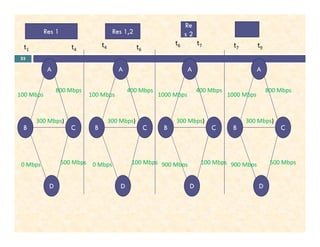
This document discusses scheduling data transfer operations with advance reservation and provisioning. It proposes dividing time into windows where network bandwidth availability is stable. When a data transfer request is received, the scheduler checks all possible time windows to see if the request can fit within bandwidth constraints. If no window is available, it tries shifting existing transfers to earlier windows if they have less "desire" based on number of occupied time slots and order of the window. This allows requests to be scheduled in advance while minimizing disruption to existing transfers.











































































![[IJET V2I2P18] Authors: Roopa G Yeklaspur, Dr.Yerriswamy.T](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i2p18-160609042557-thumbnail.jpg?width=640&height=640&fit=bounds)









![[IJET-V1I5P2] Authors :Hind HazzaAlsharif , Razan Hamza Bawareth](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i5p2-150927102604-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

























































































