Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Makoto SAKAI
4,703 views
計算量のはなし(Redisを使うなら必読!O(logN)など)
社内勉強会でO(logN)とかをわかり易く説明しました
Software
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 13
2
/ 13
3
/ 13
4
/ 13
Most read
5
/ 13
6
/ 13
7
/ 13
8
/ 13
Most read
9
/ 13
10
/ 13
11
/ 13
Most read
12
/ 13
13
/ 13
More Related Content
PDF
強いて言えば「集約どう実装するのかな、を考える」な話
by
Yoshitaka Kawashima
PDF
マイクロサービス 4つの分割アプローチ
by
増田 亨
PDF
ソフトウェア設計の学び方を考える
by
増田 亨
PDF
Mercari JPのモノリスサービスをKubernetesに移行した話 PHP Conference 2022 9/24
by
Shin Ohno
PDF
わたくし、やっぱりCDKを使いたいですわ〜CDK import編〜.pdf
by
ssuser868e2d
PDF
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
PDF
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話
by
Koichiro Matsuoka
PDF
いまさら聞けないDocker - 第5回コンテナ型仮想化の情報交換会@大阪
by
Kunihiro TANAKA
強いて言えば「集約どう実装するのかな、を考える」な話
by
Yoshitaka Kawashima
マイクロサービス 4つの分割アプローチ
by
増田 亨
ソフトウェア設計の学び方を考える
by
増田 亨
Mercari JPのモノリスサービスをKubernetesに移行した話 PHP Conference 2022 9/24
by
Shin Ohno
わたくし、やっぱりCDKを使いたいですわ〜CDK import編〜.pdf
by
ssuser868e2d
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話
by
Koichiro Matsuoka
いまさら聞けないDocker - 第5回コンテナ型仮想化の情報交換会@大阪
by
Kunihiro TANAKA
What's hot
PDF
"Kong Summit, Japan 2022" パートナーセッション:Kong on AWS で実現するスケーラブルな API 基盤の構築
by
Junji Nishihara
PDF
ブレソルでテラバイト級データのALTERを短時間で終わらせる
by
KLab Inc. / Tech
PDF
Beyond the Twelve-Factor App
by
Kazuya Takahashi
PPTX
テストコードの DRY と DAMP
by
Yusuke Kagata
PDF
怖くないSpring Bootのオートコンフィグレーション
by
土岐 孝平
PDF
MonotaRO のデータ活用と基盤の過去、現在、未来
by
株式会社MonotaRO Tech Team
PDF
Node.js Native ESM への道 〜最終章: Babel / TypeScript Modules との闘い〜
by
Teppei Sato
PDF
新たなgitのブランチモデル「Git Feature Flow」!Git Flow,Git Hub Flow,Git Lab Flowを超えれるか?
by
naoki koyama
PDF
Spring Boot の Web アプリケーションを Docker に載せて AWS ECS で動かしている話
by
JustSystems Corporation
PDF
やりなおせる Git 入門
by
Tomohiko Himura
PPTX
kubernetes初心者がKnative Lambda Runtime触ってみた(Kubernetes Novice Tokyo #13 発表資料)
by
NTT DATA Technology & Innovation
PDF
ドメイン駆動設計のための Spring の上手な使い方
by
増田 亨
PPTX
BuildKitによる高速でセキュアなイメージビルド
by
Akihiro Suda
PPTX
マスタデータの管理と運用について
by
Kentarou Takeda
PDF
webエンジニアのためのはじめてのredis
by
nasa9084
PPTX
脱RESTful API設計の提案
by
樽八 仲川
PDF
超実践 Cloud Spanner 設計講座
by
Samir Hammoudi
PDF
ドメイン駆動で開発する ラフスケッチから実装まで
by
増田 亨
PDF
Zabbix最新情報 ~Zabbix 6.0に向けて~ @OSC2021 Online/Fall
by
Atsushi Tanaka
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
"Kong Summit, Japan 2022" パートナーセッション:Kong on AWS で実現するスケーラブルな API 基盤の構築
by
Junji Nishihara
ブレソルでテラバイト級データのALTERを短時間で終わらせる
by
KLab Inc. / Tech
Beyond the Twelve-Factor App
by
Kazuya Takahashi
テストコードの DRY と DAMP
by
Yusuke Kagata
怖くないSpring Bootのオートコンフィグレーション
by
土岐 孝平
MonotaRO のデータ活用と基盤の過去、現在、未来
by
株式会社MonotaRO Tech Team
Node.js Native ESM への道 〜最終章: Babel / TypeScript Modules との闘い〜
by
Teppei Sato
新たなgitのブランチモデル「Git Feature Flow」!Git Flow,Git Hub Flow,Git Lab Flowを超えれるか?
by
naoki koyama
Spring Boot の Web アプリケーションを Docker に載せて AWS ECS で動かしている話
by
JustSystems Corporation
やりなおせる Git 入門
by
Tomohiko Himura
kubernetes初心者がKnative Lambda Runtime触ってみた(Kubernetes Novice Tokyo #13 発表資料)
by
NTT DATA Technology & Innovation
ドメイン駆動設計のための Spring の上手な使い方
by
増田 亨
BuildKitによる高速でセキュアなイメージビルド
by
Akihiro Suda
マスタデータの管理と運用について
by
Kentarou Takeda
webエンジニアのためのはじめてのredis
by
nasa9084
脱RESTful API設計の提案
by
樽八 仲川
超実践 Cloud Spanner 設計講座
by
Samir Hammoudi
ドメイン駆動で開発する ラフスケッチから実装まで
by
増田 亨
Zabbix最新情報 ~Zabbix 6.0に向けて~ @OSC2021 Online/Fall
by
Atsushi Tanaka
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
Viewers also liked
PDF
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
PDF
AWS Black Belt Online Seminar 2017 Amazon Athena
by
Amazon Web Services Japan
PDF
AWS Black Belt Online Seminar 2017 Auto Scaling
by
Amazon Web Services Japan
PDF
AWS Black Belt Online Seminar AWSで実現するDisaster Recovery
by
Amazon Web Services Japan
PDF
統計学の基礎の基礎
by
Ken'ichi Matsui
PDF
ggplot2によるグラフ化@HijiyamaR#2
by
nocchi_airport
KEY
AdServerの仕組み
by
Eiji Kuroda
PDF
論理と計算のしくみ 5.3 型付きλ計算 (前半)
by
Lintaro Ina
PDF
AWS Black Belt Online Seminar 2017 Amazon EC2 Systems Manager
by
Amazon Web Services Japan
PDF
AWS Black Belt Online Seminar 2017 IoT向け最新アーキテクチャパターン
by
Amazon Web Services Japan
PDF
AWS Shieldのご紹介 Managed DDoS Protection
by
Amazon Web Services Japan
PDF
基礎からのベイズ統計学 輪読会資料 第1章 確率に関するベイズの定理
by
Ken'ichi Matsui
PPTX
SunspotではじめるSolr入門
by
Takao Baba
PDF
ユーザーからみたre:Inventのこれまでと今後
by
Recruit Technologies
PDF
グローバルハイテク企業で働くということ
by
Takuya Oikawa
PDF
計算量とオーダー
by
京大 マイコンクラブ
PDF
AWS Black Belt Online Seminar 2017 Docker on AWS
by
Amazon Web Services Japan
PDF
10 SQL Tricks that You Didn't Think Were Possible
by
Lukas Eder
PDF
言語と画像の表現学習
by
Yuki Noguchi
PDF
基礎からのベイズ統計学 2章 勉強会資料
by
at grandpa
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
AWS Black Belt Online Seminar 2017 Amazon Athena
by
Amazon Web Services Japan
AWS Black Belt Online Seminar 2017 Auto Scaling
by
Amazon Web Services Japan
AWS Black Belt Online Seminar AWSで実現するDisaster Recovery
by
Amazon Web Services Japan
統計学の基礎の基礎
by
Ken'ichi Matsui
ggplot2によるグラフ化@HijiyamaR#2
by
nocchi_airport
AdServerの仕組み
by
Eiji Kuroda
論理と計算のしくみ 5.3 型付きλ計算 (前半)
by
Lintaro Ina
AWS Black Belt Online Seminar 2017 Amazon EC2 Systems Manager
by
Amazon Web Services Japan
AWS Black Belt Online Seminar 2017 IoT向け最新アーキテクチャパターン
by
Amazon Web Services Japan
AWS Shieldのご紹介 Managed DDoS Protection
by
Amazon Web Services Japan
基礎からのベイズ統計学 輪読会資料 第1章 確率に関するベイズの定理
by
Ken'ichi Matsui
SunspotではじめるSolr入門
by
Takao Baba
ユーザーからみたre:Inventのこれまでと今後
by
Recruit Technologies
グローバルハイテク企業で働くということ
by
Takuya Oikawa
計算量とオーダー
by
京大 マイコンクラブ
AWS Black Belt Online Seminar 2017 Docker on AWS
by
Amazon Web Services Japan
10 SQL Tricks that You Didn't Think Were Possible
by
Lukas Eder
言語と画像の表現学習
by
Yuki Noguchi
基礎からのベイズ統計学 2章 勉強会資料
by
at grandpa
Similar to 計算量のはなし(Redisを使うなら必読!O(logN)など)
PPTX
純粋関数型アルゴリズム入門
by
Kimikazu Kato
PDF
計算量
by
Ken Ogura
PDF
Nazoki
by
Ken Ogura
PDF
Square869120 contest #2
by
AtCoder Inc.
PDF
計算量のはなし
by
徹 稲盛
PPT
Algorithm 速いアルゴリズムを書くための基礎
by
Kenji Otsuka
PPTX
T69 episteme
by
えぴ 福田
PDF
PythonでテキストをJSONにした話(PyCon mini sapporo 2015)
by
Satoshi Yamada
PDF
AtCoder Regular Contest 017
by
AtCoder Inc.
PDF
K2PC Div1 E 暗号化
by
Kazuma Mikami
PPTX
計算量 Jyoken
by
reew2n
純粋関数型アルゴリズム入門
by
Kimikazu Kato
計算量
by
Ken Ogura
Nazoki
by
Ken Ogura
Square869120 contest #2
by
AtCoder Inc.
計算量のはなし
by
徹 稲盛
Algorithm 速いアルゴリズムを書くための基礎
by
Kenji Otsuka
T69 episteme
by
えぴ 福田
PythonでテキストをJSONにした話(PyCon mini sapporo 2015)
by
Satoshi Yamada
AtCoder Regular Contest 017
by
AtCoder Inc.
K2PC Div1 E 暗号化
by
Kazuma Mikami
計算量 Jyoken
by
reew2n
More from Makoto SAKAI
PDF
[Node-RED] ファンクションノードのデバッグどうしてる?
by
Makoto SAKAI
PDF
プロのためのNode-RED再入門
by
Makoto SAKAI
PDF
プロジェクトを成功させるチケット管理
by
Makoto SAKAI
PDF
Node-RED導入時の効果的な開発を考える
by
Makoto SAKAI
PDF
(講演資料)開発現場で役立つ論文の書き方のお話
by
Makoto SAKAI
PDF
改訂版:開発現場で役立つ論文の書き方のお話
by
Makoto SAKAI
PDF
スクリプト言語入門 - シェル芸のすすめ - 第2回クラウド勉強会
by
Makoto SAKAI
PDF
複合主キーの扱い方
by
Makoto SAKAI
PDF
Node-REDから見えた未来 - 変わるもの、変わらないもの -
by
Makoto SAKAI
PDF
論理的思考力を身に着けるための論文研修
by
Makoto SAKAI
PDF
SQiP20222投稿応援フォーラム「開発現場で役立つ論文の書き方のお話」
by
Makoto SAKAI
PDF
新技術で未来の扉を開け! - Node-REDの環境構築と社内導入 -
by
Makoto SAKAI
PDF
Node-redでプロトタイピング
by
Makoto SAKAI
PDF
Visual開発ツールNode-REDの導入によるプロセスの変化と考慮点
by
Makoto SAKAI
PDF
チケットの利用による経験を活かした開発の可能性
by
Makoto SAKAI
PDF
プロセスモデルの補完方法 -モデル・ノウハウ・人-
by
Makoto SAKAI
PDF
UAS5 アジャイル開発に学んだアダプタブルウォーターフォール開発
by
Makoto SAKAI
PDF
プロセスモデルの補完方法 -モデル・ノウハウ・人-
by
Makoto SAKAI
PDF
SS2019 エッジデバイス開発の難しさ
by
Makoto SAKAI
PDF
メールやチャットでも役立つテクニック
by
Makoto SAKAI
[Node-RED] ファンクションノードのデバッグどうしてる?
by
Makoto SAKAI
プロのためのNode-RED再入門
by
Makoto SAKAI
プロジェクトを成功させるチケット管理
by
Makoto SAKAI
Node-RED導入時の効果的な開発を考える
by
Makoto SAKAI
(講演資料)開発現場で役立つ論文の書き方のお話
by
Makoto SAKAI
改訂版:開発現場で役立つ論文の書き方のお話
by
Makoto SAKAI
スクリプト言語入門 - シェル芸のすすめ - 第2回クラウド勉強会
by
Makoto SAKAI
複合主キーの扱い方
by
Makoto SAKAI
Node-REDから見えた未来 - 変わるもの、変わらないもの -
by
Makoto SAKAI
論理的思考力を身に着けるための論文研修
by
Makoto SAKAI
SQiP20222投稿応援フォーラム「開発現場で役立つ論文の書き方のお話」
by
Makoto SAKAI
新技術で未来の扉を開け! - Node-REDの環境構築と社内導入 -
by
Makoto SAKAI
Node-redでプロトタイピング
by
Makoto SAKAI
Visual開発ツールNode-REDの導入によるプロセスの変化と考慮点
by
Makoto SAKAI
チケットの利用による経験を活かした開発の可能性
by
Makoto SAKAI
プロセスモデルの補完方法 -モデル・ノウハウ・人-
by
Makoto SAKAI
UAS5 アジャイル開発に学んだアダプタブルウォーターフォール開発
by
Makoto SAKAI
プロセスモデルの補完方法 -モデル・ノウハウ・人-
by
Makoto SAKAI
SS2019 エッジデバイス開発の難しさ
by
Makoto SAKAI
メールやチャットでも役立つテクニック
by
Makoto SAKAI
計算量のはなし(Redisを使うなら必読!O(logN)など)
1.
計算量のはなし 株式会社SRA 阪井 誠 <sakai @
sra.co.jp>
2.
(時間)計算量 2 • 最近こんな記述を見ませんか? • O(1)
、O(N) 、 O(logN)とはどんな処理? ソート済みセット型のコマンド(Redisマニュアル) ZADD(key, score, member) New in version 1.1. 計算時間: O(log(N)) Nはソート済みセット内の要素数 Deque: 両端における append や pop を高速に行えるリスト風のコンテナ(Python) Deque はどちらの側からも append と pop が可能で、スレッドセーフでメモリ効率が よく、どちらの方向からもおよそ O(1) のパフォーマンスで実行できます。 list オブジェクトでも同様の操作を実現できますが、これは高速な固定長の操作に特 化されており、内部のデータ表現形式のサイズと位置を両方変えるような pop(0) や insert(0, v) などの操作ではメモリ移動のために O(n) のコストを必要とします。 (その他の操作)両端についてインデックスアクセスは O(1) ですが、中央部分につい ては O(n) の遅さです。高速なランダムアクセスが必要ならリストを使ってください。
3.
最大値の計算量 3 • 配列arrayにN個の正整数が入っています。 最大値を求めてください。 – 配列のサイズ:N –
配列のデータ:1,20,3,8,4,6,15,12,5,… – プログラム max=-1 indexをインクリメントして0~N-1まで繰り返す If max < array[index] max = array[index] ループは何回? データの追加の際のループは何回? 常にソートするとすれば、、
4.
最大値の計算量 4 • 配列arrayにN個の正整数が入っています。 最大値を求めてください。 – 配列のサイズ:N –
配列のデータ:1,20,3,8,4,6,15,12,5,… – プログラム max=-1 indexをインクリメントして0~N-1まで繰り返す If max > array[index] max = array[index] ループは何回?N(時間計算量)・・・これをO(N)と書く データの追加の際のループは何回?1・・・O(1) 常にソートするなら?N(位置決め+ずらす)・・・O(N)
5.
バブルソートの計算量 5 • 配列arrayにN個の正整数が入っています。 バブルソートしてください。 – 配列のサイズ:N –
配列のデータ:1,20,3,8,4,6,15,12,5,… – プログラム indexをインクリメントして0~N-1まで繰り返す index2をインクリメントしてindex~N-1まで繰り返す If array[index] > array[index2] array[index] と array[index2]を入れ替える ループは何回?約N2回 ・・・ O(N2)
6.
バイナリツリー 6 • ソートデータを2分木で管理すると階層回で追加・検索 4 5 1
3 6 8 12 15 20 ノード数 ・・・1 (2の0乗) ・・・2 (2の1乗) ・・・4 (2の2乗) ・・・8 (2の3乗) ・・・16 (2の4乗) 8 9
7.
Logの定義 7 • A =
logxN のとき xをA乗するとNになる • log28 は2を3乗すれば8(=2x2x2)なので3 • 情報系では2は省略してよいので log8 = 3 • 2分木は階層が深くなると葉が2倍に増える – 葉がN個なら深さはlogN • データの追加・検索はO(logN)で可能 – ソートにはN倍必要なのでO(NlogN)
8.
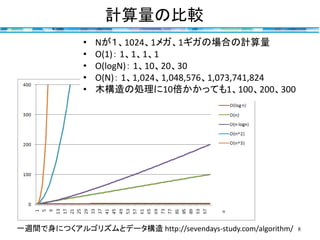
計算量の比較 8一週間で身につくアルゴリズムとデータ構造 http://sevendays-study.com/algorithm/ • Nが1、1024、1メガ、1ギガの場合の計算量 •
O(1): 1、1、1、1 • O(logN): 1、10、20、30 • O(N): 1、1,024、1,048,576、1,073,741,824 • 木構造の処理に10倍かかっても1、100、200、300
9.
まとめと気を付けること 9 • O(1) <
O(logN) < O(N) < O(N2) < O(N3) – O(NlogN)はどこでしょう? • 計算量の少ない処理を使う方が良い • ただし、呼び出しにN回ループを使っていると O(logN)はO(NlogN)となりO(N)より大きくなる • 全体の構造を意識してプログラムを設計しな いといけない
10.
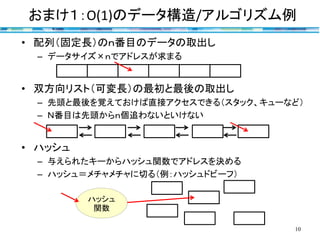
おまけ1:O(1)のデータ構造/アルゴリズム例 10 • 配列(固定長)のn番目のデータの取出し – データサイズ×nでアドレスが求まる •
双方向リスト(可変長)の最初と最後の取出し – 先頭と最後を覚えておけば直接アクセスできる(スタック、キューなど) – N番目は先頭からn個追わないといけない • ハッシュ – 与えられたキーからハッシュ関数でアドレスを決める – ハッシュ=メチャメチャに切る(例:ハッシュドビーフ) ハッシュ 関数
11.
おまけ2:計算量の応用分野 • ビッグデータ – 計算量の少ないアルゴリズムを用いて、大量デー タを効率よく扱う •
暗号 – 素因数分解など、計算量の多い難しい問題を利 用して強い暗号を作る • 人工知能 – 計算量の多いアルゴリズムはあきらめて、簡便な 方法を探す
12.
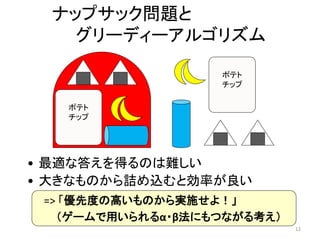
ナップサック問題と グリーディーアルゴリズム 12 ポテト チップ ポテト チップ • 最適な答えを得るのは難しい • 大きなものから詰め込むと効率が良い =>
「優先度の高いものから実施せよ!」 (ゲームで用いられるα・β法にもつながる考え)
13.
宿題 13 • それぞれのデータ構造/アルゴリズムを 考えてみましょう ソート済みセット型のコマンド(Redisマニュアル) ZADD(key, score,
member) New in version 1.1. 計算時間: O(log(N)) Nはソート済みセット内の要素数 Deque: 両端における append や pop を高速に行えるリスト風のコンテナ(Python) Deque はどちらの側からも append と pop が可能で、スレッドセーフでメモリ効率が よく、どちらの方向からもおよそ O(1) のパフォーマンスで実行できます。 list オブジェクトでも同様の操作を実現できますが、これは高速な固定長の操作に特 化されており、内部のデータ表現形式のサイズと位置を両方変えるような pop(0) や insert(0, v) などの操作ではメモリ移動のために O(n) のコストを必要とします。 (その他の操作)両端についてインデックスアクセスは O(1) ですが、中央部分につい ては O(n) の遅さです。高速なランダムアクセスが必要ならリストを使ってください。
Download



![最大値の計算量
3
• 配列arrayにN個の正整数が入っています。
最大値を求めてください。
– 配列のサイズ:N
– 配列のデータ:1,20,3,8,4,6,15,12,5,…
– プログラム
max=-1
indexをインクリメントして0~N-1まで繰り返す
If max < array[index]
max = array[index]
ループは何回?
データの追加の際のループは何回?
常にソートするとすれば、、](https://image.slidesharecdn.com/random-151002131842-lva1-app6891/85/Redis-O-logN-3-320.jpg)
![最大値の計算量
4
• 配列arrayにN個の正整数が入っています。
最大値を求めてください。
– 配列のサイズ:N
– 配列のデータ:1,20,3,8,4,6,15,12,5,…
– プログラム
max=-1
indexをインクリメントして0~N-1まで繰り返す
If max > array[index]
max = array[index]
ループは何回?N(時間計算量)・・・これをO(N)と書く
データの追加の際のループは何回?1・・・O(1)
常にソートするなら?N(位置決め+ずらす)・・・O(N)](https://image.slidesharecdn.com/random-151002131842-lva1-app6891/85/Redis-O-logN-4-320.jpg)
![バブルソートの計算量
5
• 配列arrayにN個の正整数が入っています。
バブルソートしてください。
– 配列のサイズ:N
– 配列のデータ:1,20,3,8,4,6,15,12,5,…
– プログラム
indexをインクリメントして0~N-1まで繰り返す
index2をインクリメントしてindex~N-1まで繰り返す
If array[index] > array[index2]
array[index] と array[index2]を入れ替える
ループは何回?約N2回 ・・・ O(N2)](https://image.slidesharecdn.com/random-151002131842-lva1-app6891/85/Redis-O-logN-5-320.jpg)
































































![[Node-RED] ファンクションノードのデバッグどうしてる?](https://cdn.slidesharecdn.com/ss_thumbnails/debugstyleoffunctionnode-190530142737-thumbnail.jpg?width=640&height=640&fit=bounds)


















