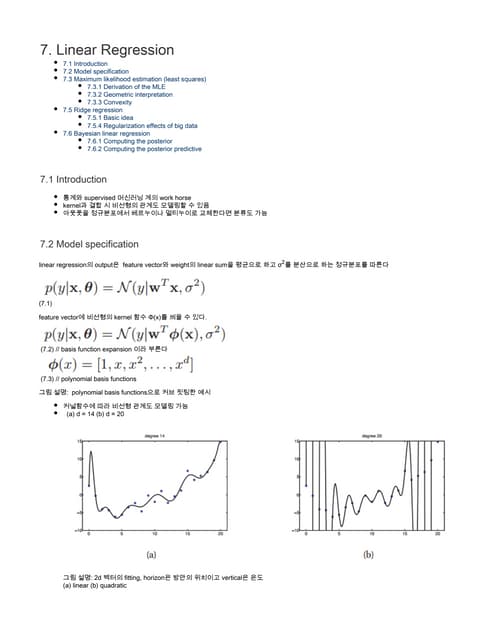
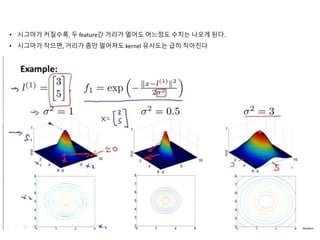
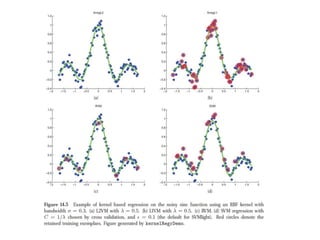
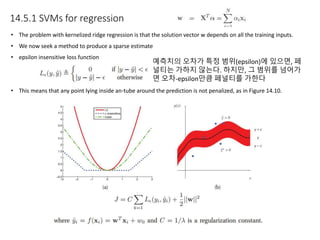
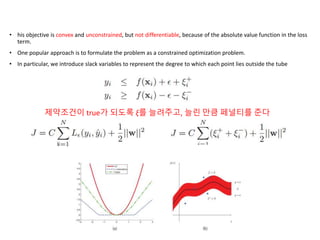
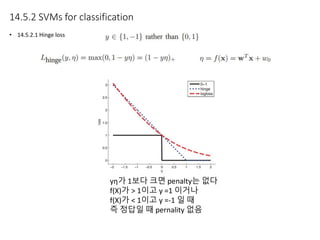
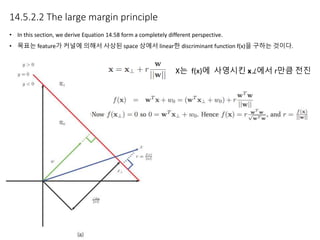
Kernel functions allow measuring the similarity between objects without explicitly representing them as feature vectors. The kernel trick enables applying algorithms designed for explicit feature vectors, like support vector machines (SVMs), to implicit spaces defined by kernels. SVMs find a sparse set of support vectors that define the decision boundary by maximizing margin and minimizing error. They can perform both classification using a hinge loss function and regression using an epsilon-insensitive loss function.









































![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)







![[컴퓨터비전과 인공지능] 6. 역전파 1](https://cdn.slidesharecdn.com/ss_thumbnails/lec6backpropagation-210201173541-thumbnail.jpg?width=640&height=640&fit=bounds)