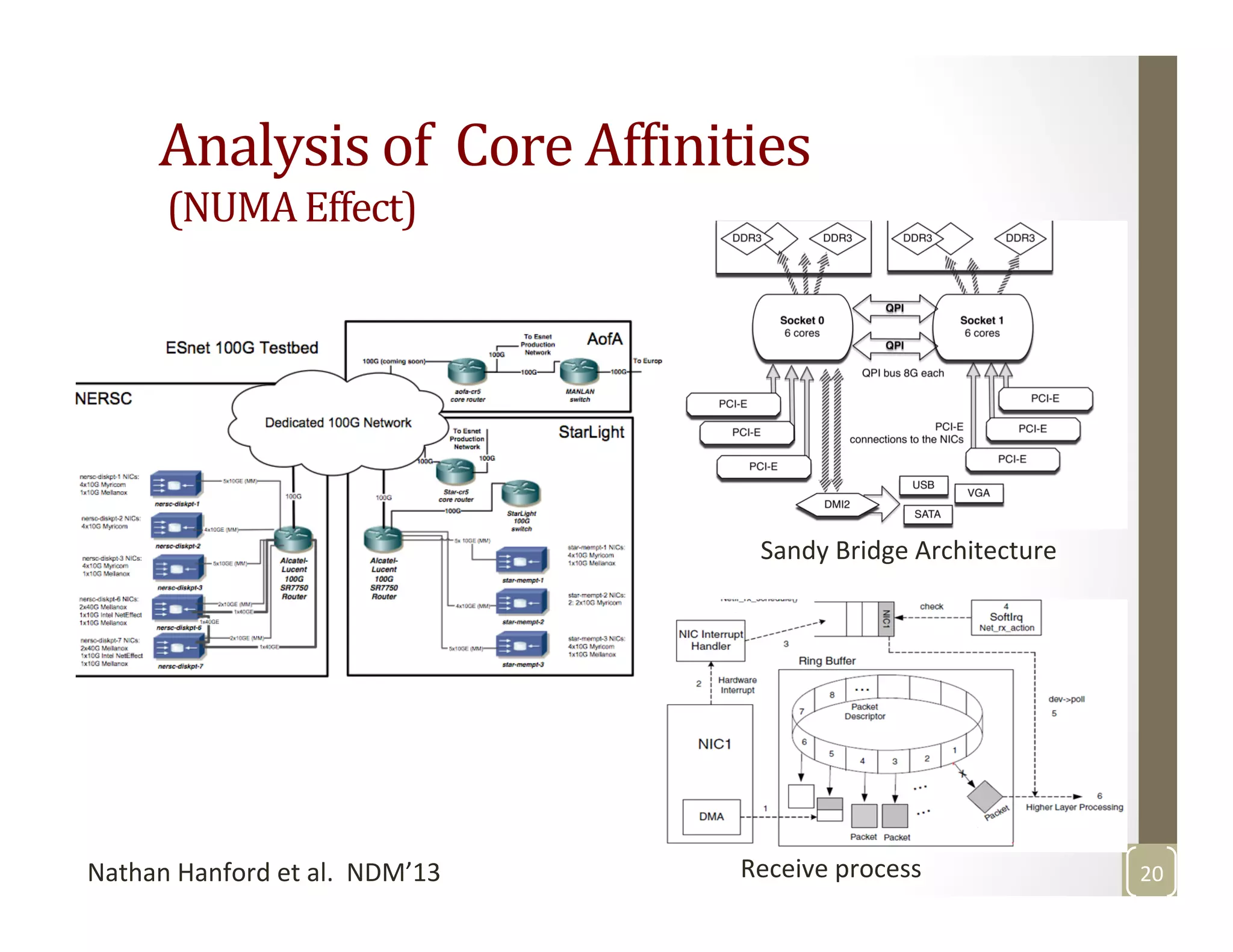
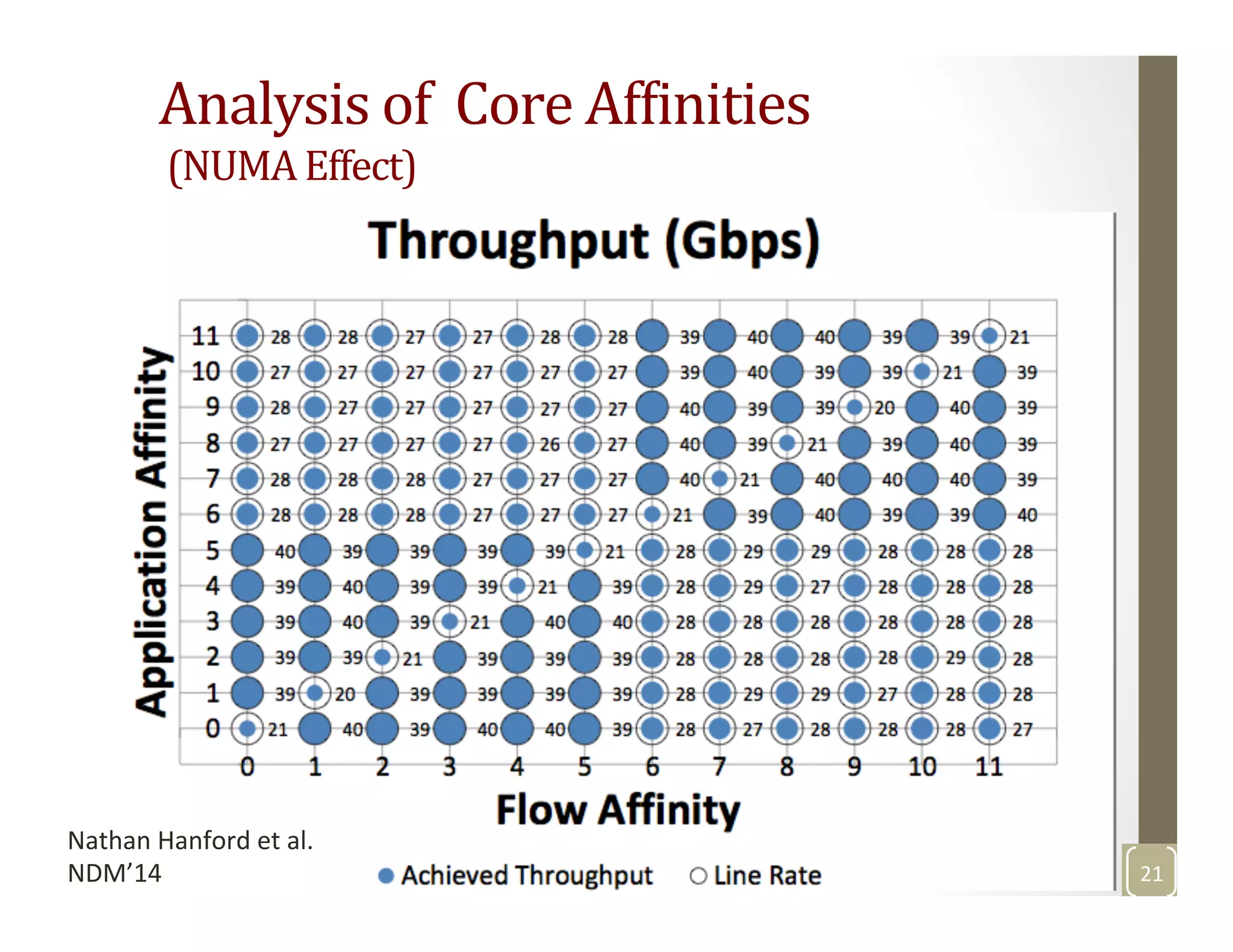
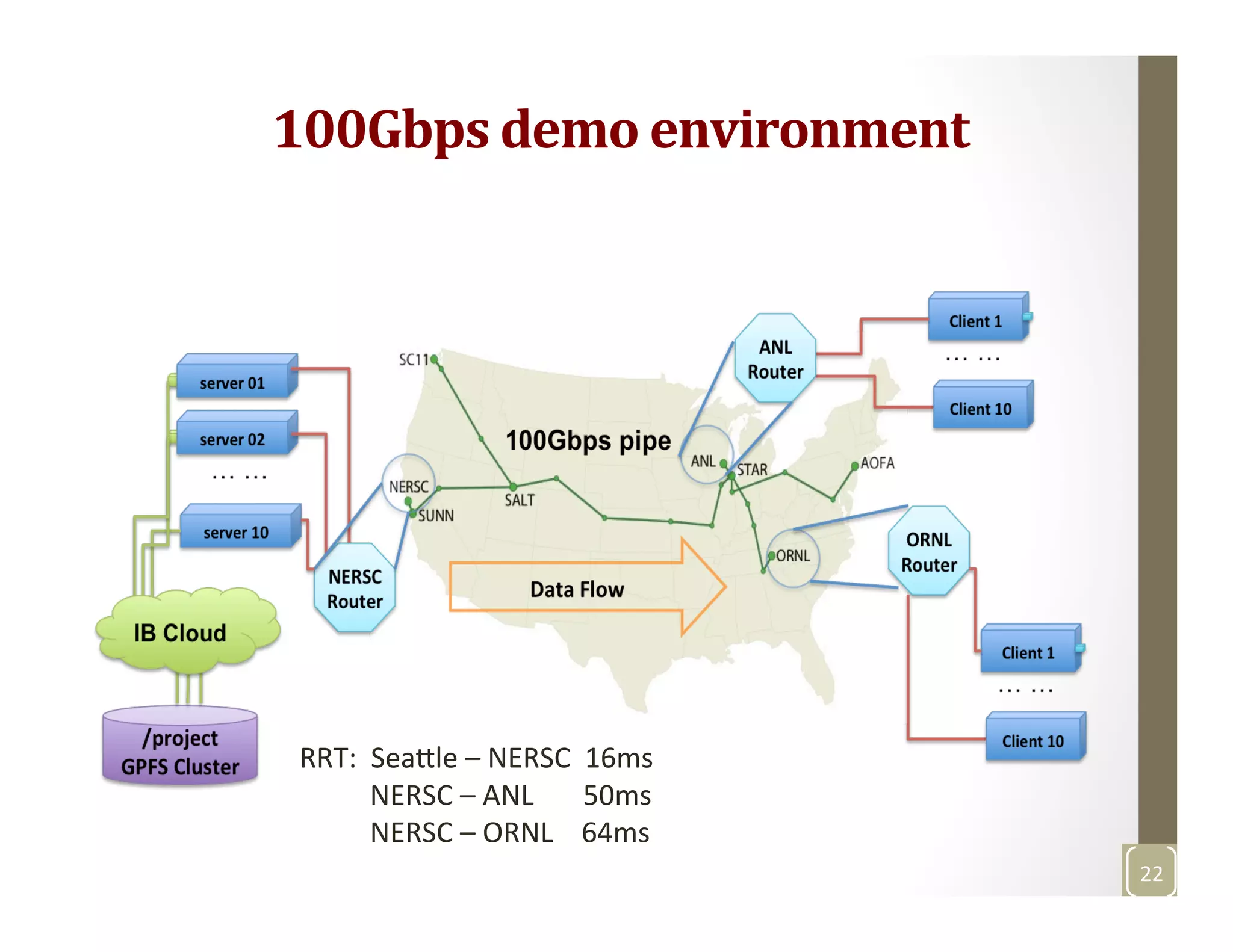
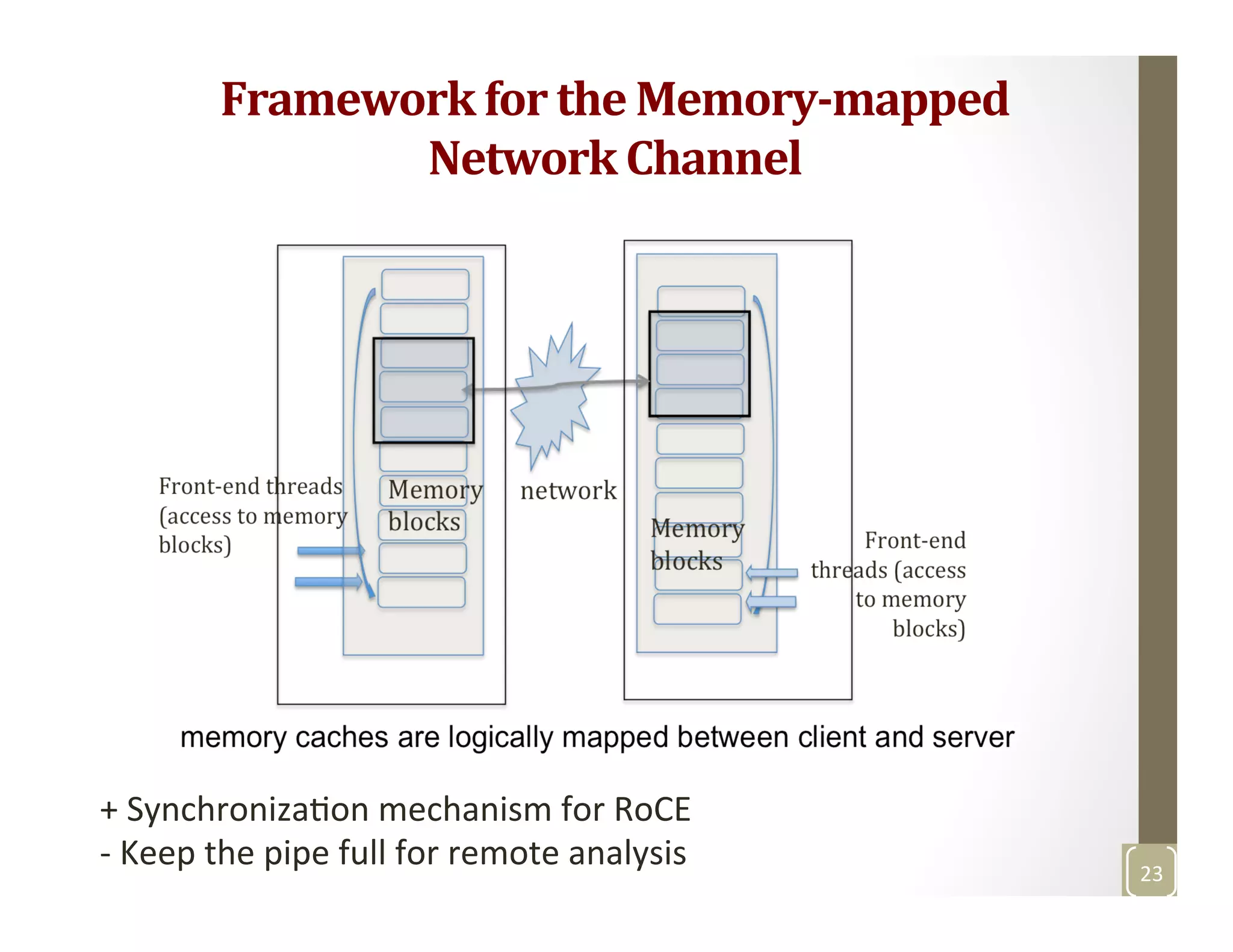
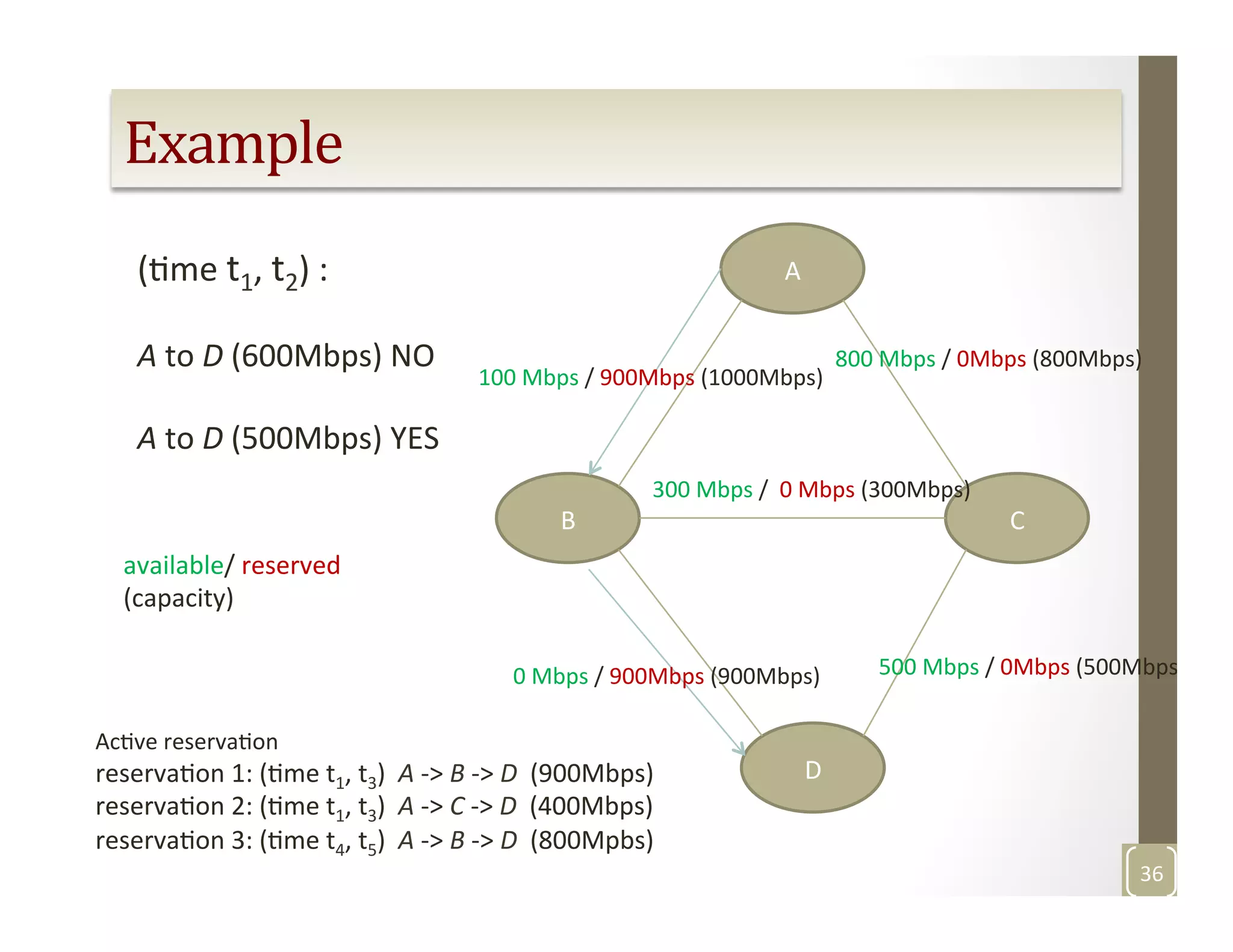
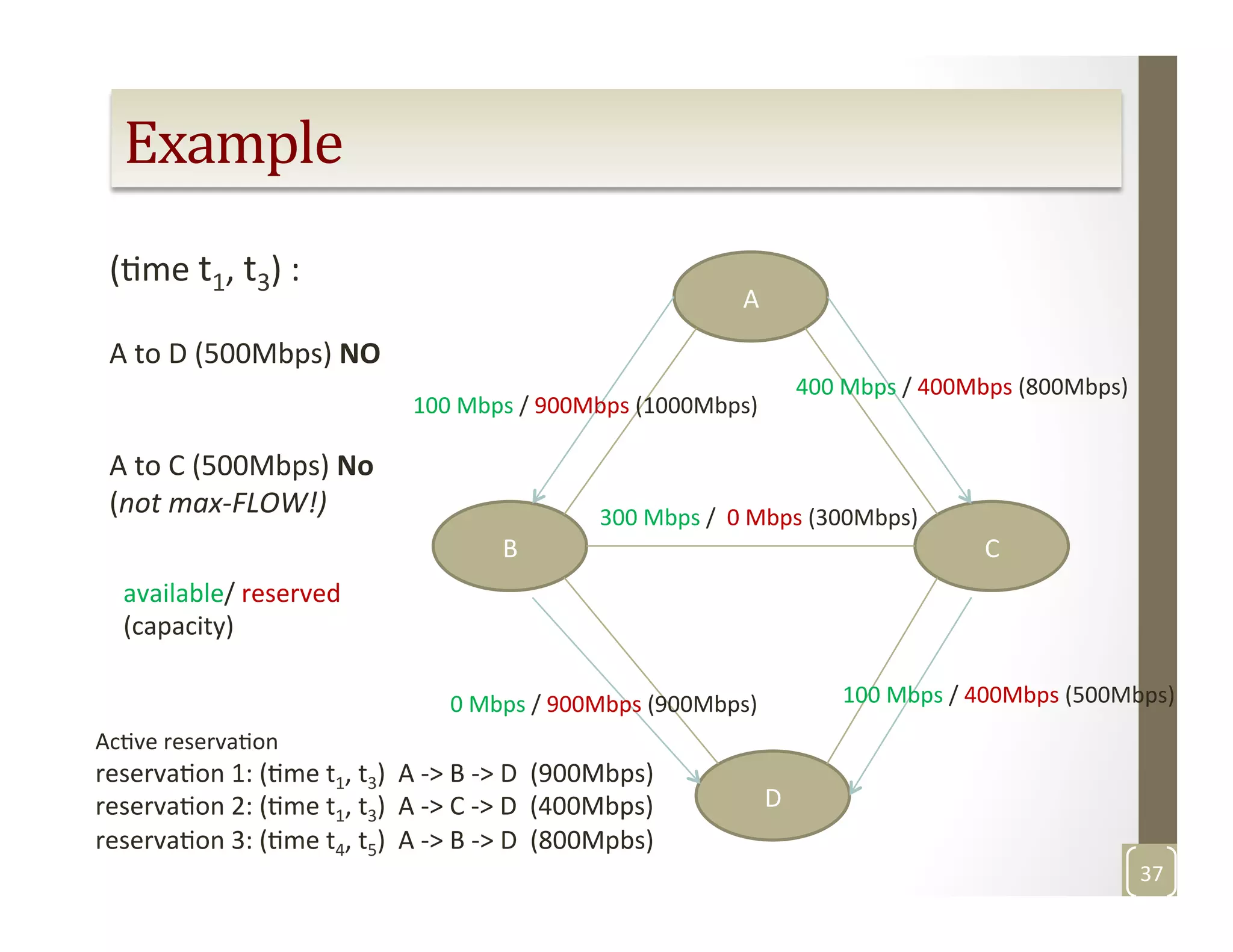
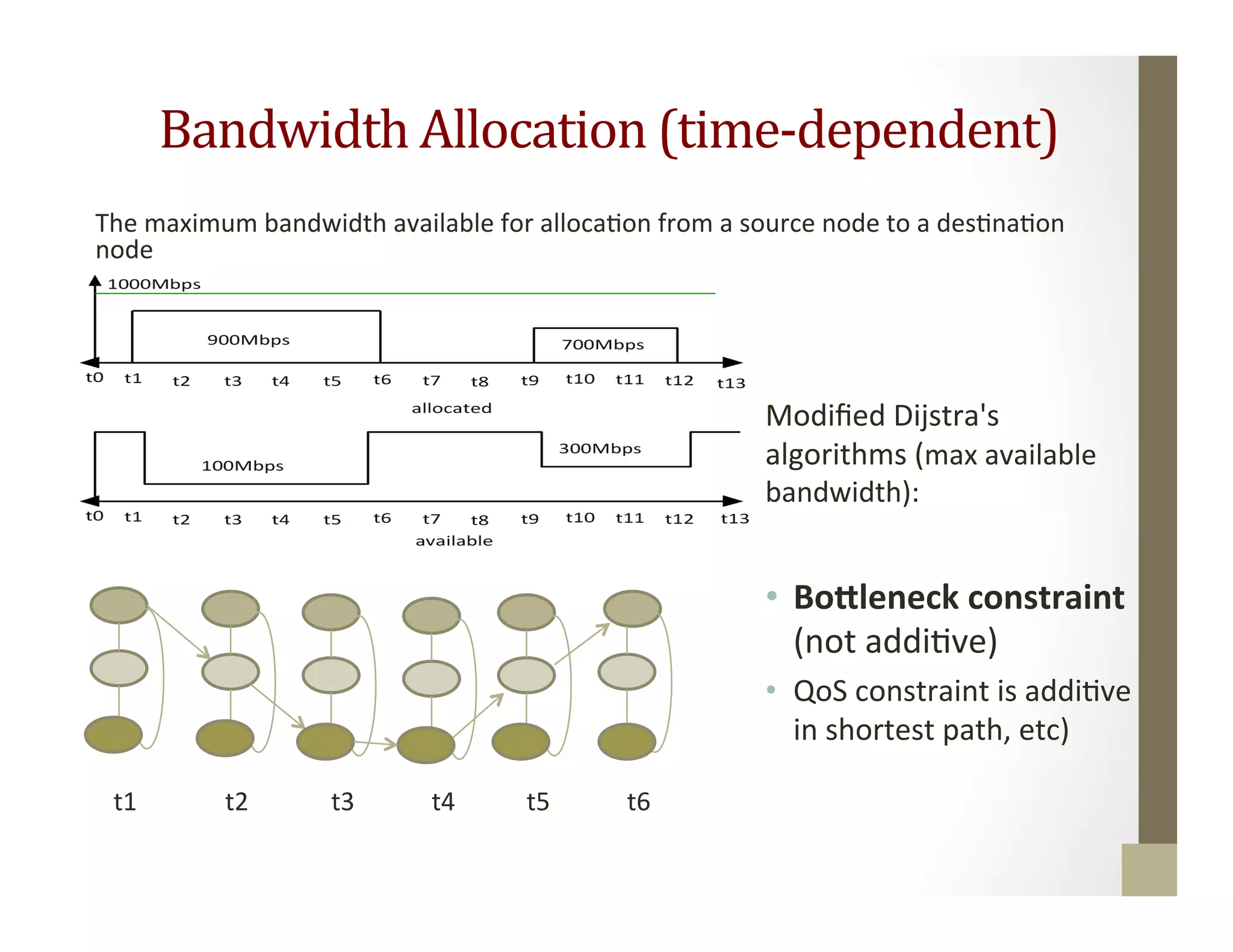
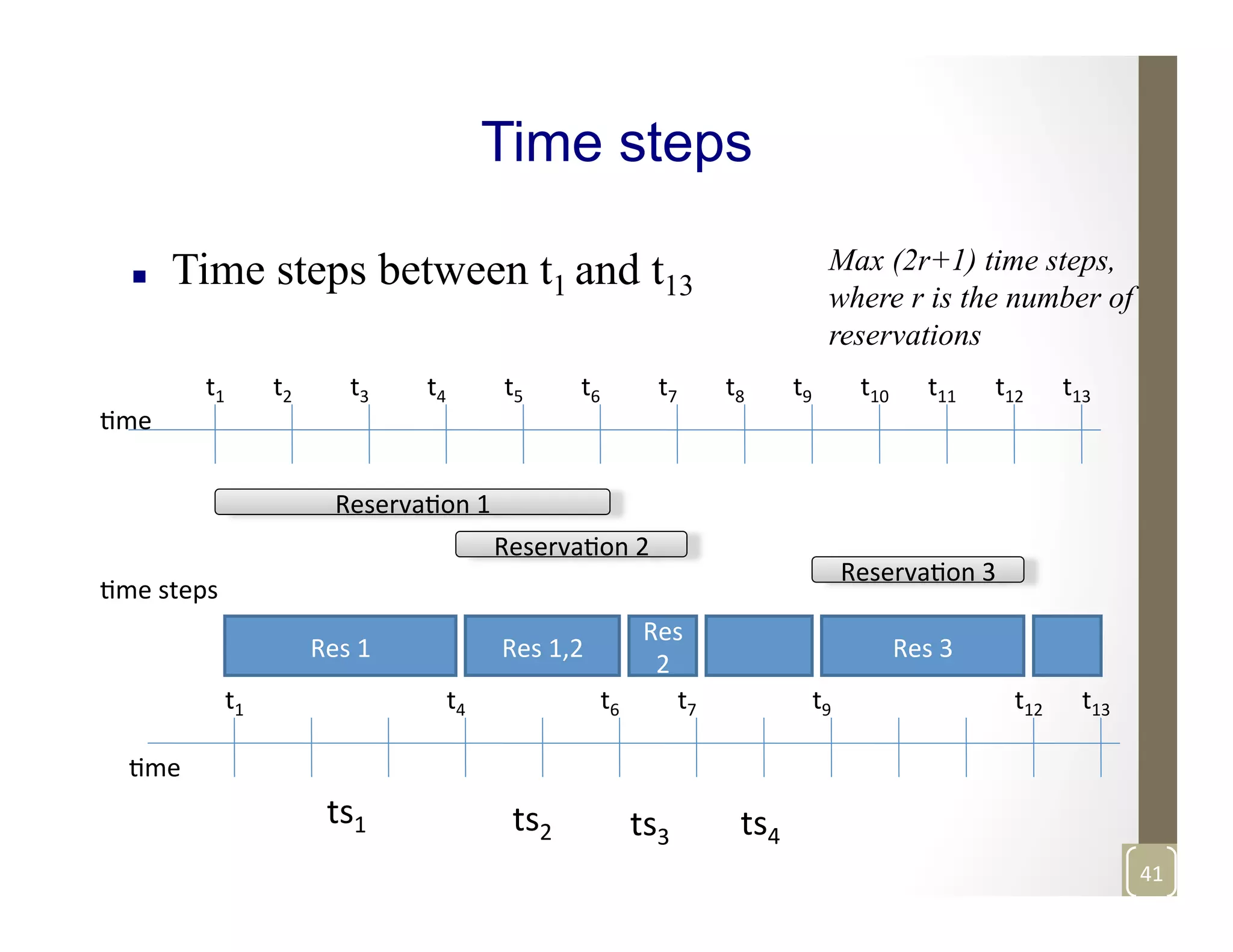
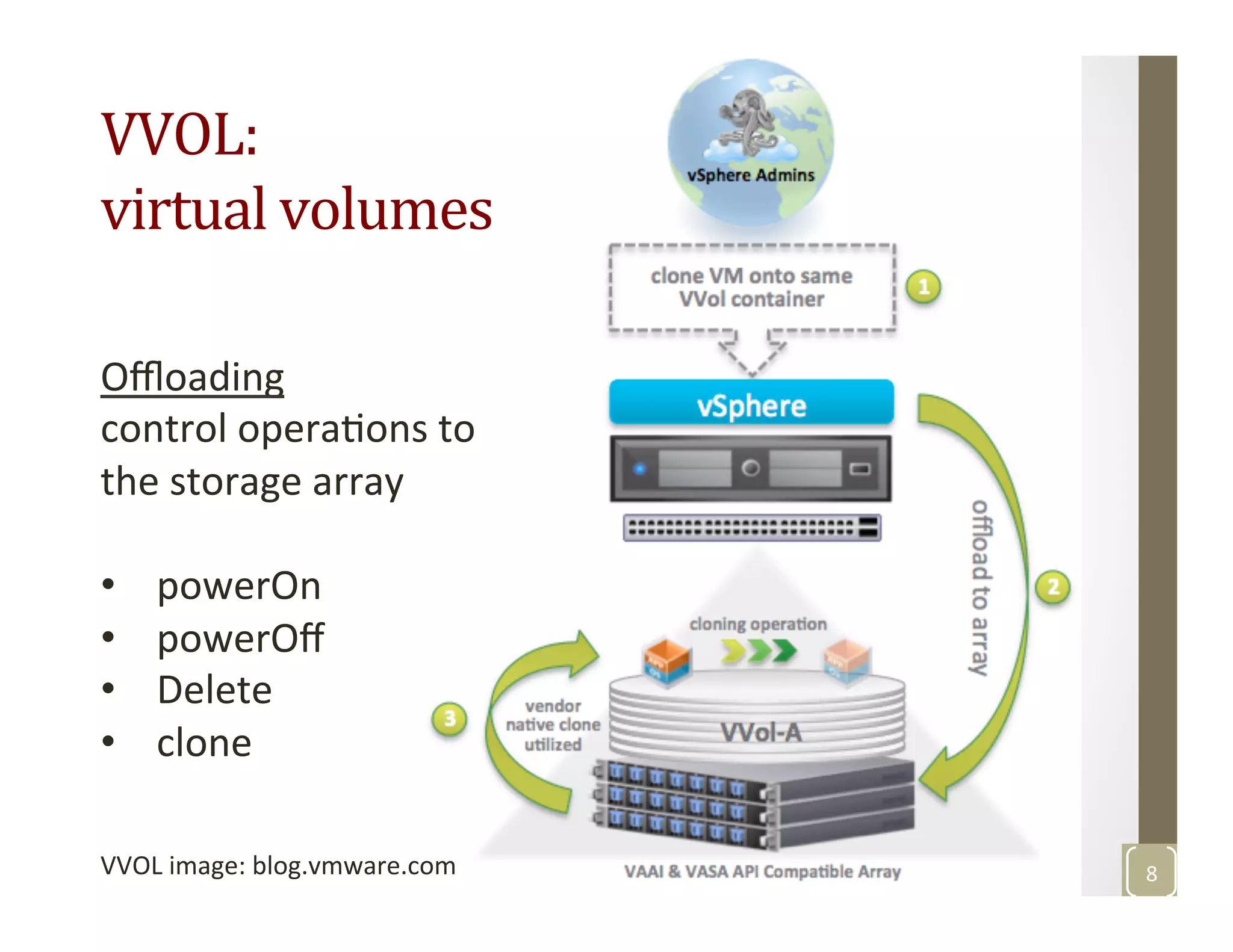
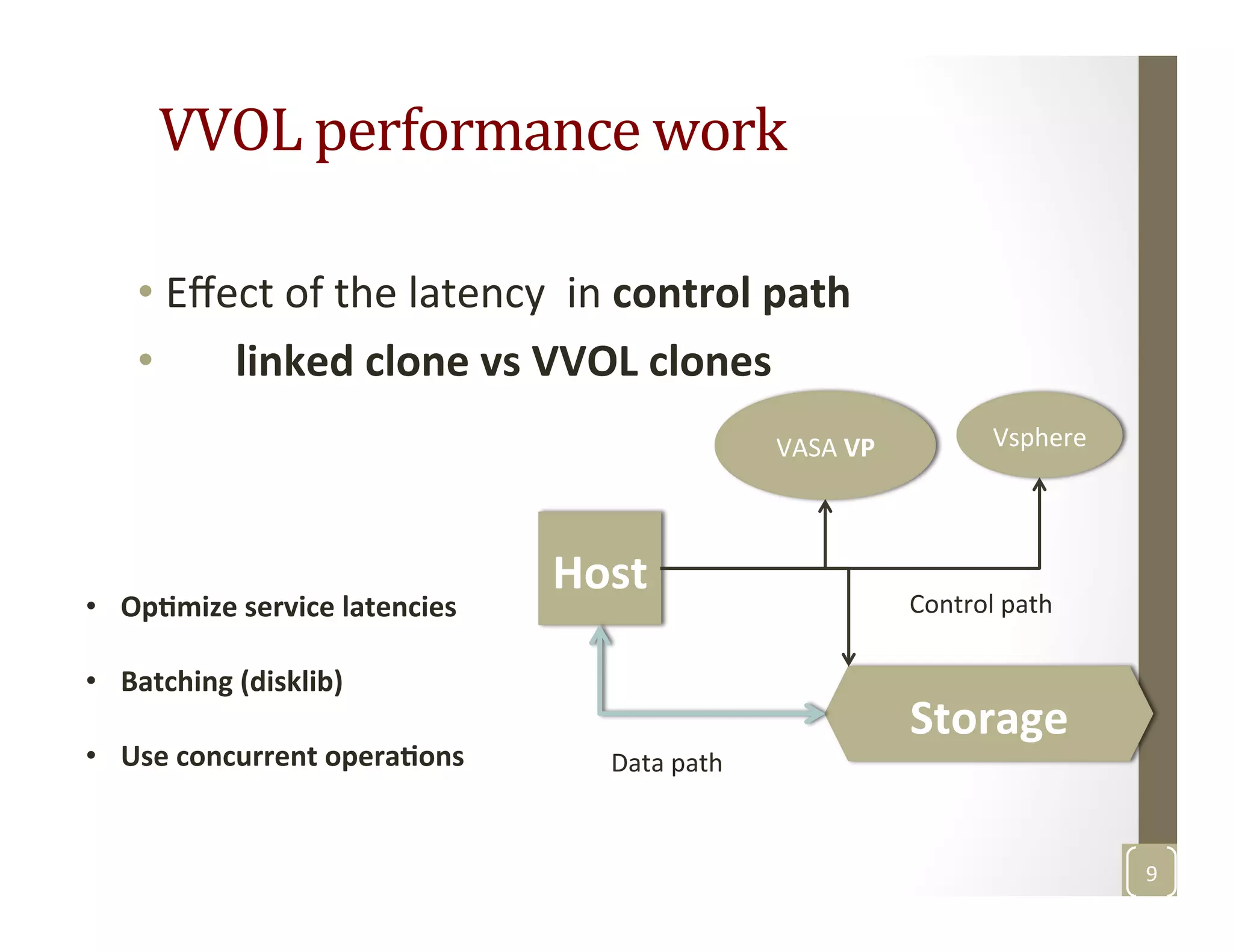
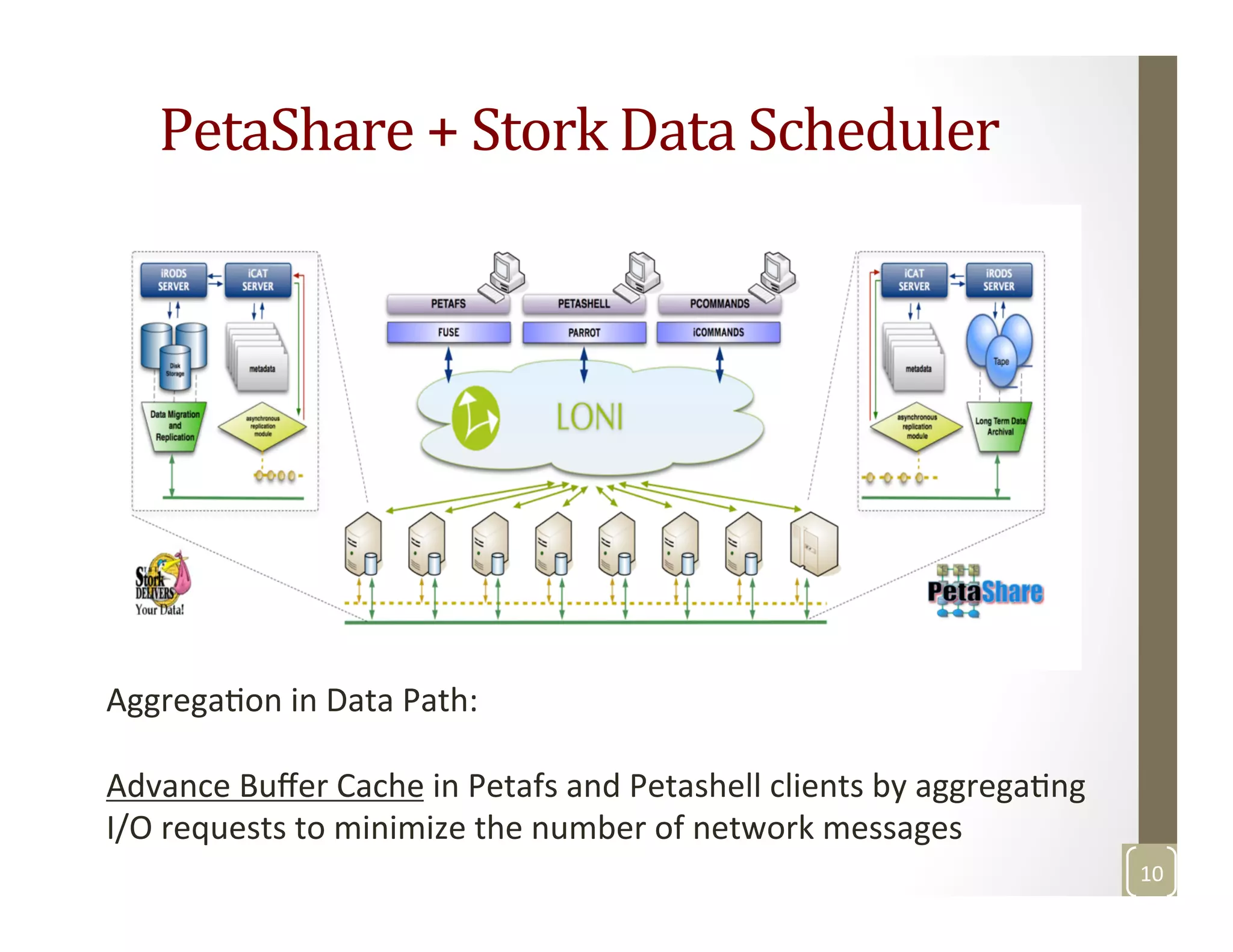
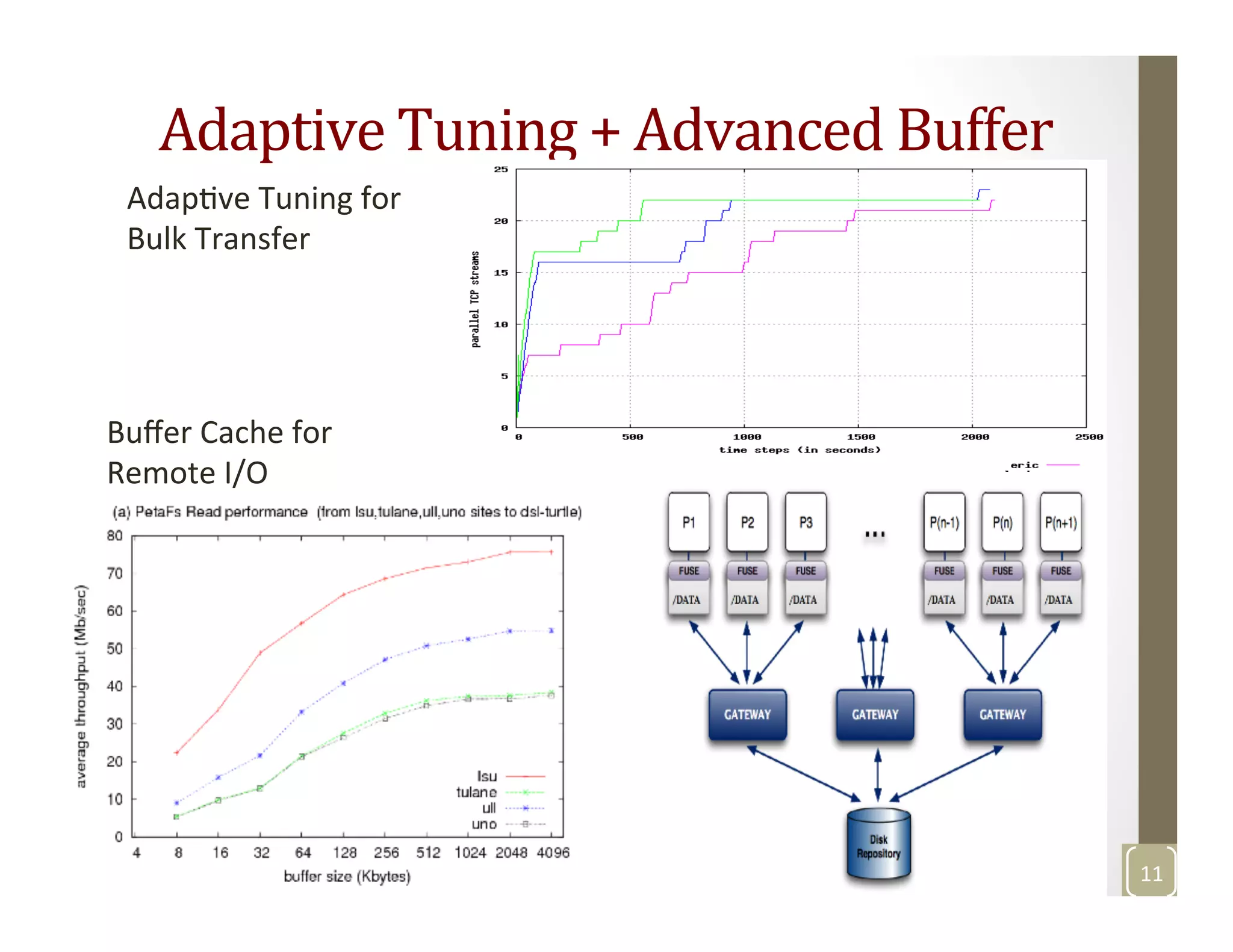
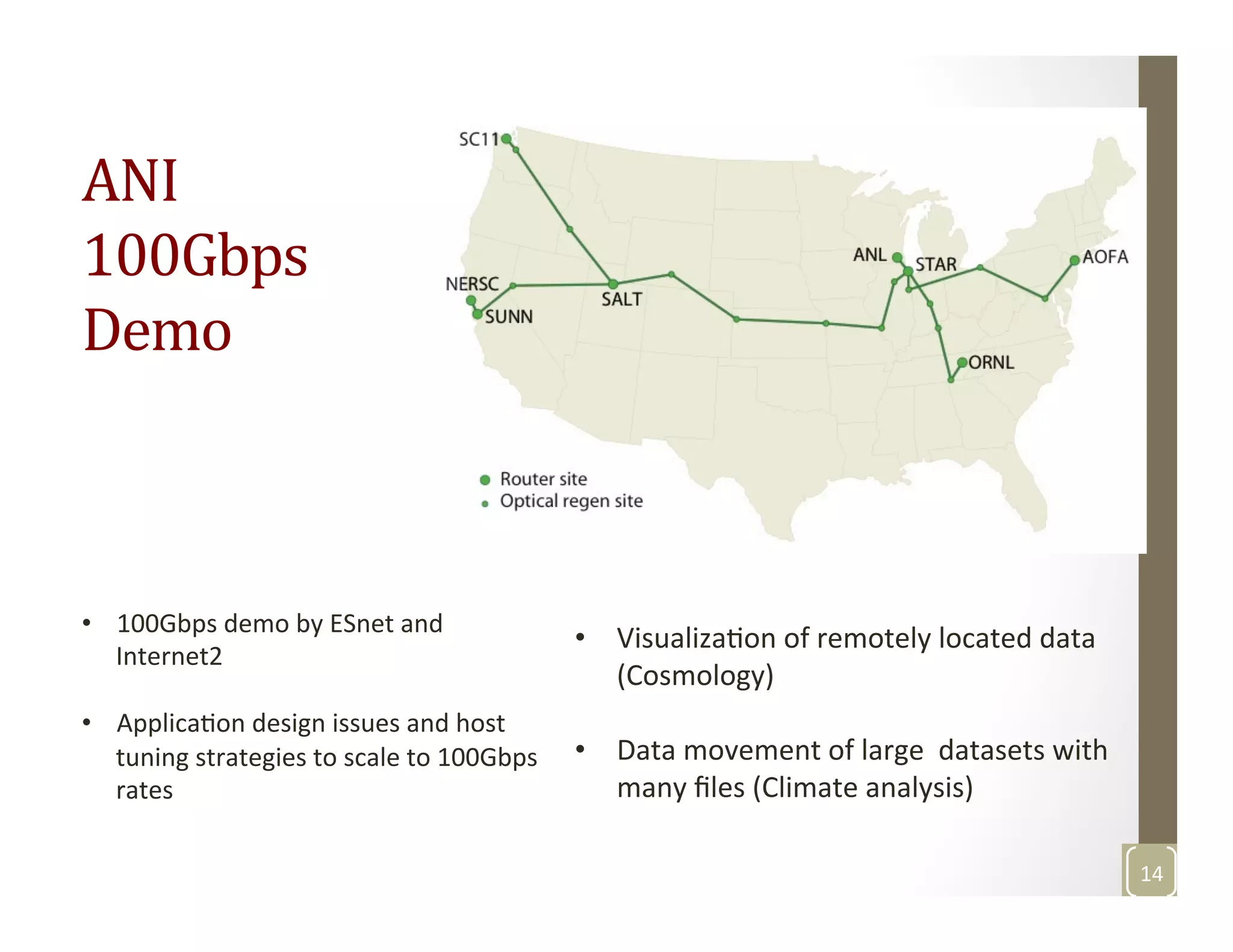
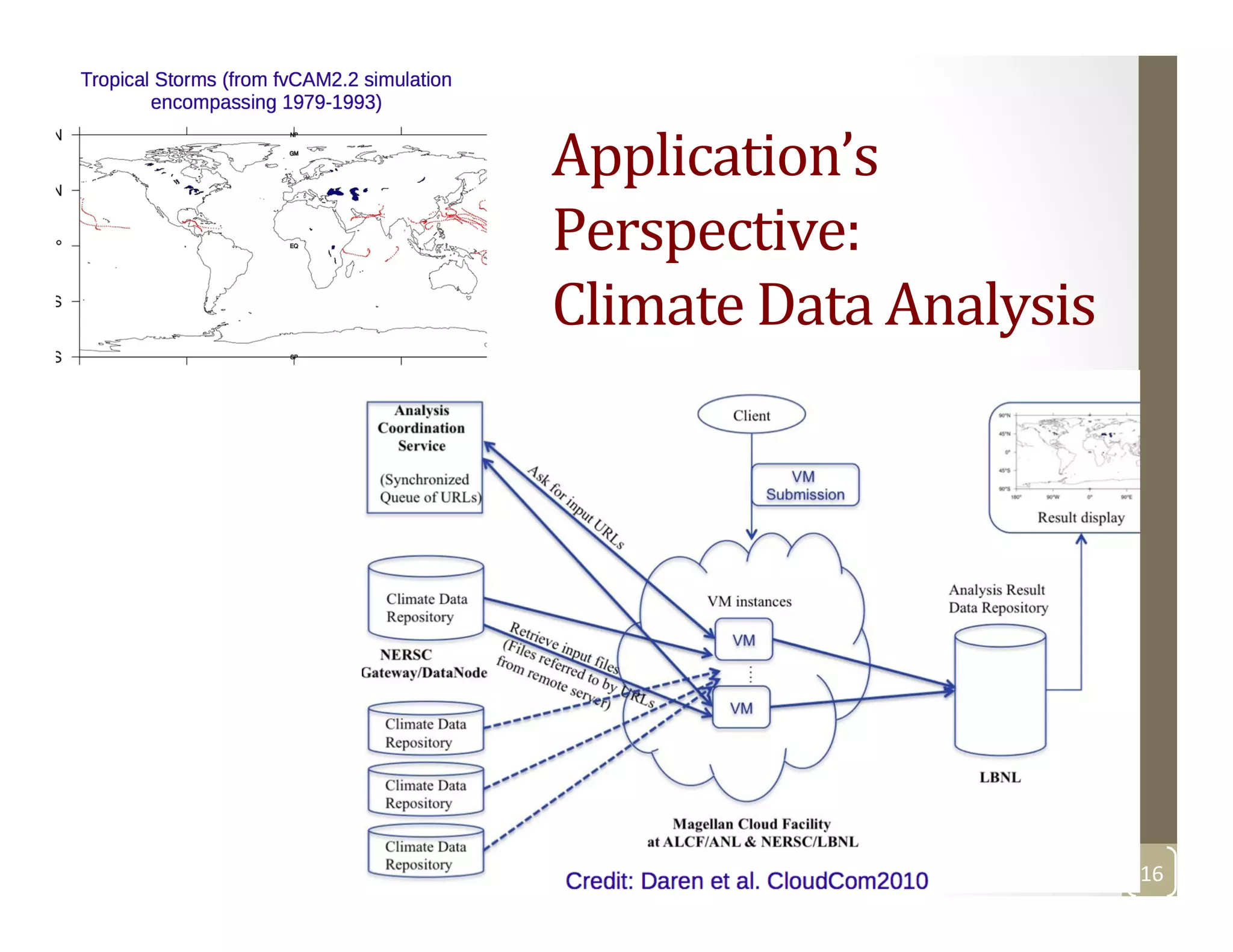
The document discusses network-aware data management for large-scale distributed applications. It provides an outline for a presentation on this topic, including discussing the performance of VSAN and VVOL storage in virtualized environments, the PetaShare distributed storage system and Stork data scheduler, data streaming in high-bandwidth networks, and several other related topics like network reservations and scheduling. The presenter's background and experience working on data transfer scheduling, distributed storage, and high-performance computing networks is also briefly summarized.










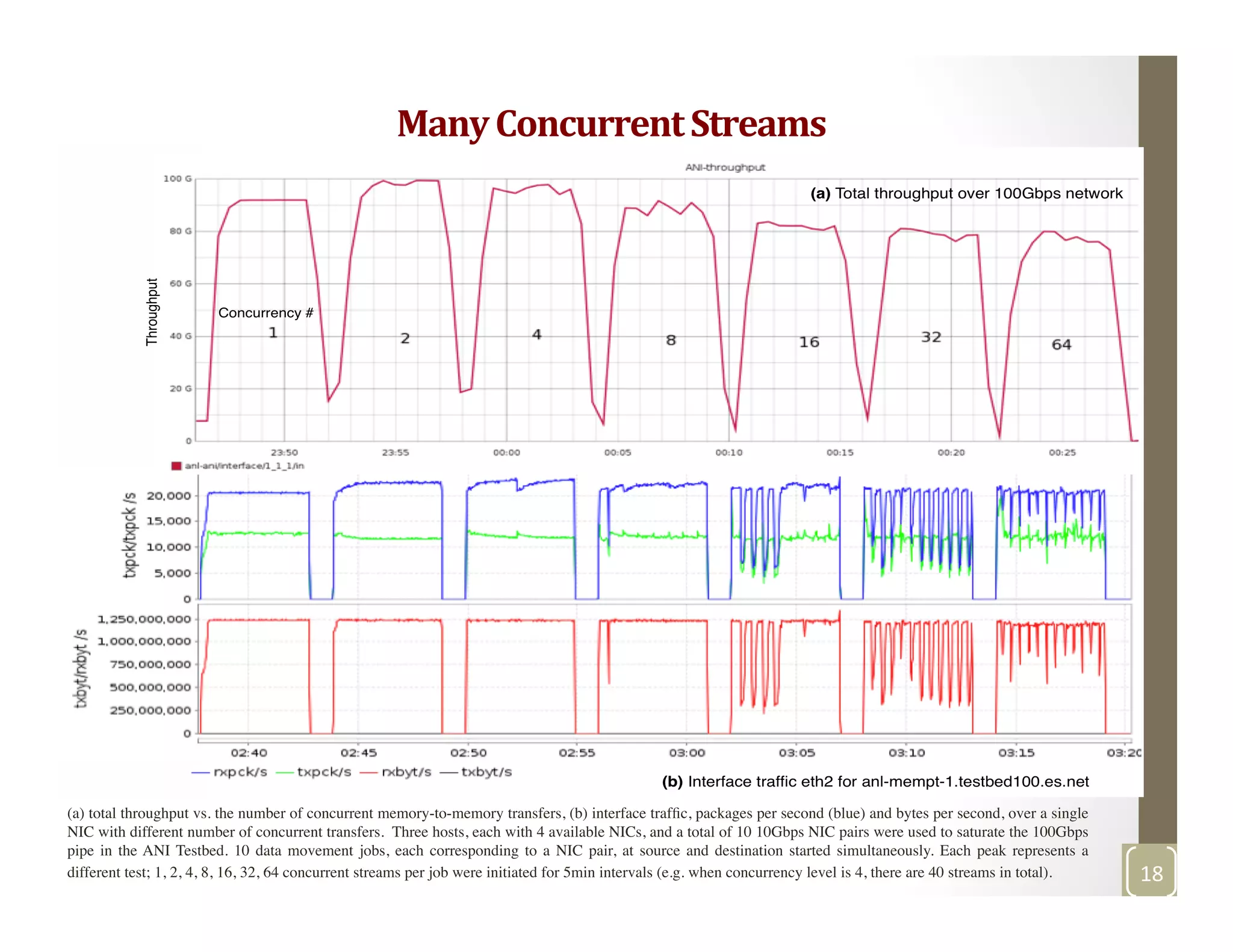
![ANI testbed 100Gbps (10x10NICs, three hosts): Interrupts/CPU vs the number of concurrent transfers [1, 2, 4, 8, 16, 32 64 concurrent jobs - 5min
intervals], TCP buffer size is 50M
Effects
of
many
concurrent
streams
19](https://image.slidesharecdn.com/talk-ibmresearch-almadenjune242015-161112010608/75/Network-aware-Data-Management-for-Large-Scale-Distributed-Applications-IBM-Research-Almaden-San-Jose-CA-June-24-2015-19-2048.jpg)