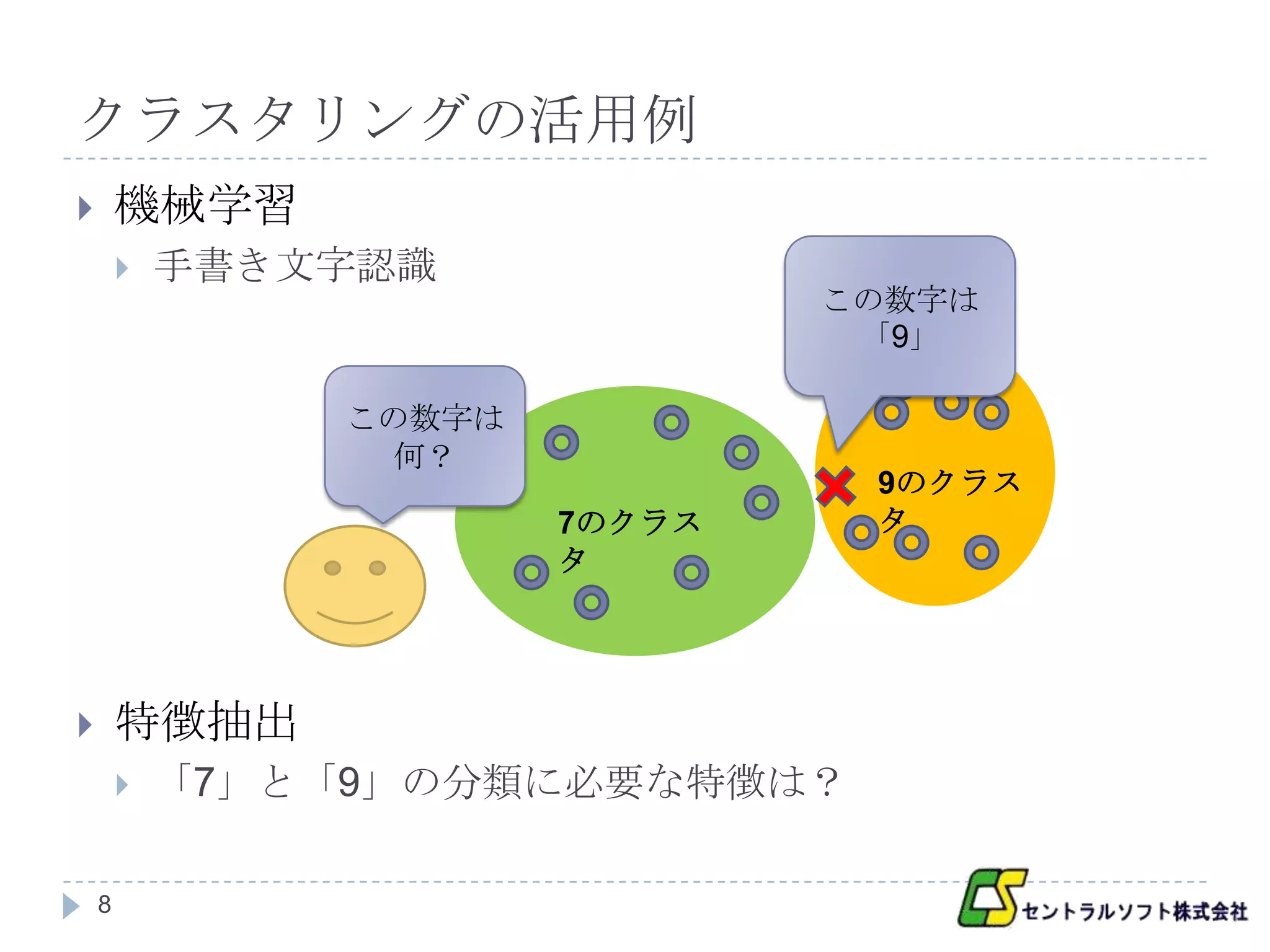
クラスタリングの活用例
機械学習
手書き文字認識
この数字は
「9」
この数字は
何?
9のクラス
7のクラス タ
タ
特徴抽出
「7」と「9」の分類に必要な特徴は?
8
- 9.
- 10.
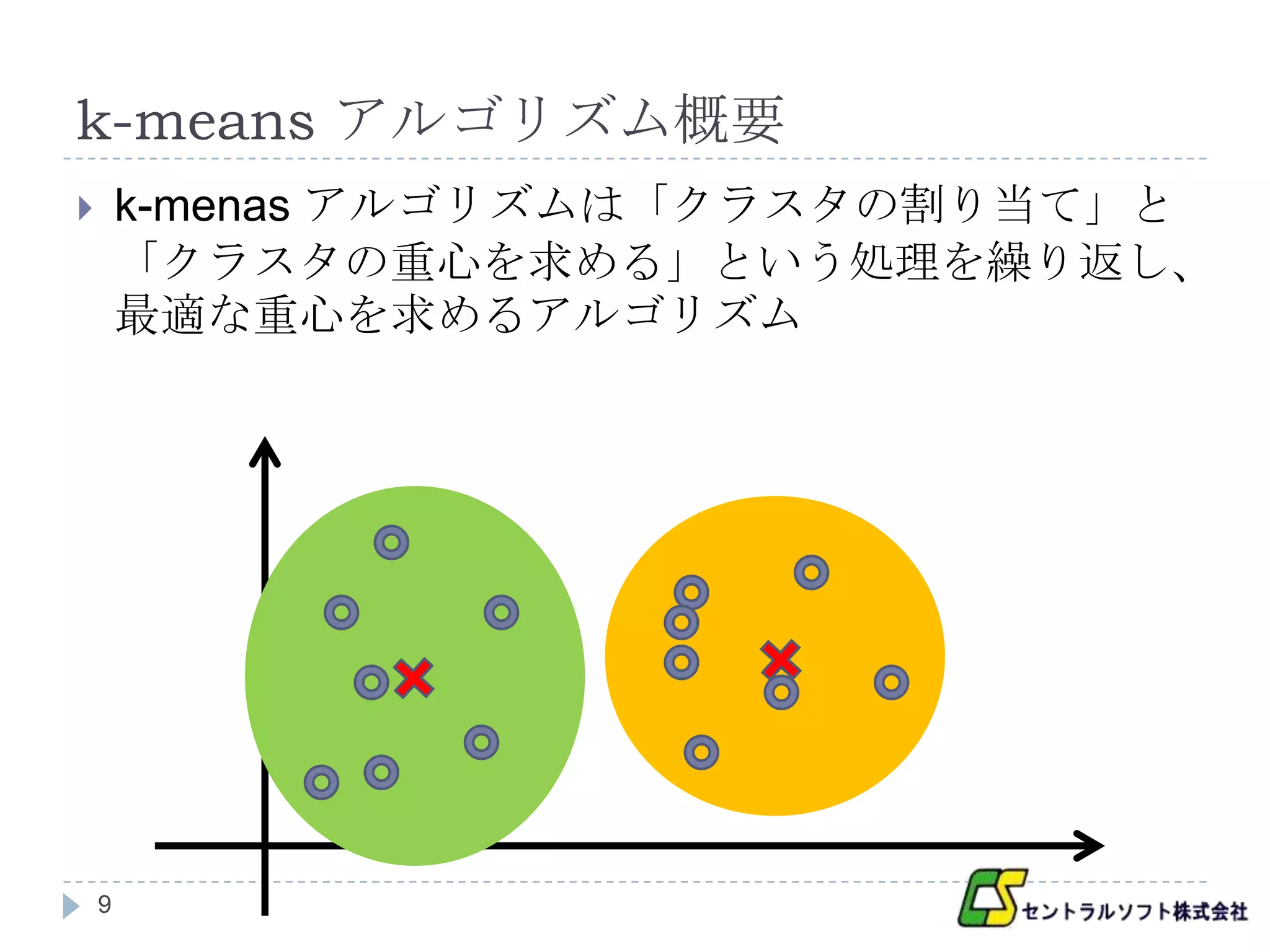
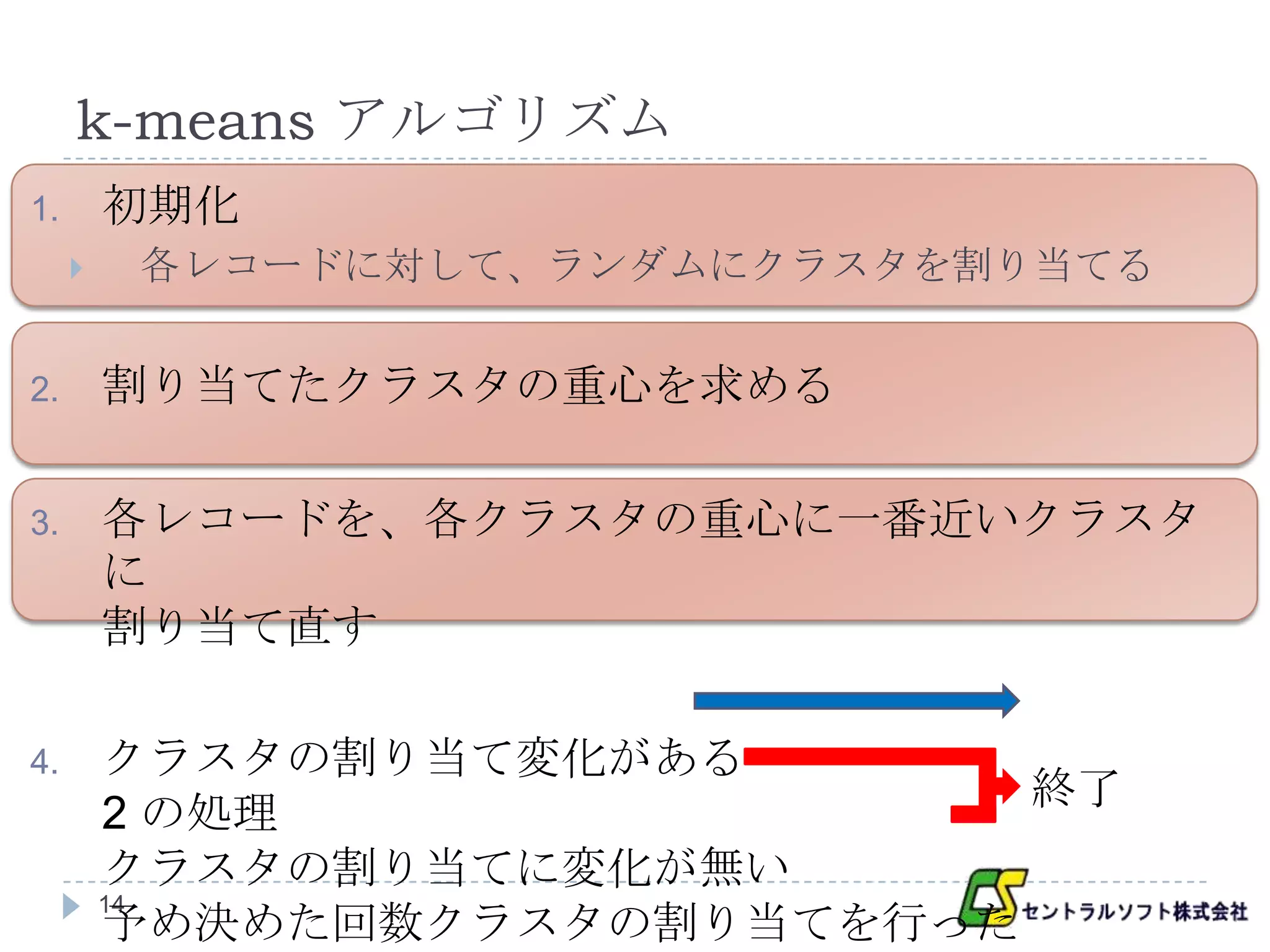
k-means アルゴリズムの手順(1)
1. 初期化
各レコードに対して、ランダムにクラスタを割り当てる
2. 割り当てたクラスタの重心を求める
3. 各レコードを、各クラスタの重心に一番近いクラスタ
に
割り当て直す
4. クラスタの割り当て変化がある
終了
2 の処理
クラスタの割り当てに変化が無い
10
予め決めた回数クラスタの割り当てを行った
- 11.
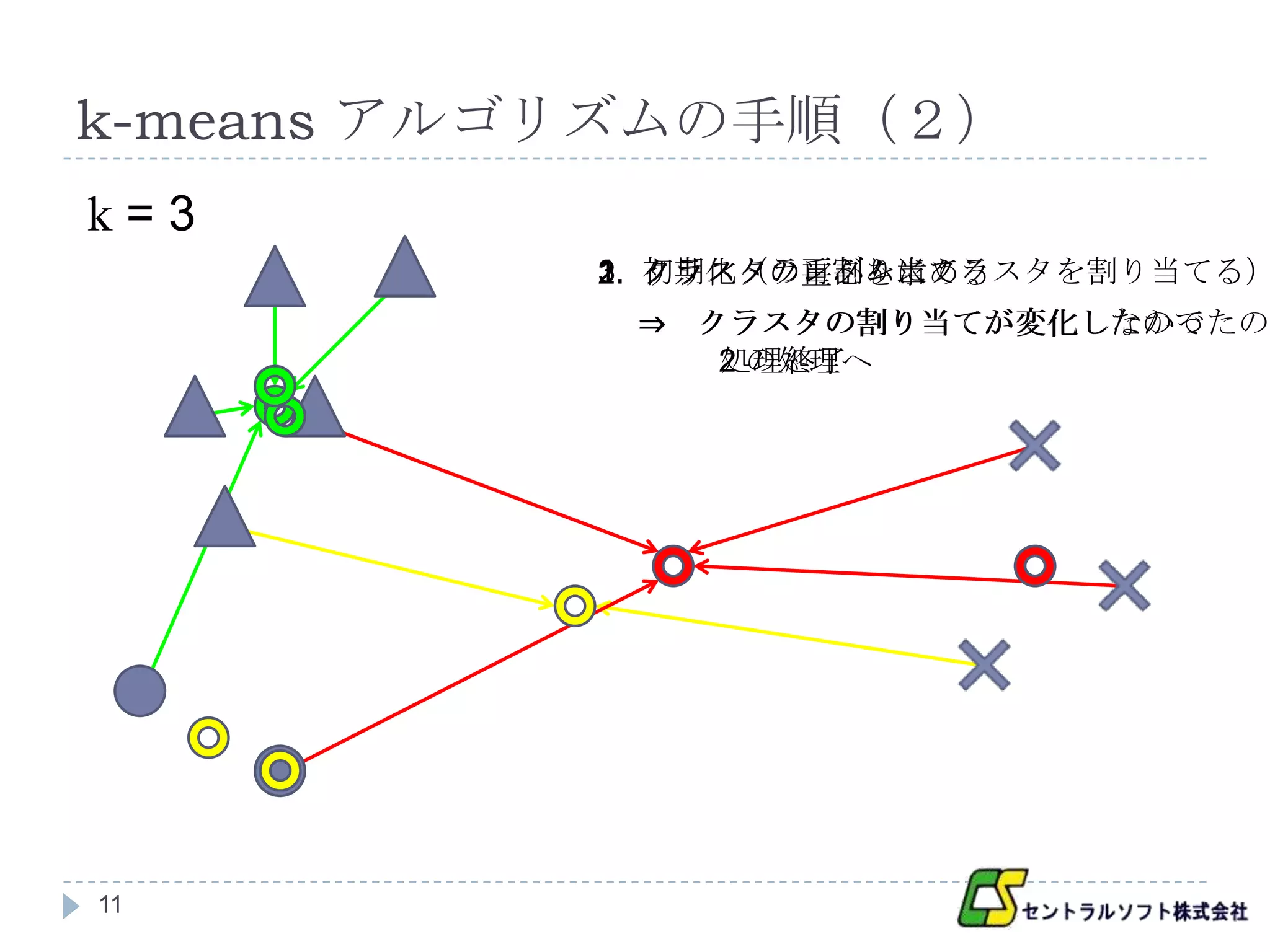
k-means アルゴリズムの手順(2)
k=3
3. クラスタの再割り当て
1. 初期化(ランダムにクラスタを割り当てる)
2. クラスタの重心を求める
⇒ クラスタの割り当てが変化したので
クラスタの割り当てが変化しなかったので
2 の処理へ
処理終了
11
- 12.
- 13.
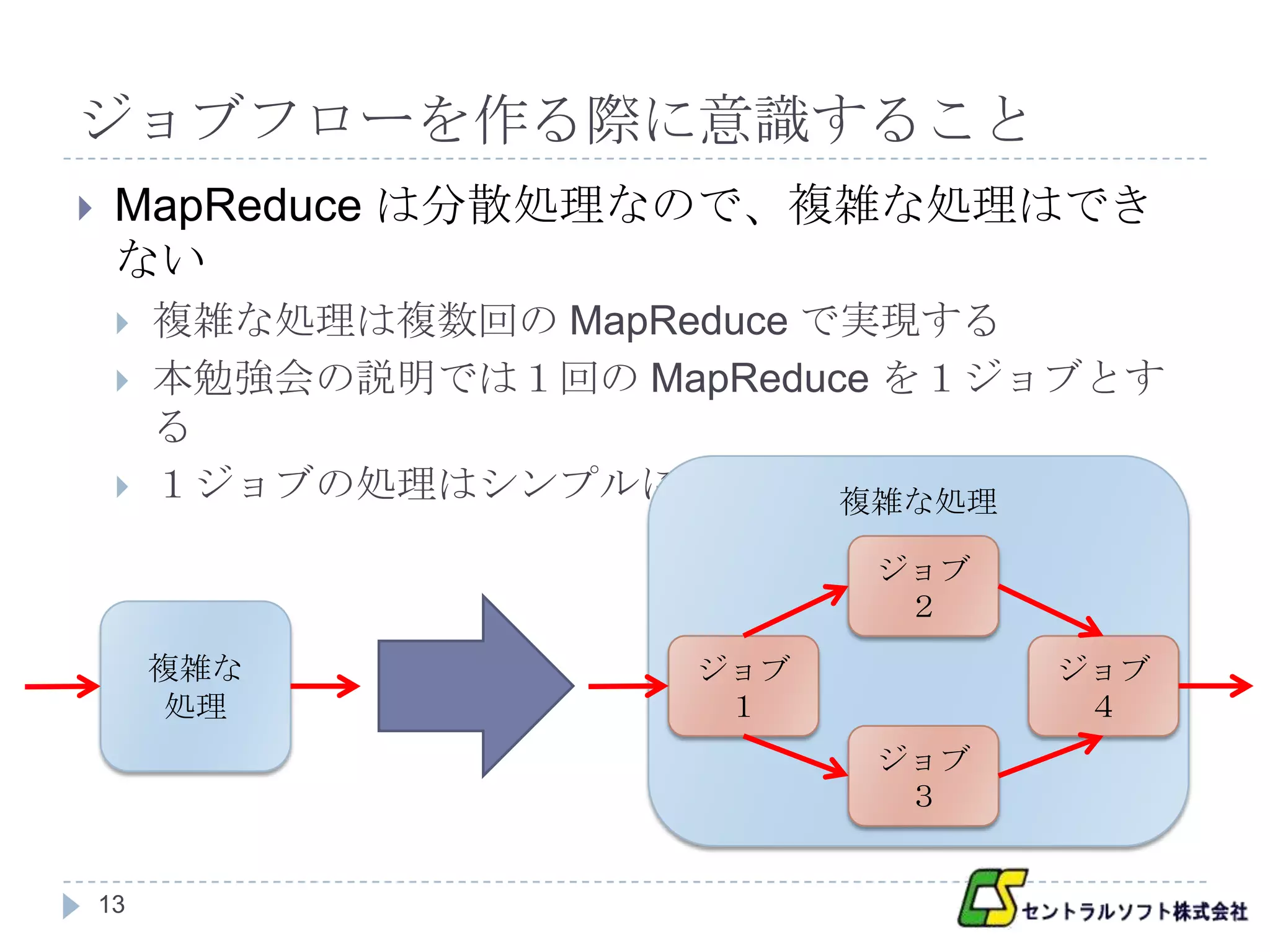
ジョブフローを作る際に意識すること
MapReduce は分散処理なので、複雑な処理はでき
ない
複雑な処理は複数回の MapReduce で実現する
本勉強会の説明では1回の MapReduce を1ジョブとす
る
1ジョブの処理はシンプルにする 複雑な処理
ジョブ
2
複雑な ジョブ ジョブ
処理 1 4
ジョブ
3
13
- 14.
k-means アルゴリズム
1. 初期化
各レコードに対して、ランダムにクラスタを割り当てる
2. 割り当てたクラスタの重心を求める
3. 各レコードを、各クラスタの重心に一番近いクラスタ
に
割り当て直す
4. クラスタの割り当て変化がある
終了
2 の処理
クラスタの割り当てに変化が無い
14
予め決めた回数クラスタの割り当てを行った
- 15.
- 16.
- 17.
MapReduce の簡単な復習
MapReduce は以下の3つのフェーズで構成される
入力データの加工を行う「Map」
データの整理と分配を行う「Shuffle & Sort」
同じ key に対する value は一纏めにし、key 順にソートした
データを Reduce を行うノードが受け取る
まとめられたデータに対して処理を行う「Reduce」
それぞれのフェーズの入出力は key と value のペア
17
- 18.
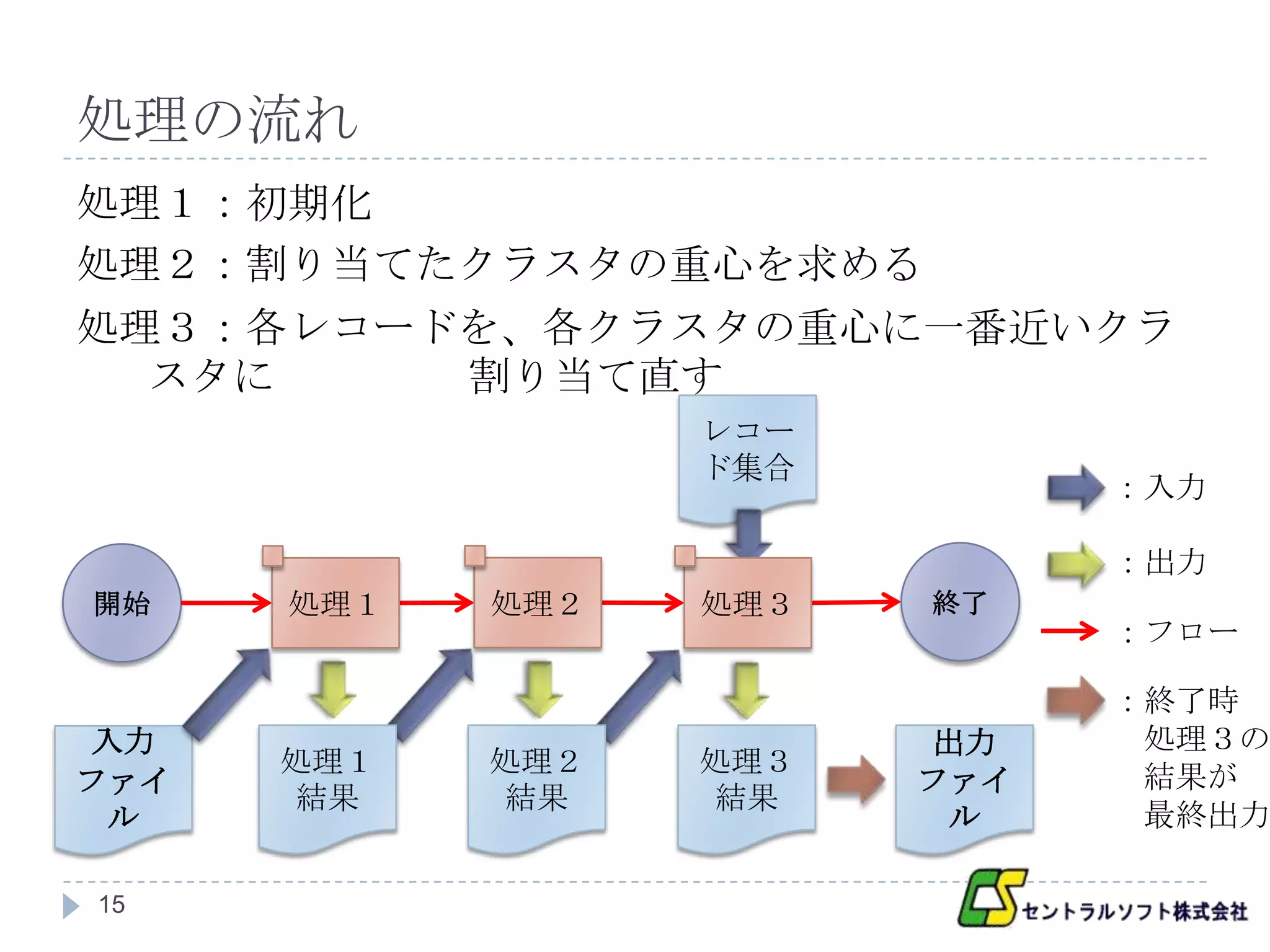
処理1概要
処理
各レコードに対して、ランダムにクラスタを割り当てる
入力(クラスタリングするデータファイル)
key : 入力ファイルの形式による
value : 1レコード
出力(ランダムにクラスタを割り当てられたレコー
ド)
key : 割り当てられたクラスタ番号
value : 1レコード
18
- 19.
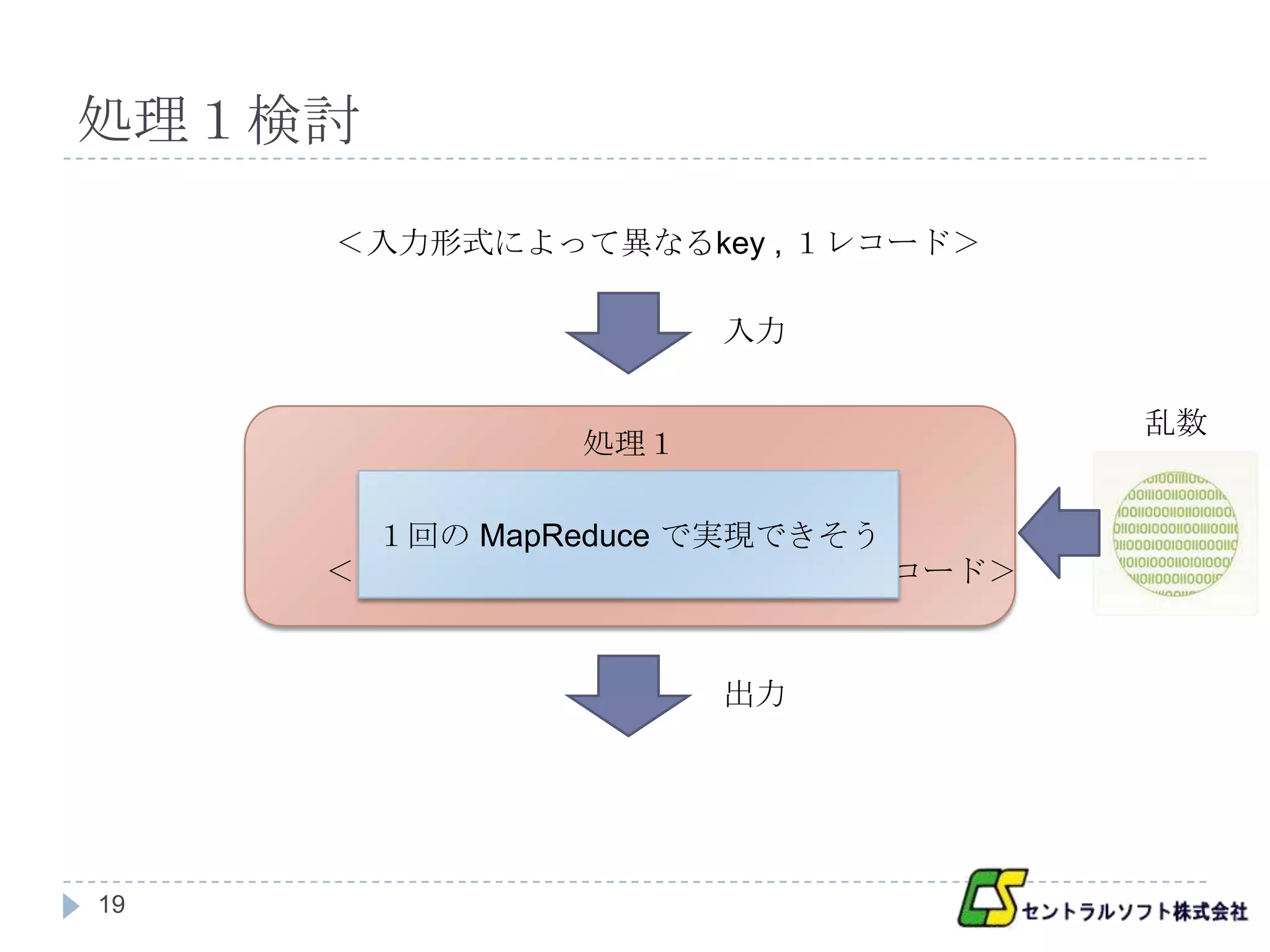
処理1検討
<入力形式によって異なるkey , 1レコード>
入力
乱数
処理1
1回の MapReduce で実現できそう
<ランダムに割り当てたクラスタ , 1レコード>
出力
19
- 20.
処理2概要
処理
割り当てられたクラスタの重心を求める
入力(ランダムにクラスタを割り当てられたレコー
ド)
key : クラスタ番号
value : 1レコード
出力(クラスタの重心)
key : クラスタ番号
value : クラスタの重心の位置
20
- 21.
処理2検討
<クラスタ1, A><クラスタ2, B>
<クラスタ1, C>
Map 出力
Shuffle & Sort で同じクラスタは一纏まりになり、
Shuffle & Sort
その纏まりでクラスタの重心が計算できる
<クラスタ1, [A , C]> <クラスタ2, [B]>
1回の MapReduce で実現できそう
Reduce 入力
21
- 22.
処理3概要
処理
各レコードを、一番近いクラスタに割り当て直す
入力1(クラスタの重心)
key : クラスタ番号
value : クラスタの重心の位置
入力2(クラスタリングするデータファイル)
key : <要検討>
value : 1レコード
出力(クラスタを割り当て直したレコード)
key : 割り当てたクラスタ
value : 1レコード
22
- 23.
処理3検討
問題となりそうなところ
2つの形式のデータの入力はどうする?
クラスタの重心のデータはすべての Reduce を行うノー
ドに
配布する必要があるがどうする?
すべてに配布しないと各レコードがどのクラスタに近いのか
比較できない
実現方法を知っていれば1回の MapReduce で
知らなければ MapReduce の回数を増やす
次回、1回の MapReduce で実現する方法を解説
予定
23
- 24.
その他次回解説を行う問題
<要検討>にしてあった部分
処理3の終了後、条件によって処理を終了するか、
処理2の処理に戻るか分岐する問題
MapReduce の実装レベルの内容は次回行う(予
定)
24
- 25.
- 26.
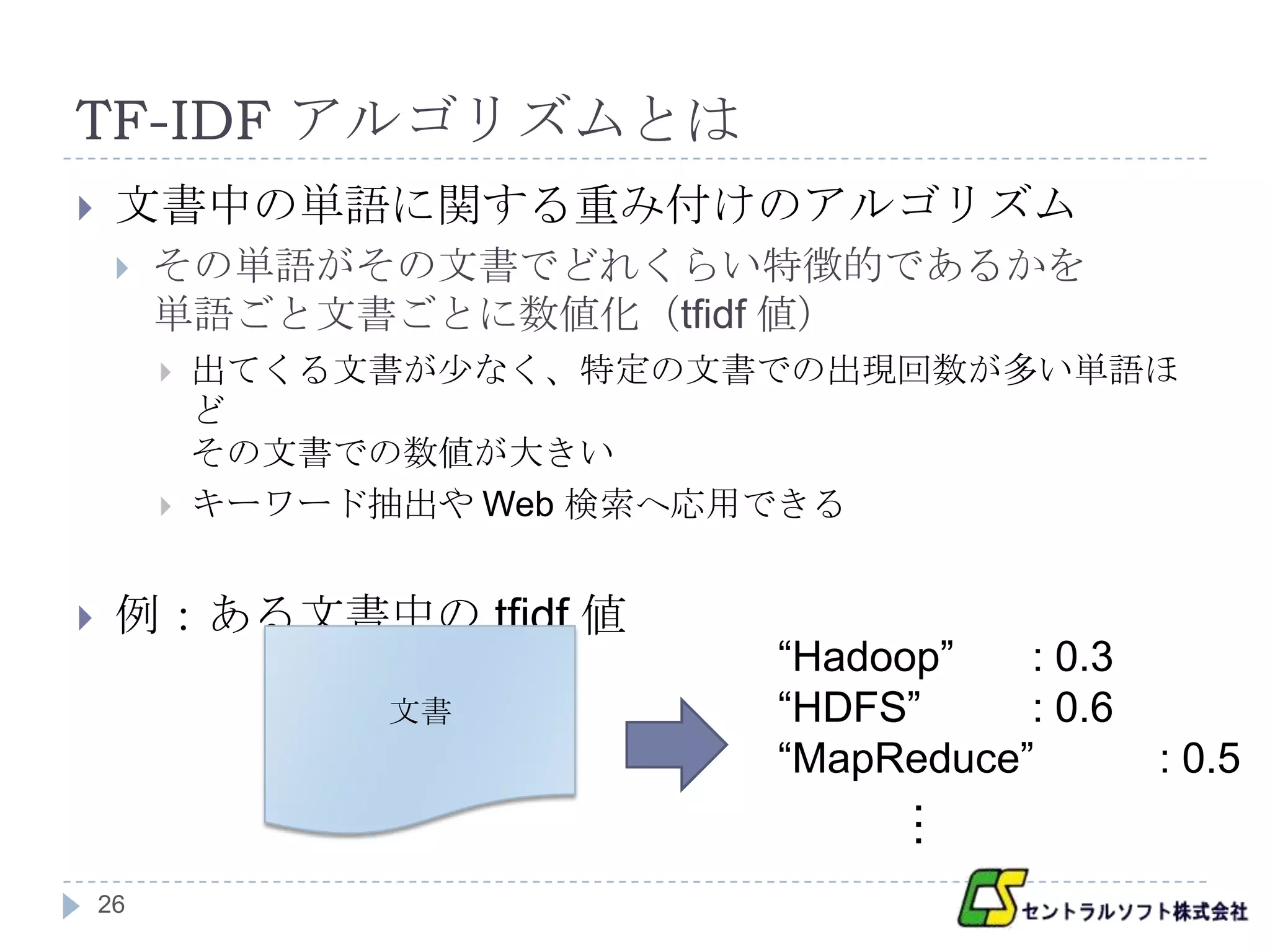
TF-IDF アルゴリズムとは
文書中の単語に関する重み付けのアルゴリズム
その単語がその文書でどれくらい特徴的であるかを
単語ごと文書ごとに数値化(tfidf 値)
出てくる文書が少なく、特定の文書での出現回数が多い単語ほ
ど
その文書での数値が大きい
キーワード抽出や Web 検索へ応用できる
例:ある文書中の tfidf 値
“Hadoop” : 0.3
文書 “HDFS” : 0.6
“MapReduce” : 0.5
26 …
- 27.
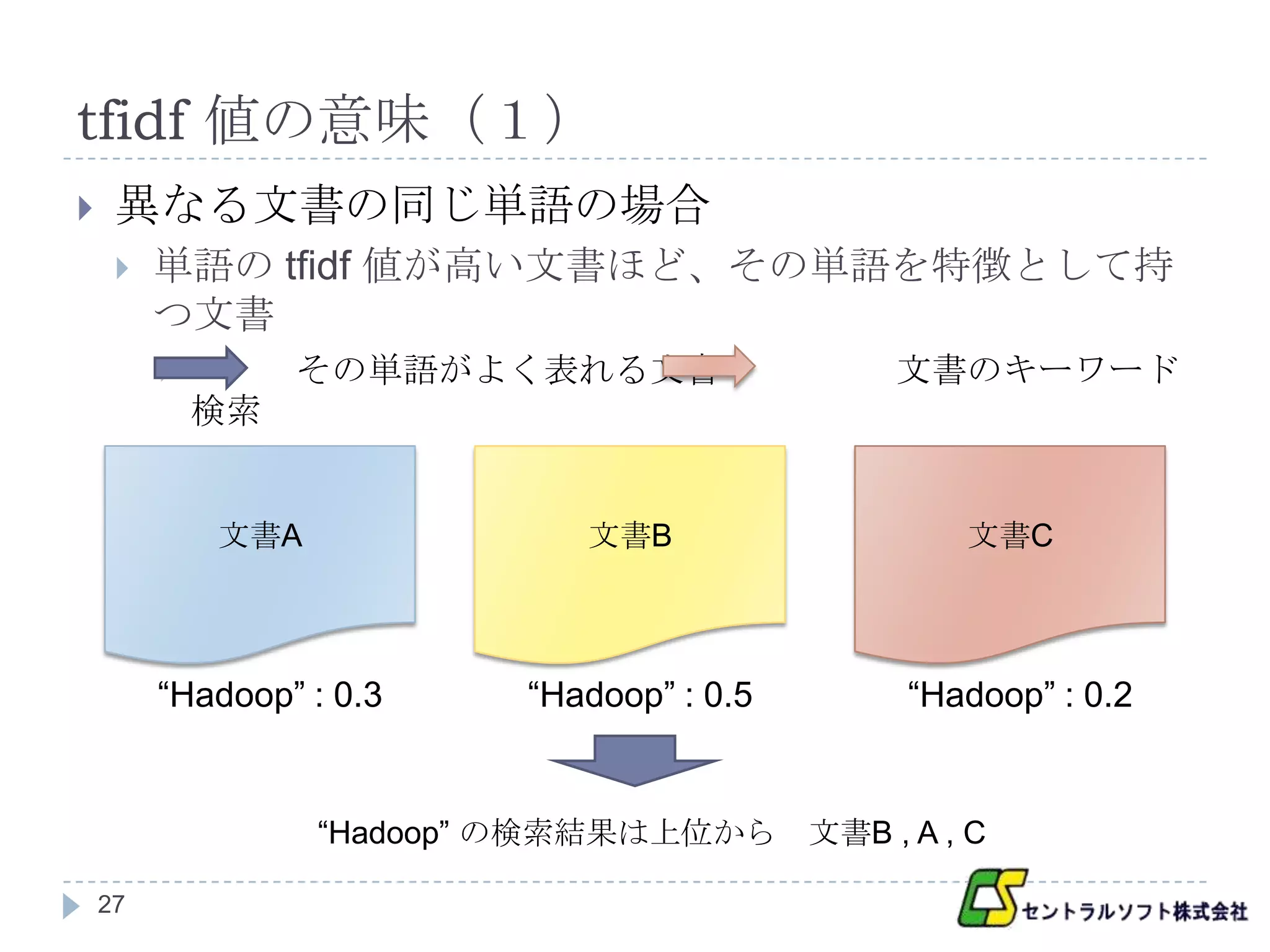
tfidf 値の意味(1)
異なる文書の同じ単語の場合
単語の tfidf 値が高い文書ほど、その単語を特徴として持
つ文書
その単語がよく表れる文書 文書のキーワード
検索
文書A 文書B 文書C
“Hadoop” : 0.3 “Hadoop” : 0.5 “Hadoop” : 0.2
“Hadoop” の検索結果は上位から 文書B , A , C
27
- 28.
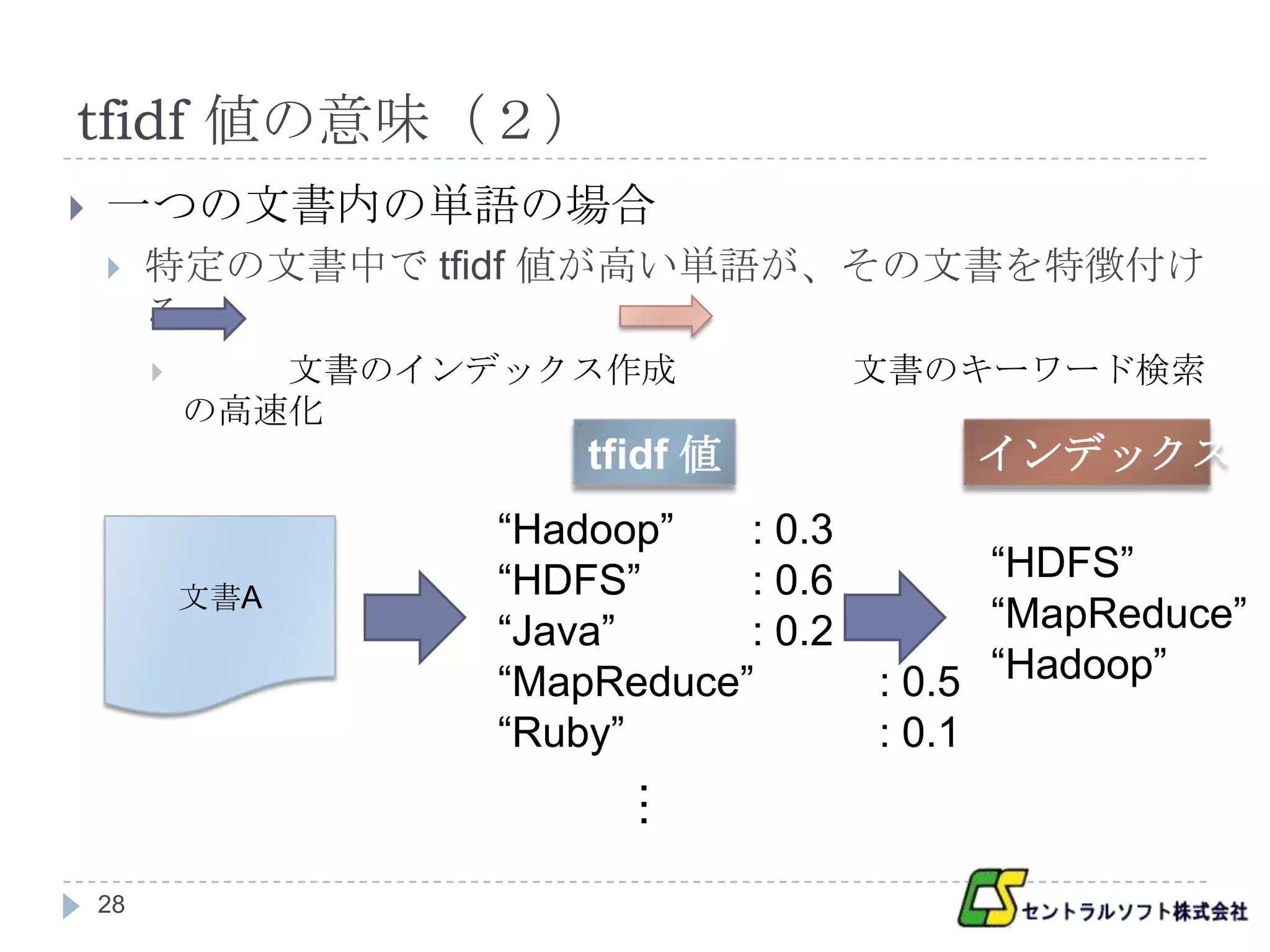
tfidf 値の意味(2)
一つの文書内の単語の場合
特定の文書中で tfidf 値が高い単語が、その文書を特徴付け
る
文書のインデックス作成 文書のキーワード検索
の高速化
tfidf 値 インデックス
“Hadoop” : 0.3
“HDFS” : 0.6 “HDFS”
文書A
“Java” : 0.2 “MapReduce”
“MapReduce” : 0.5 “Hadoop”
“Ruby” : 0.1
…
28
- 29.
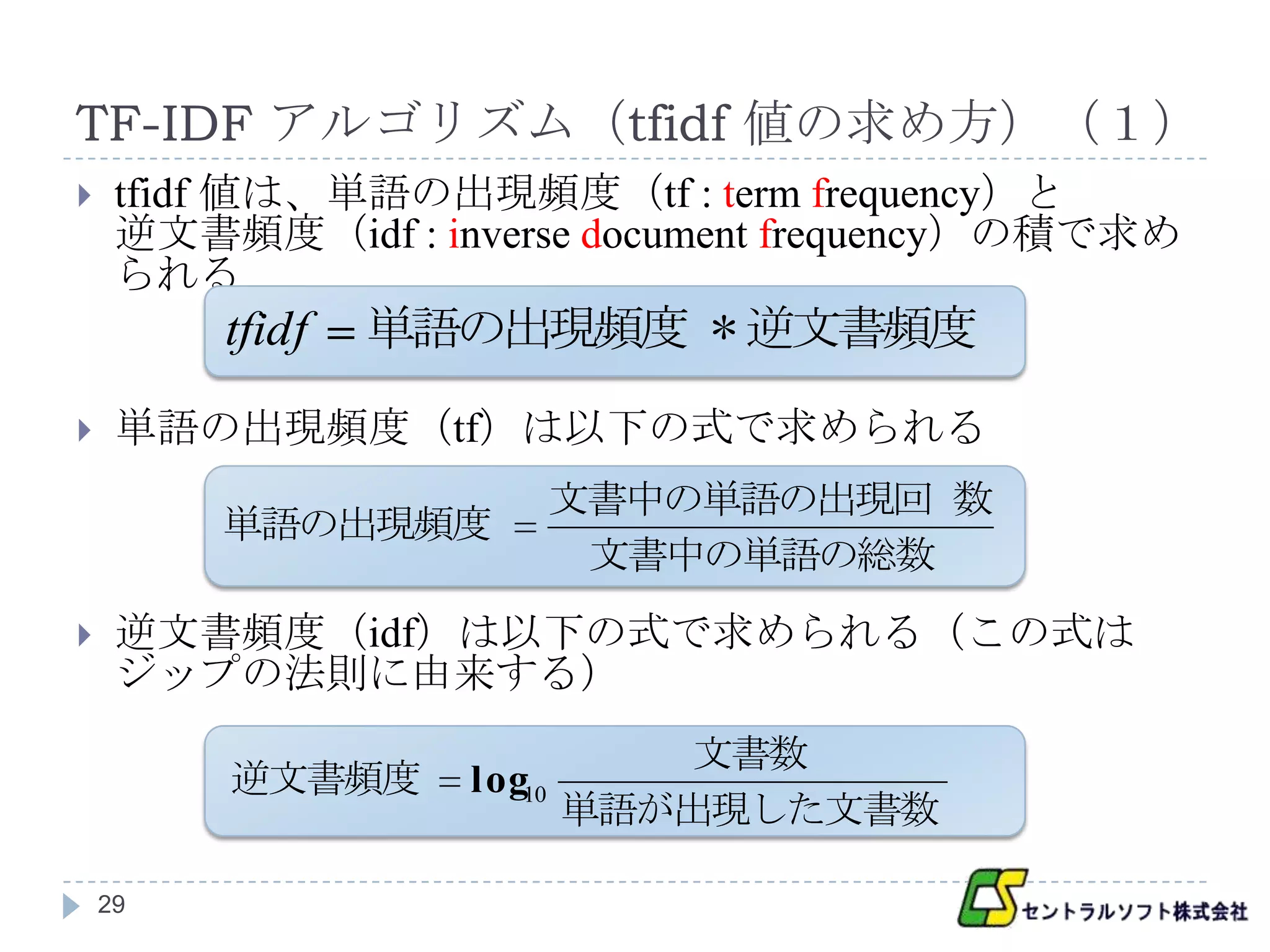
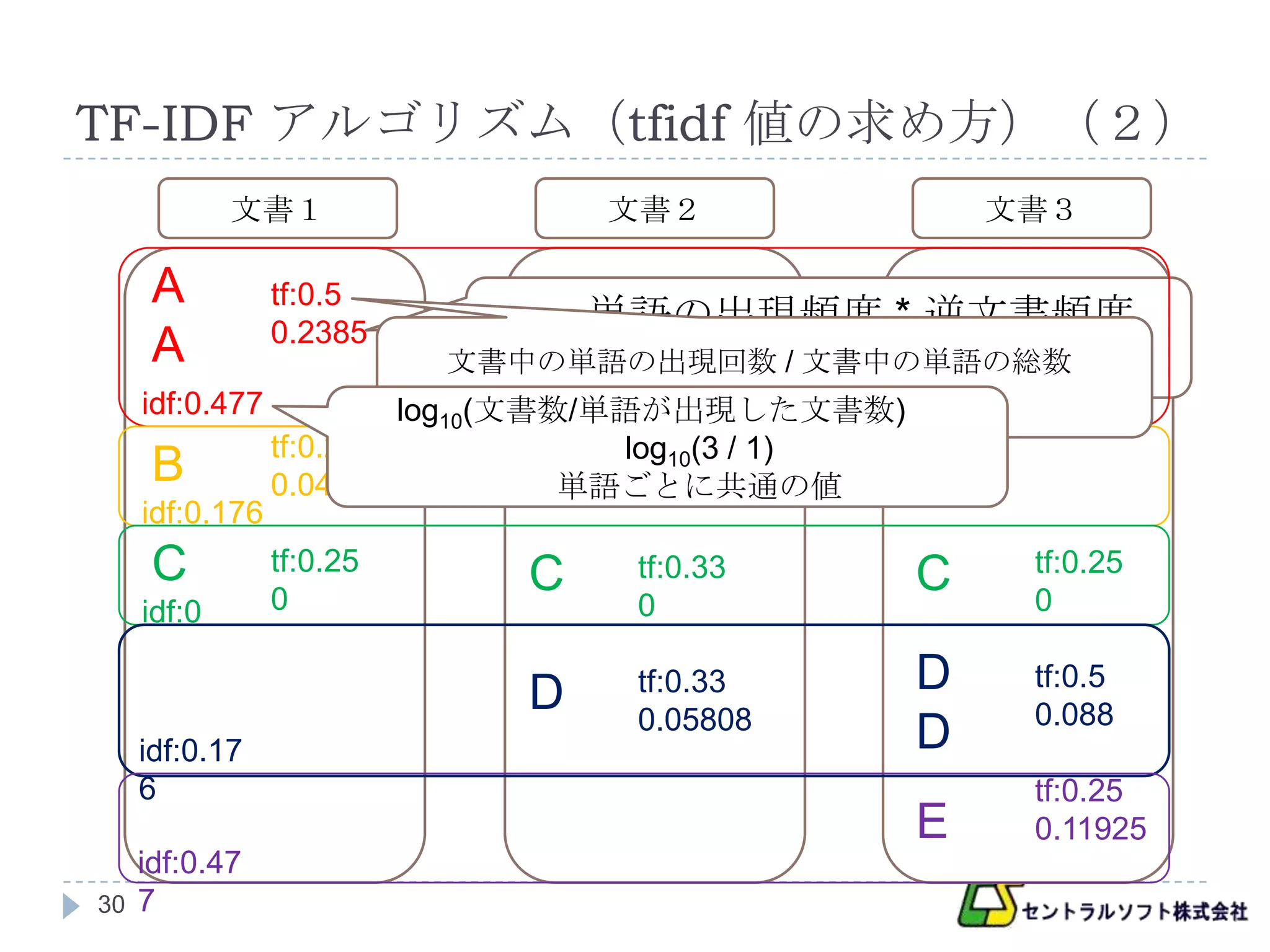
TF-IDF アルゴリズム(tfidf 値の求め方)(1)
tfidf 値は、単語の出現頻度(tf : term frequency)と
逆文書頻度(idf : inverse document frequency)の積で求め
られる
tfidf 単語の出現頻度 * 逆文書頻度
単語の出現頻度(tf)は以下の式で求められる
文書中の単語の出現回 数
単語の出現頻度
文書中の単語の総数
逆文書頻度(idf)は以下の式で求められる(この式は
ジップの法則に由来する)
文書数
逆文書頻度 log10
単語が出現した文書数
29
- 30.
TF-IDF アルゴリズム(tfidf 値の求め方)(2)
文書1 文書2 文書3
A tf:0.5
0.2385 単語の出現頻度 * 逆文書頻度
A 文書中の単語の出現回数 / 文書中の単語の総数
0.5 * 0.477
idf:0.477 2/4
log10(文書数/単語が出現した文書数)
tf:0.25 log10(3 / 1)
tf:0.33
B 0.044 B単語ごとに共通の値
0.05808
idf:0.176
C tf:0.25
C tf:0.33 C tf:0.25
idf:0 0 0 0
D tf:0.33 D tf:0.5
0.05808 0.088
idf:0.17 D
6 tf:0.25
E 0.11925
idf:0.47
30 7
- 31.
- 32.
k-means アルゴリズムとの違い
k-means はアルゴリズムの中でフローが決まってい
た
TF-IDF は計算式だけでフローが無いので、どのよう
な順番で処理を行うのか考えなければならない
32
- 33.
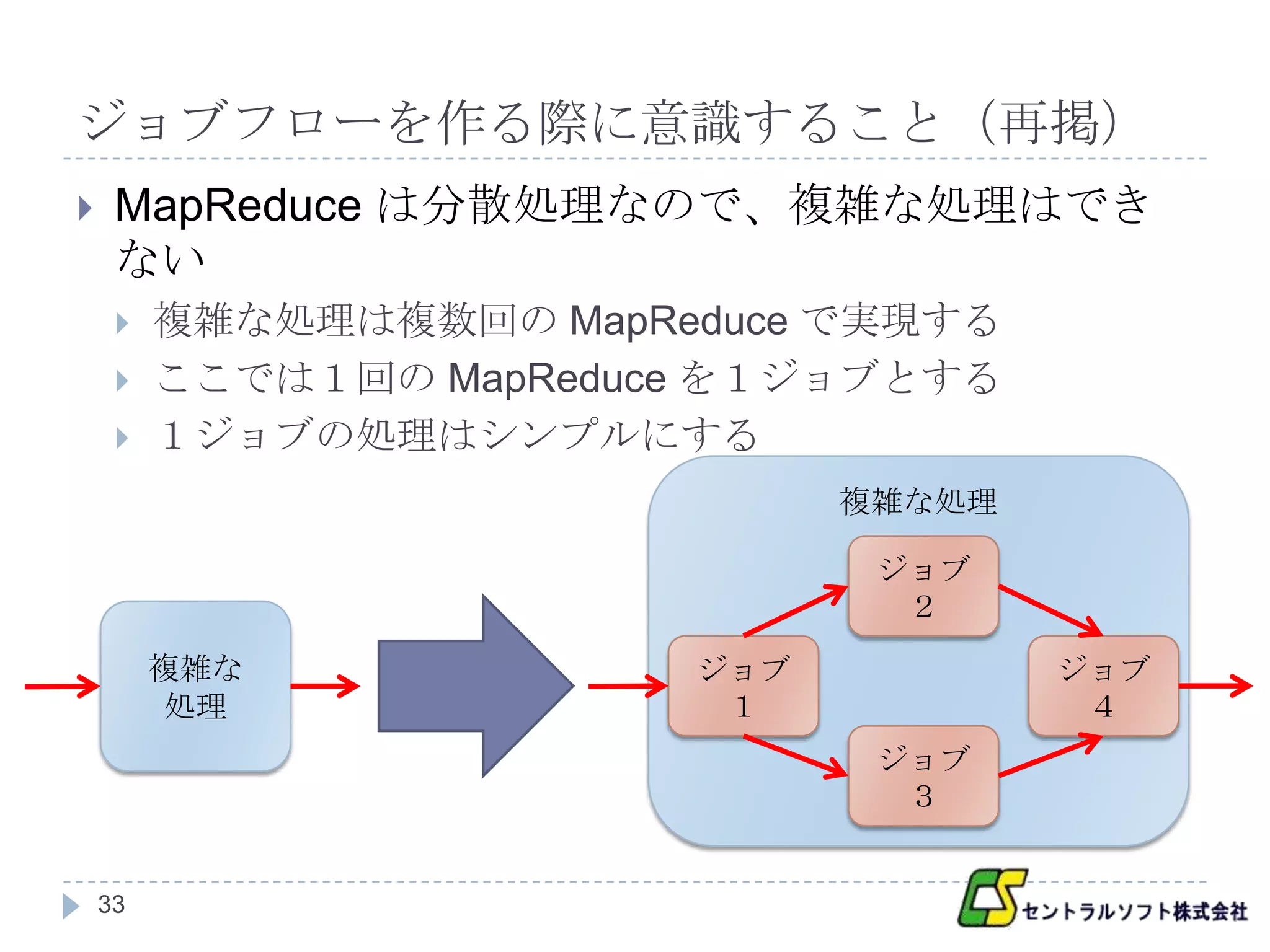
ジョブフローを作る際に意識すること(再掲)
MapReduce は分散処理なので、複雑な処理はでき
ない
複雑な処理は複数回の MapReduce で実現する
ここでは1回の MapReduce を1ジョブとする
1ジョブの処理はシンプルにする
複雑な処理
ジョブ
2
複雑な ジョブ ジョブ
処理 1 4
ジョブ
3
33
- 34.
MapReduce の簡単な復習(再掲)
MapReduce は以下の3つのフェーズで構成される
入力データの加工を行う「Map」
データの整理と分配を行う「Shuffle & Sort」
同じ key に対する value は一纏めにし、key 順にソートした
データを Reduce を行うノードが受け取る
まとめられたデータに対して処理を行う「Reduce」
それぞれのフェーズの入出力は key と value のペア
34
- 35.
アルゴリズムからジョブフローへの流れ
1. 大まかな処理に分ける
2. 処理の入出力を考える
3. データを Reduce からの参照のされ方で分ける
1. 全ての Reduce
2. 全てではないが複数の Reduce
3. 一つの Reduce
4. 処理ごとに簡単な MapReduce で実現できるか検討
し、
必要に応じてジョブを増やす
35
- 36.
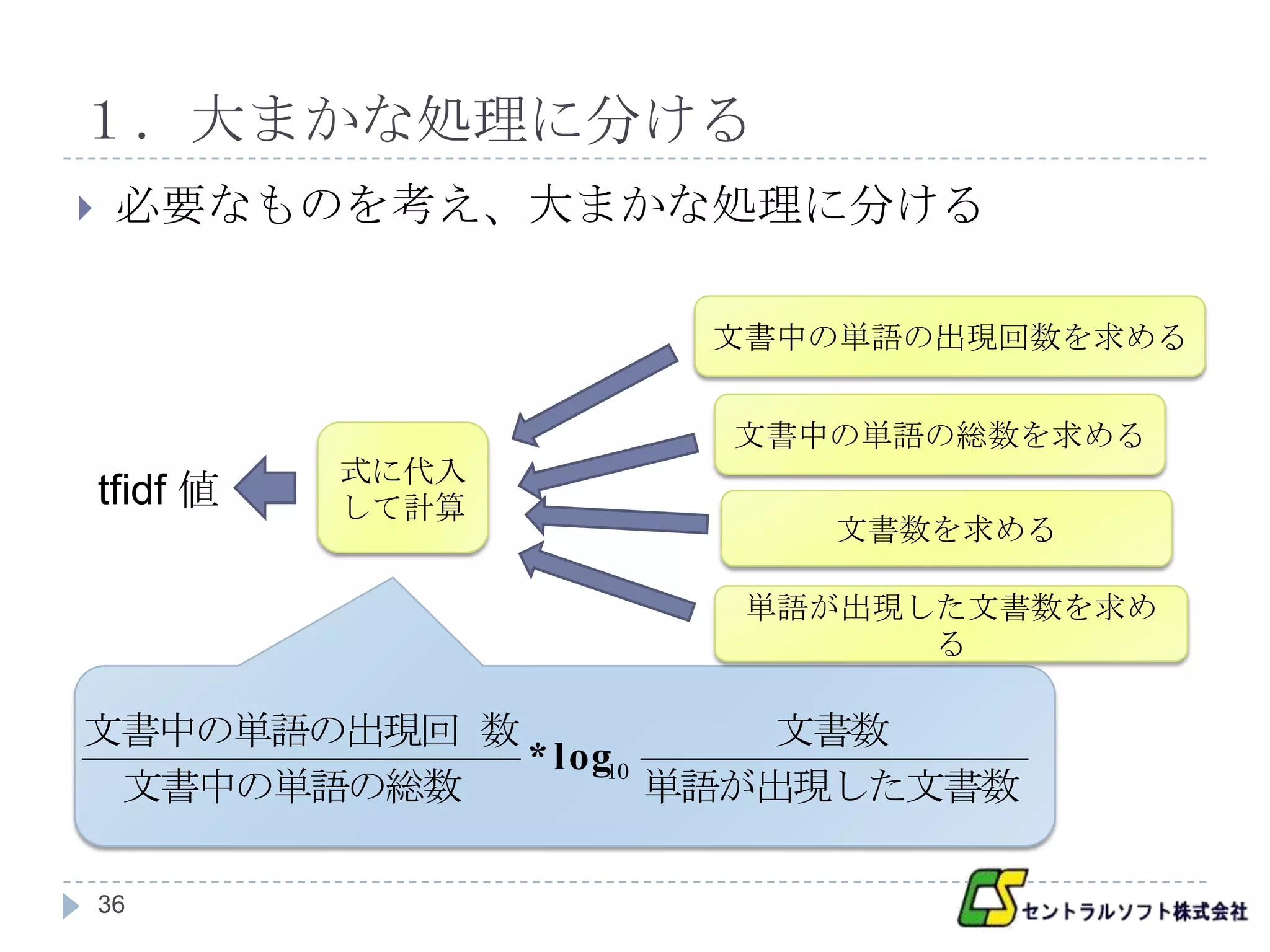
1.大まかな処理に分ける
必要なものを考え、大まかな処理に分ける
文書中の単語の出現回数を求める
文書中の単語の総数を求める
式に代入
tfidf 値 して計算
文書数を求める
単語が出現した文書数を求め
る
文書中の単語の出現回 数 文書数
* log10
文書中の単語の総数 単語が出現した文書数
36
- 37.
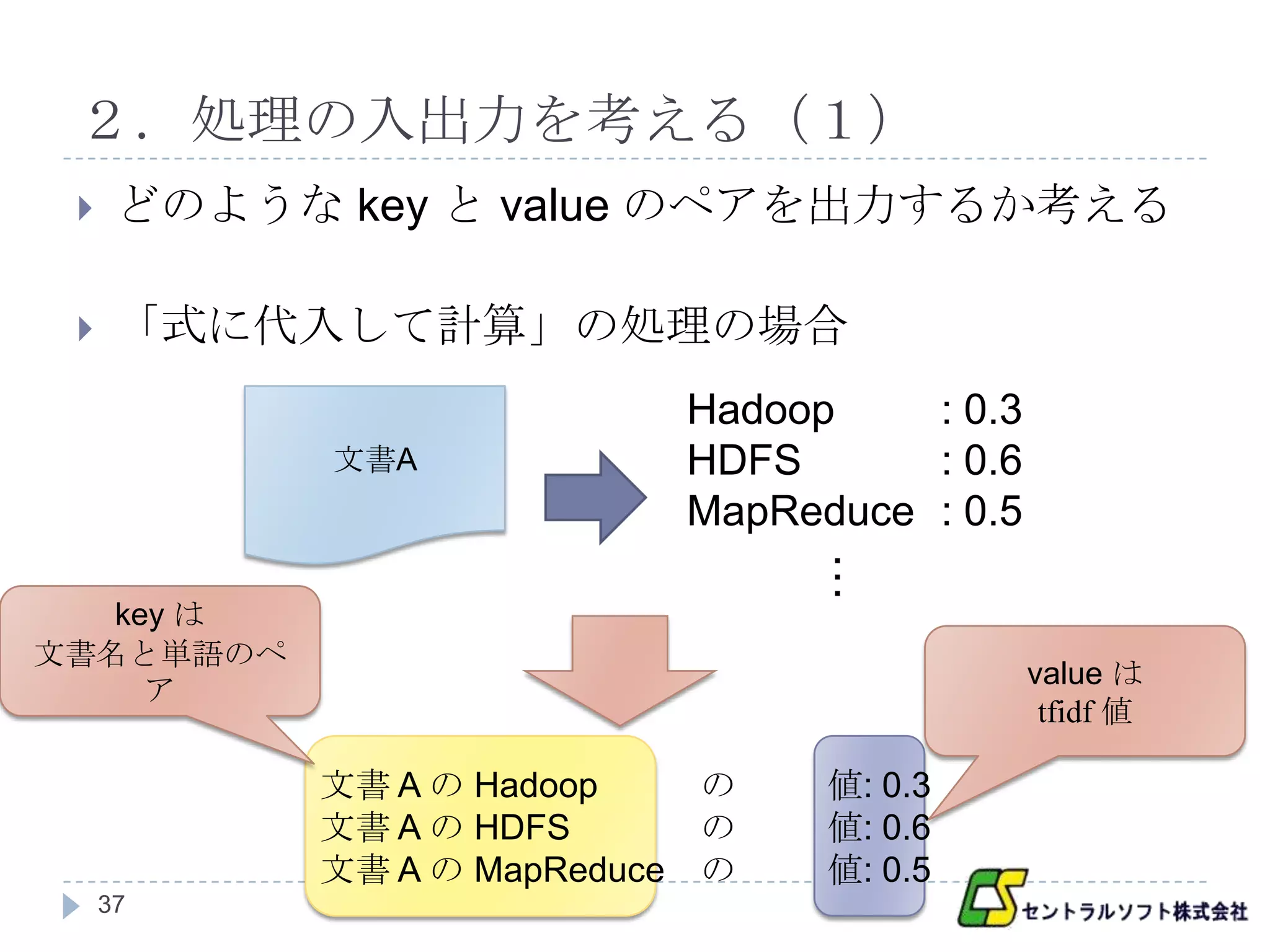
2.処理の入出力を考える(1)
どのような key と value のペアを出力するか考える
「式に代入して計算」の処理の場合
Hadoop : 0.3
文書A HDFS : 0.6
MapReduce : 0.5
…
key は
文書名と単語のペ
value は
ア
tfidf 値
文書 A の Hadoop の 値: 0.3
文書 A の HDFS の 値: 0.6
文書 A の MapReduce の 値: 0.5
37
- 38.
2.処理の入出力を考える(2)
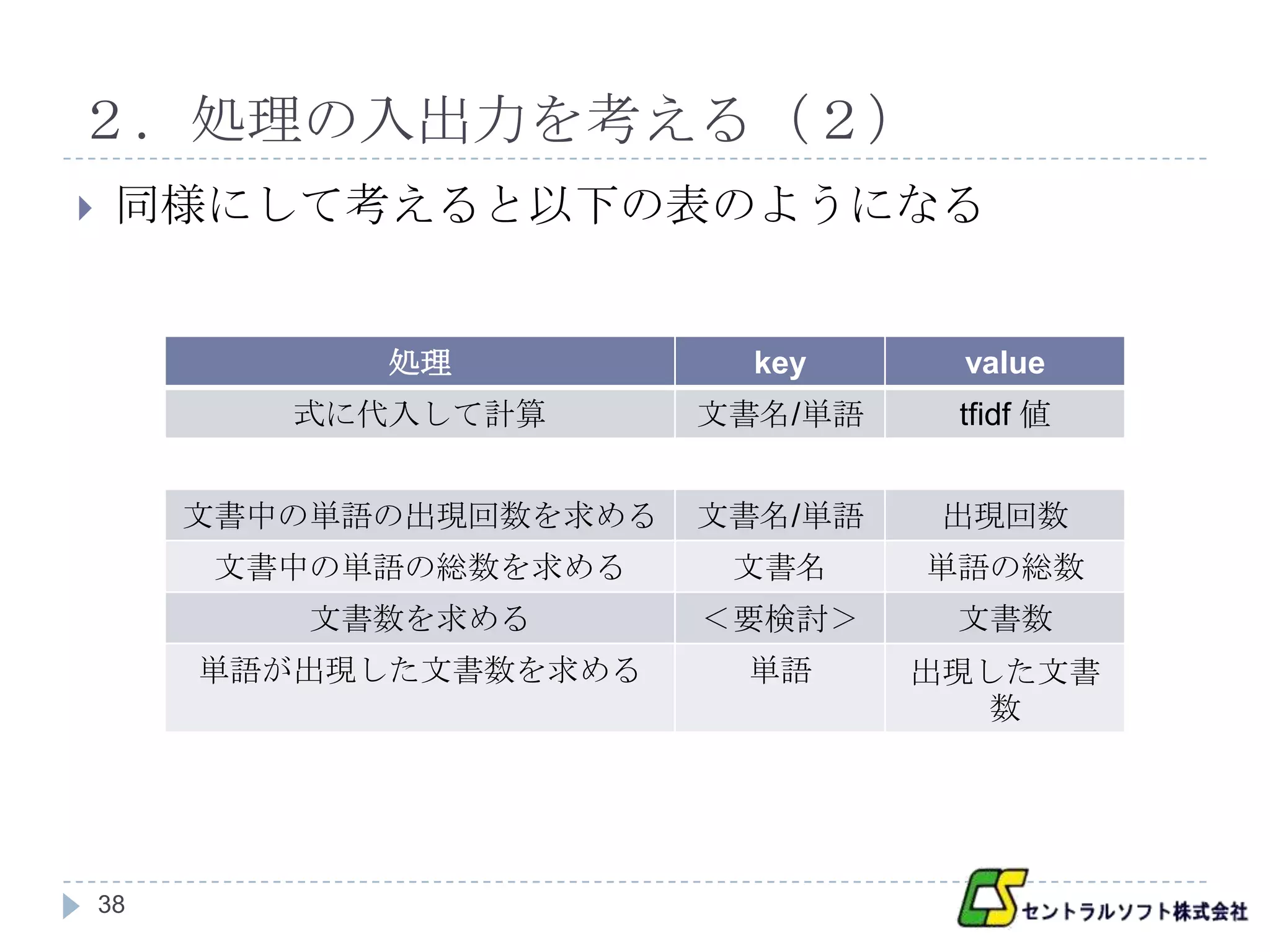
同様にして考えると以下の表のようになる
処理 key value
式に代入して計算 文書名/単語 tfidf 値
文書中の単語の出現回数を求める 文書名/単語 出現回数
文書中の単語の総数を求める 文書名 単語の総数
文書数を求める <要検討> 文書数
単語が出現した文書数を求める 単語 出現した文書
数
38
- 39.
2.処理の入出力を考える(3)
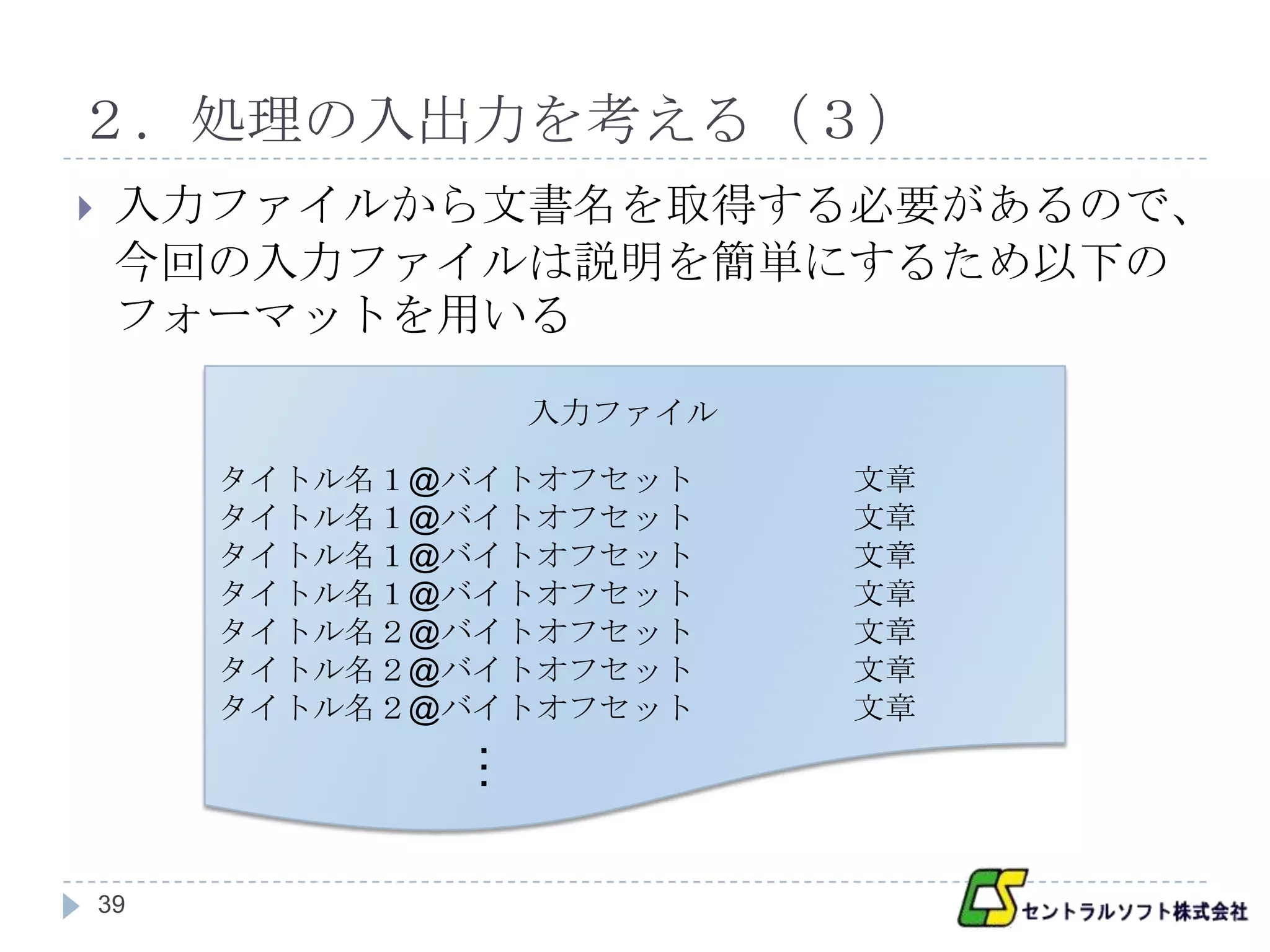
入力ファイルから文書名を取得する必要があるので、
今回の入力ファイルは説明を簡単にするため以下の
フォーマットを用いる
入力ファイル
タイトル名1@バイトオフセット 文章
タイトル名1@バイトオフセット 文章
タイトル名1@バイトオフセット 文章
タイトル名1@バイトオフセット 文章
タイトル名2@バイトオフセット 文章
タイトル名2@バイトオフセット 文章
タイトル名2@バイトオフセット 文章
…
39
- 40.
3.データを Reduce からの参照のされ方で分ける(1)
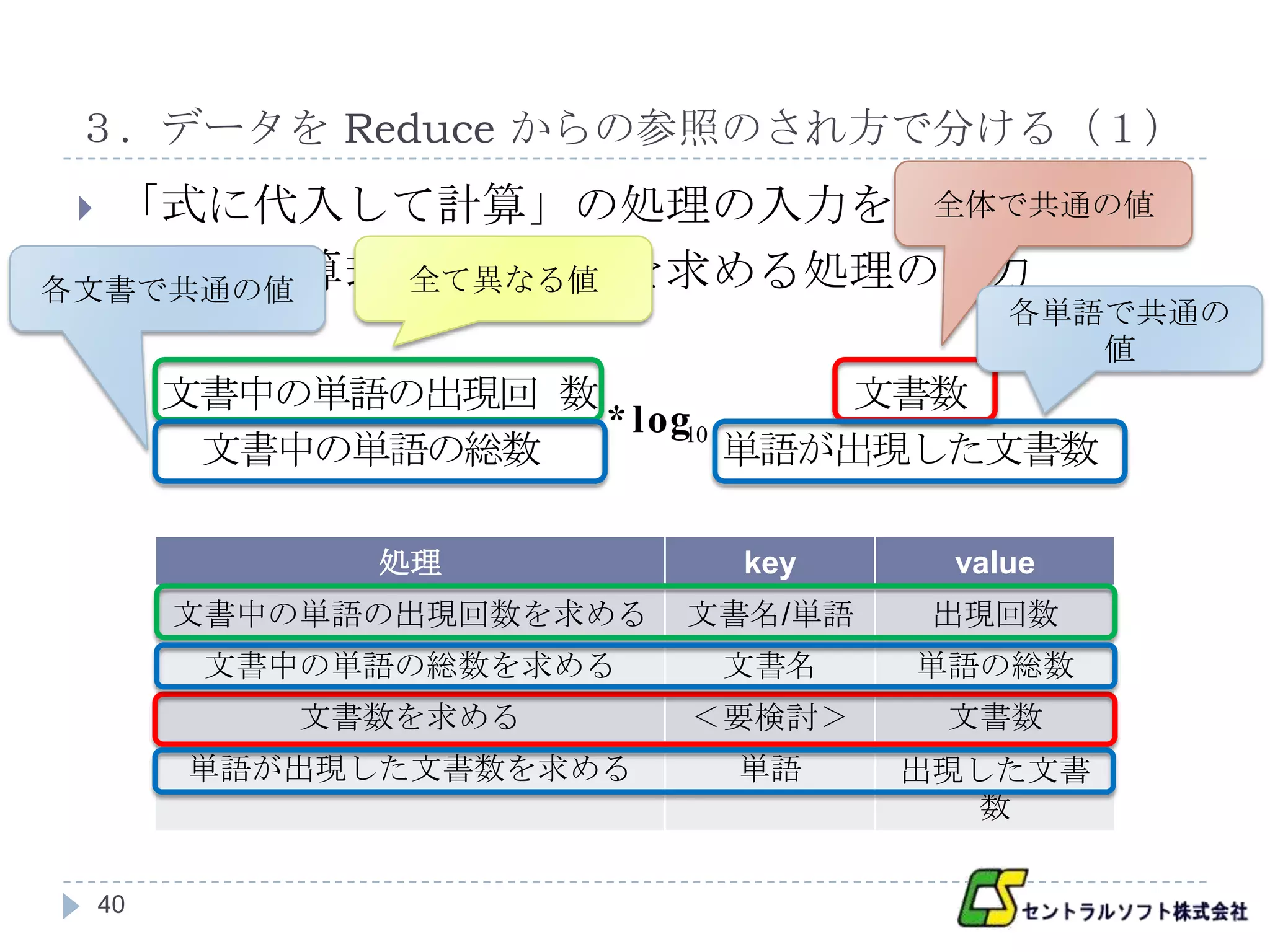
「式に代入して計算」の処理の入力を考える
全体で共通の値
以下は計算式と必要な値を求める処理の出力
各文書で共通の値 全て異なる値
各単語で共通の
値
文書中の単語の出現回 数 文書数
* log10
文書中の単語の総数 単語が出現した文書数
処理 key value
文書中の単語の出現回数を求める 文書名/単語 出現回数
文書中の単語の総数を求める 文書名 単語の総数
文書数を求める <要検討> 文書数
単語が出現した文書数を求める 単語 出現した文書
数
40
- 41.
- 42.
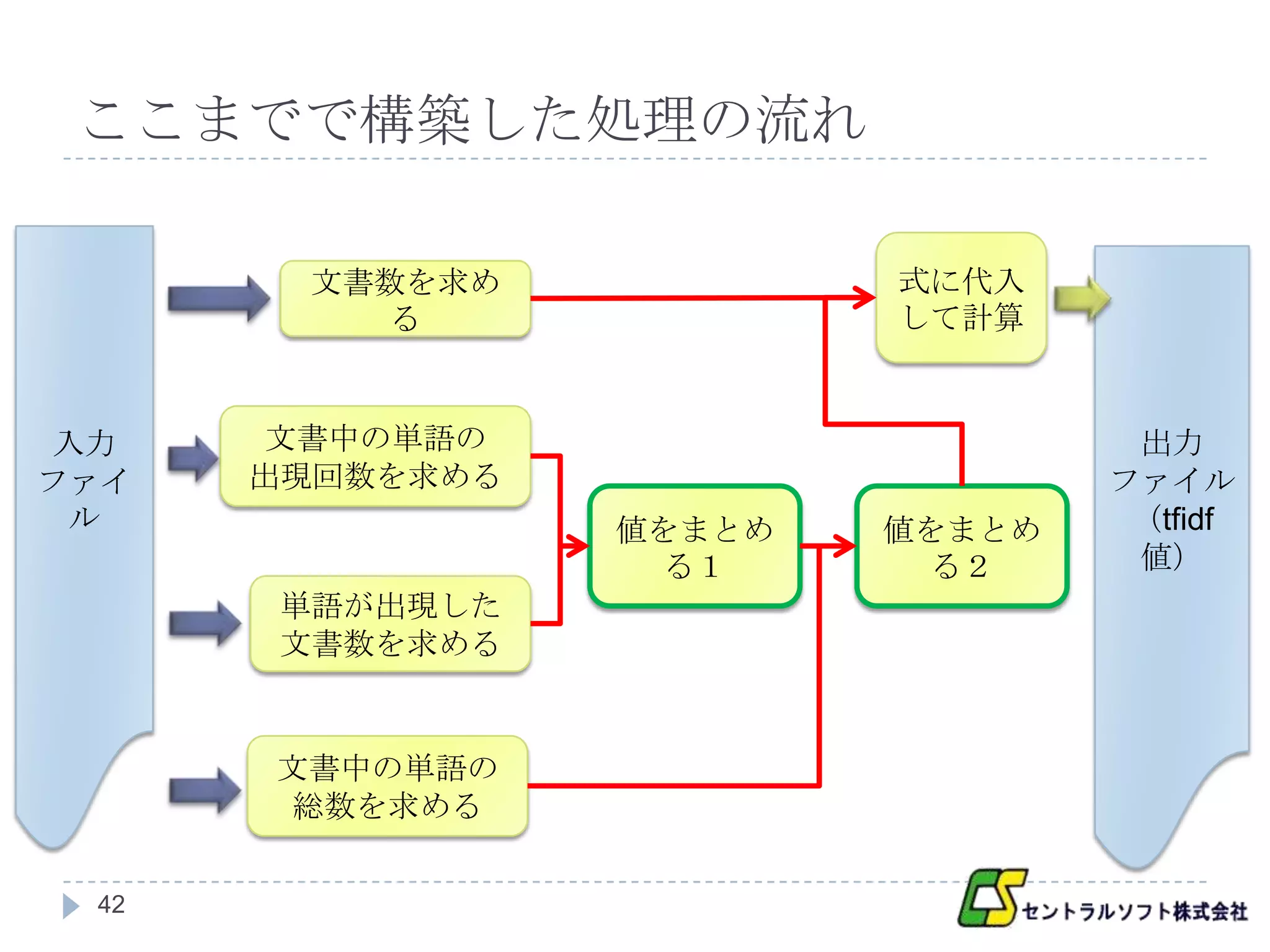
ここまでで構築した処理の流れ
文書数を求め 式に代入
る して計算
入力 文書中の単語の 出力
ファイ 出現回数を求める ファイル
ル 値をまとめ 値をまとめ (tfidf
る1 る2 値)
単語が出現した
文書数を求める
文書中の単語の
総数を求める
42
- 43.
- 44.
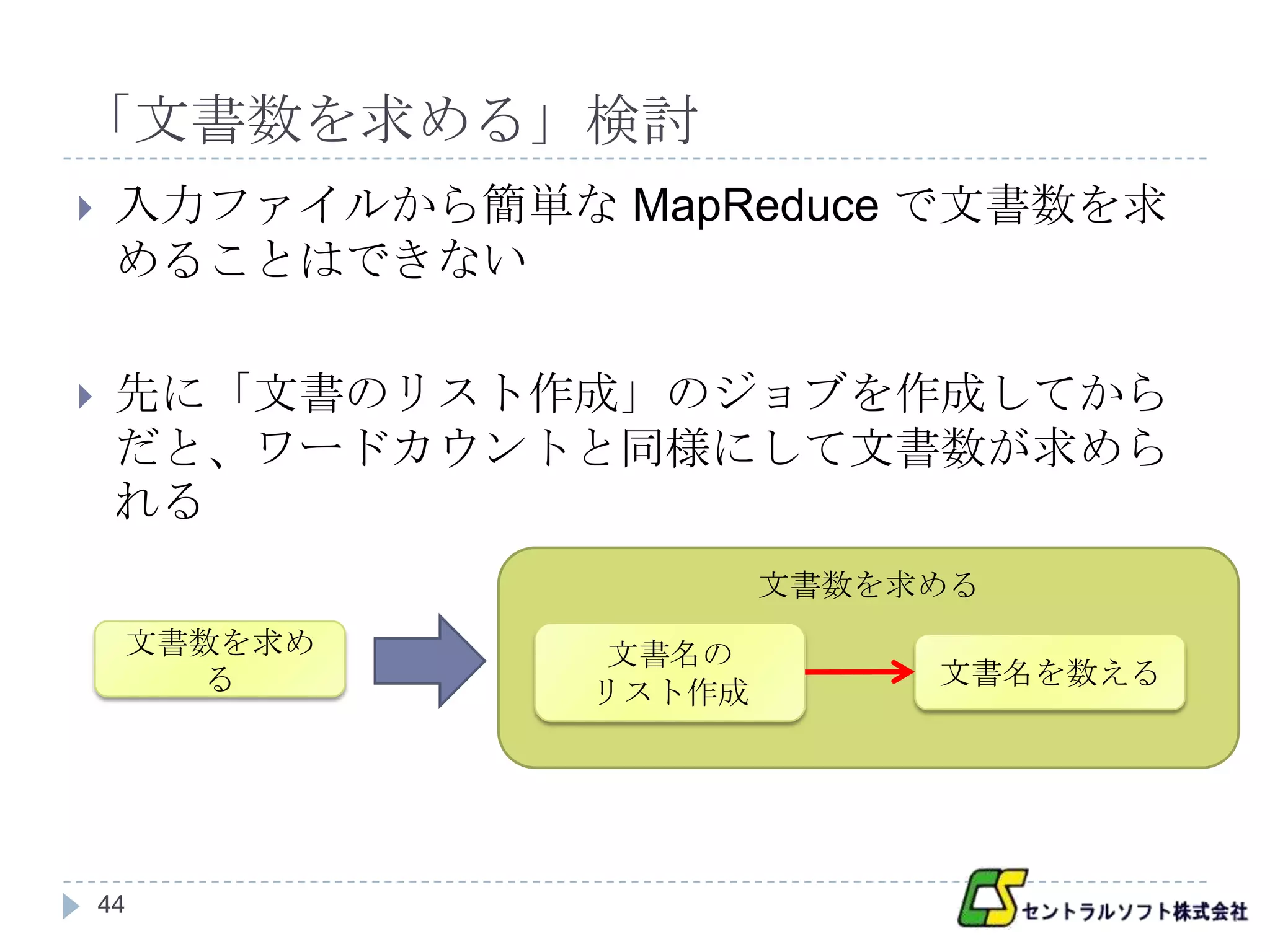
「文書数を求める」検討
入力ファイルから簡単な MapReduce で文書数を求
めることはできない
先に「文書のリスト作成」のジョブを作成してから
だと、ワードカウントと同様にして文書数が求めら
れる
文書数を求める
文書数を求め 文書名の
る 文書名を数える
リスト作成
44
- 45.
- 46.
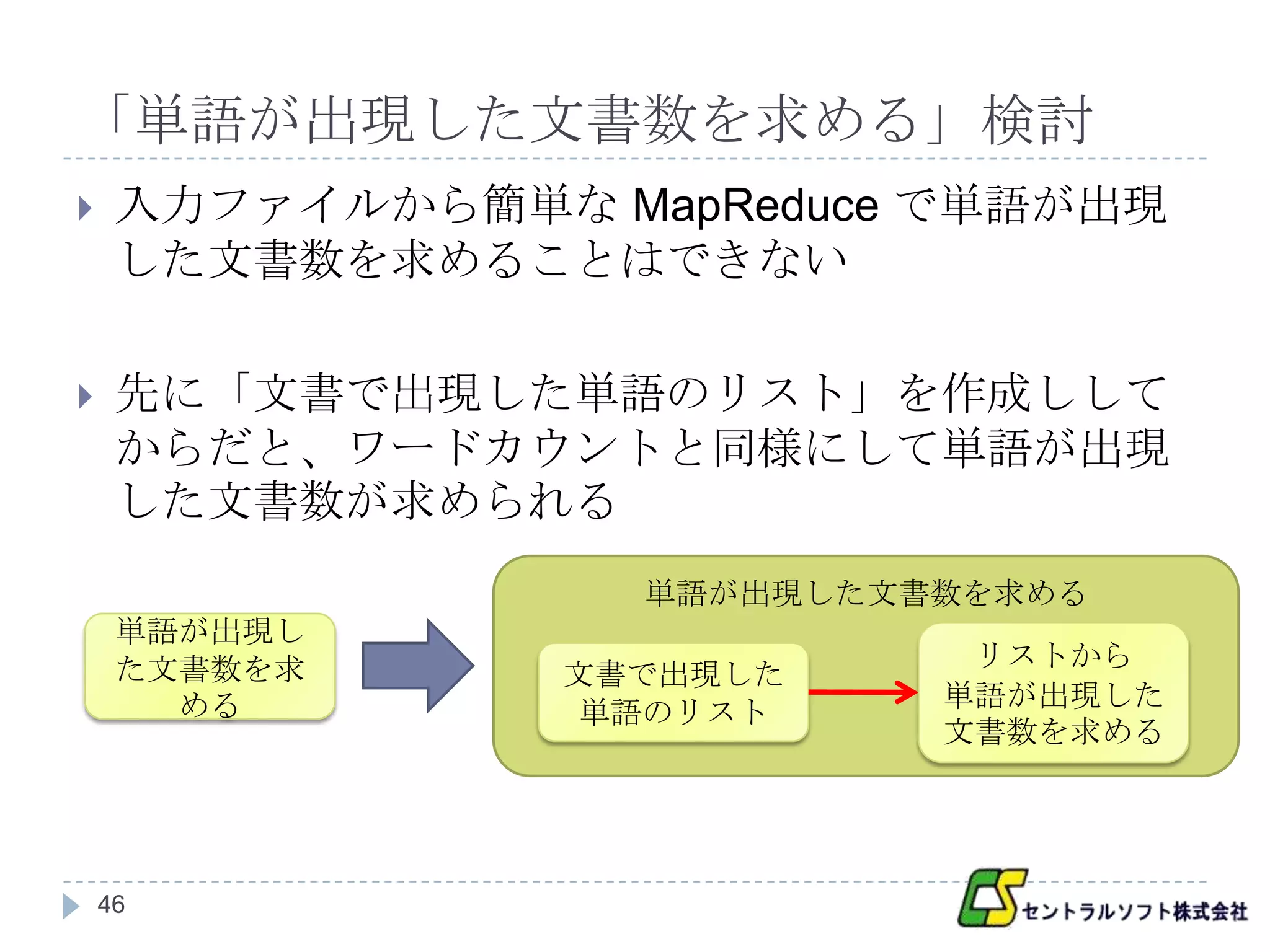
「単語が出現した文書数を求める」検討
入力ファイルから簡単な MapReduce で単語が出現
した文書数を求めることはできない
先に「文書で出現した単語のリスト」を作成しして
からだと、ワードカウントと同様にして単語が出現
した文書数が求められる
単語が出現した文書数を求める
単語が出現し
た文書数を求 リストから
文書で出現した
める 単語が出現した
単語のリスト
文書数を求める
46
- 47.
- 48.
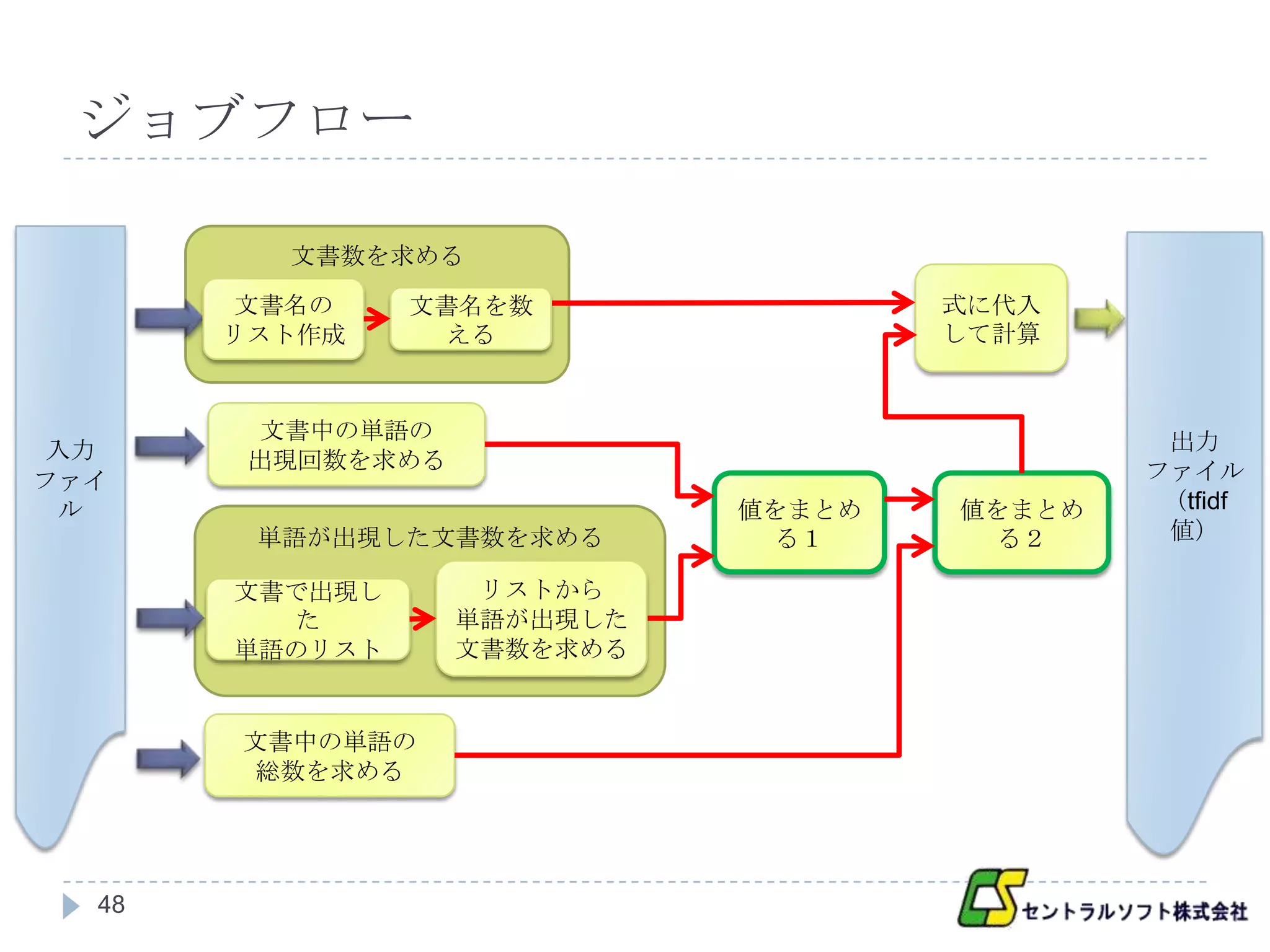
ジョブフロー
文書数を求める
文書名の 文書名を数 式に代入
リスト作成 える して計算
文書中の単語の 出力
入力 出現回数を求める
ファイ ファイル
ル 値をまとめ 値をまとめ (tfidf
単語が出現した文書数を求める る1 る2 値)
文書で出現し リストから
た 単語が出現した
単語のリスト 文書数を求める
文書中の単語の
総数を求める
48
- 49.
- 50.
まとめ
アルゴリズムからジョブフローにする手順
1. 大まかな処理に分ける
2. 処理の入出力を考える
3. データを Reduce からの参照のされ方で分ける
1. 全ての Reduce
2. 全てではないが複数の Reduce
3. 一つの Reduce
4. 処理ごとに簡単な MapReduce で実現できるか検討し、
必要に応じてジョブを増やす
50
- 51.
次回の予定
MapReduce プログラミング基礎とプログラミングテ
クニック
ワードカウント
k-means
TF-IDF
51











![処理2検討
<クラスタ1, A><クラスタ2, B>
<クラスタ1, C>
Map 出力
Shuffle & Sort で同じクラスタは一纏まりになり、
Shuffle & Sort
その纏まりでクラスタの重心が計算できる
<クラスタ1, [A , C]> <クラスタ2, [B]>
1回の MapReduce で実現できそう
Reduce 入力
21](https://image.slidesharecdn.com/hadoop-120228224805-phpapp02/75/Hadoop-20120228-21-2048.jpg)