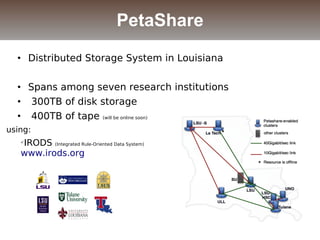
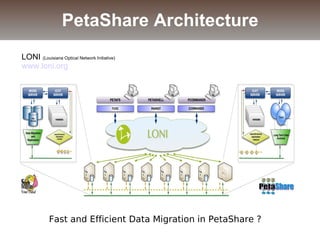
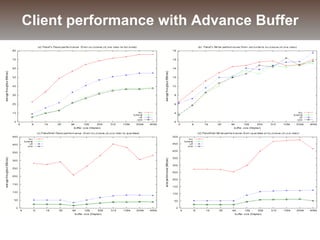
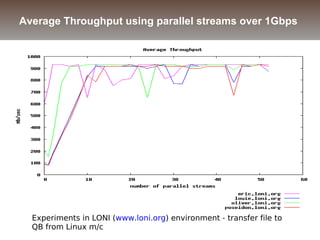
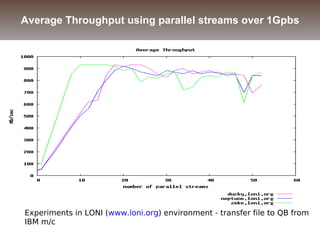
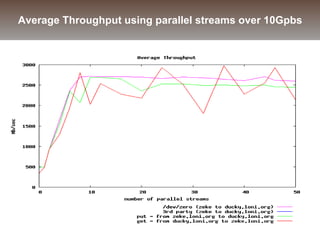
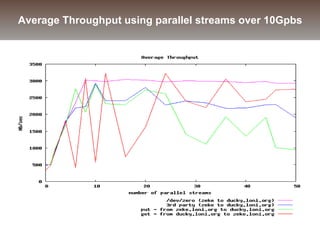
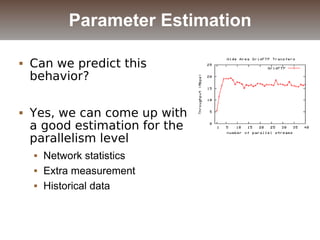
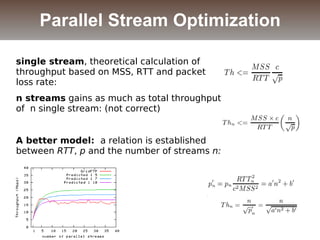
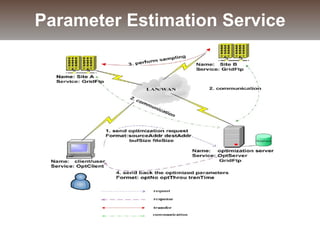
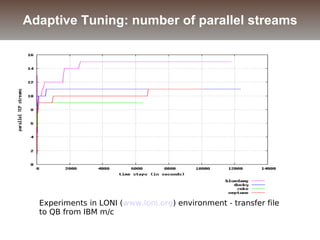
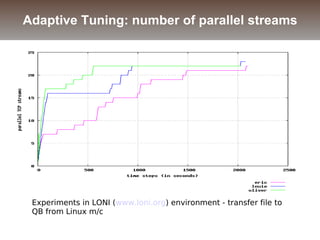
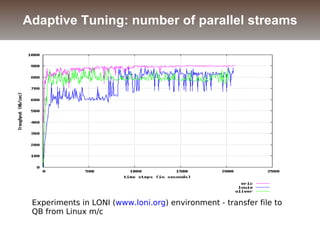
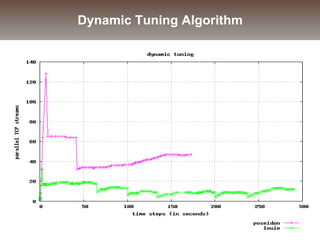
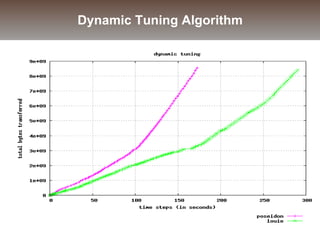
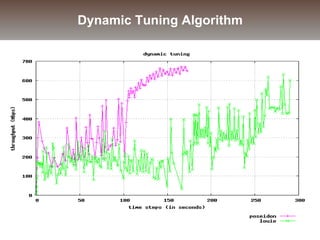
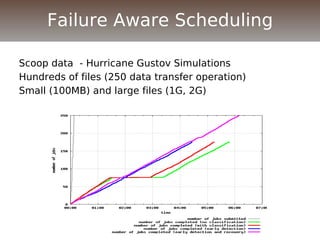
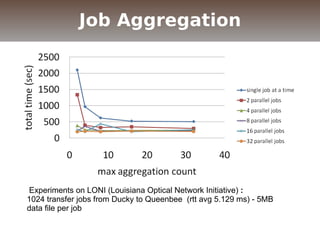
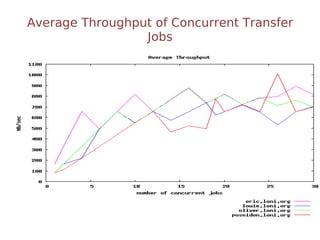
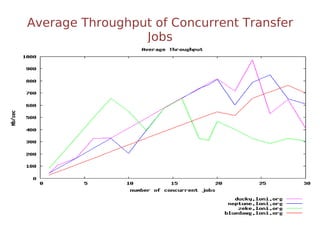
The document discusses the challenges and solutions for data movement between distributed repositories in large-scale collaborative science, focusing on the Petashare environment in Louisiana, which utilizes advanced middleware and tools for efficient data management. Key components include data transfer protocols like Stork for scheduling, adaptive tuning for performance optimization, and failure awareness to enhance reliability during data transfers. It also covers future directions for improving these systems through dynamic scheduling and job aggregation.








![[ dest_url = "gsiftp://eric1.loni.org/scratch/user/";
arguments = -p 4 dbg -vb";
src_url = "file:///home/user/test/";
dap_type = "transfer";
verify_checksum = true;
verify_filesize = true;
set_permission = "755" ;
recursive_copy = true;
network_check = true;
checkpoint_transfer = true;
output = "user.out";
err = "user.err";
log = "userjob.log";
]
Stork Job submission](https://image.slidesharecdn.com/lblcsseminarjun09-2009-jun09-lblcsseminar-130725173715-phpapp02/85/Lblc-sseminar-jun09-2009-jun09-lblcsseminar-12-320.jpg)











































![Resource Aware Scheduling for Hadoop [Final Presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/fyppresentationfinal-120226092754-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





































































