Download as PDF, PPTX



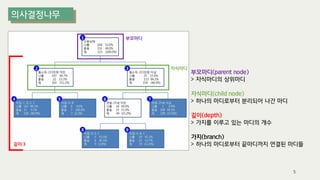
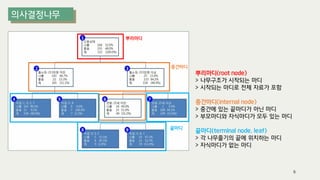
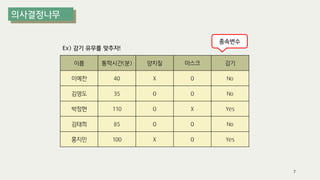
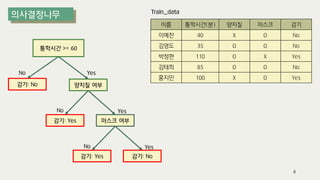
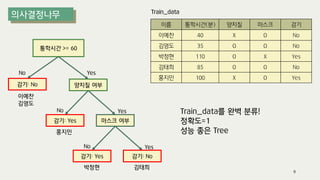
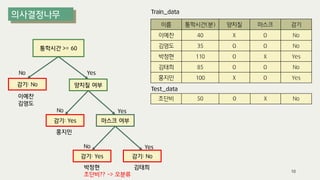
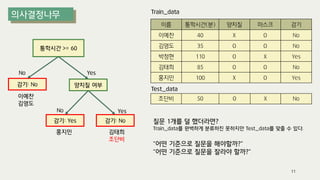
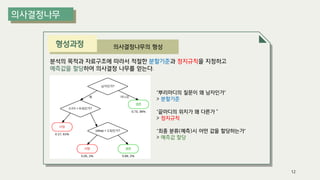






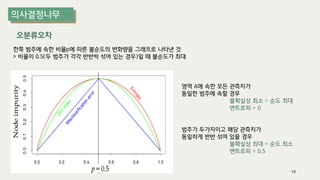
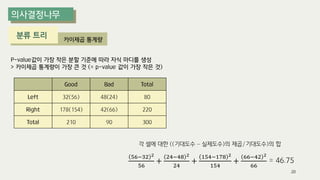
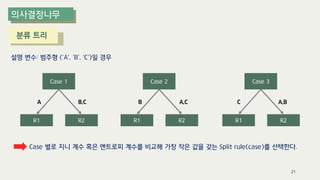
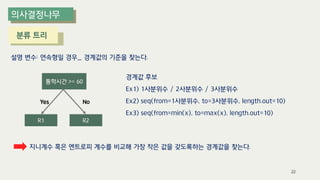

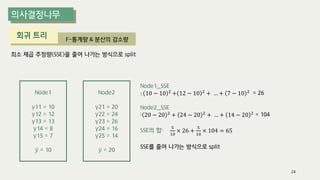
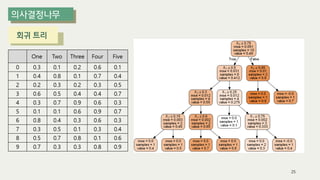
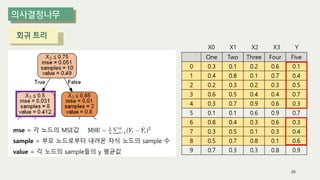

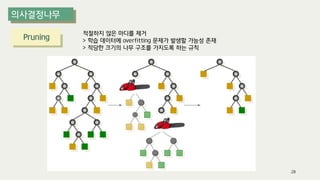
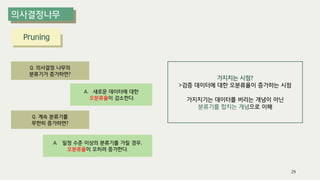

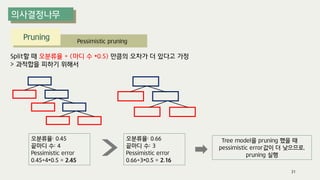
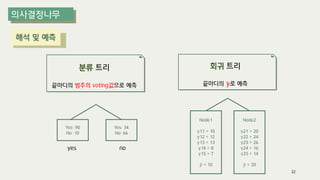
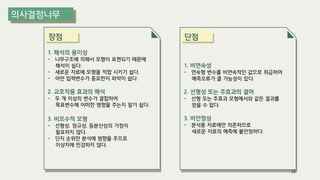


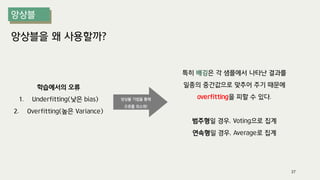
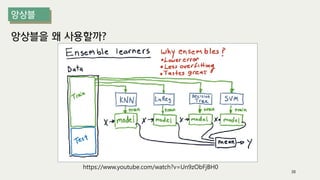

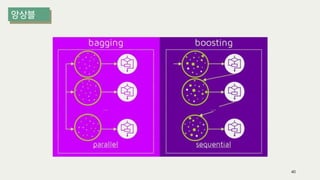

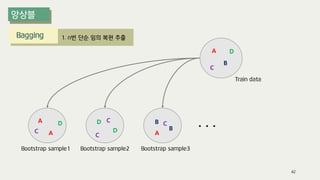
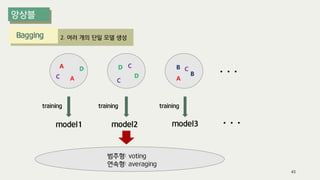
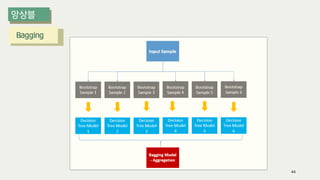
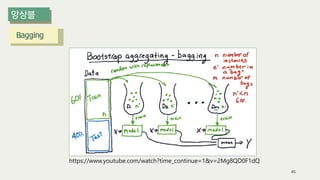


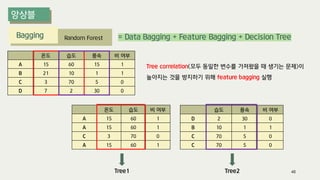
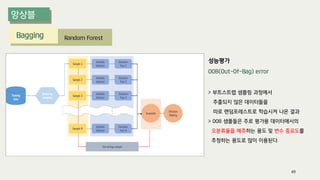

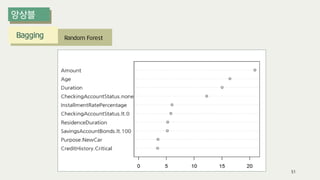

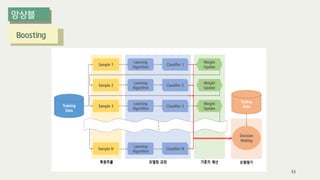
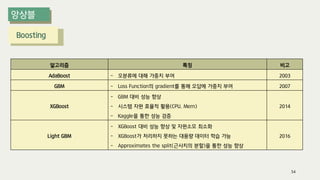
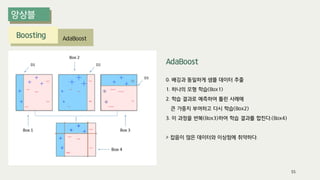
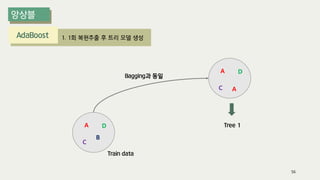
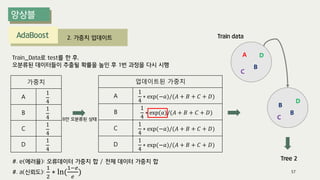
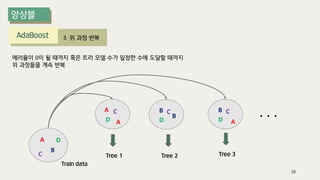







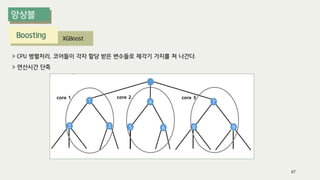
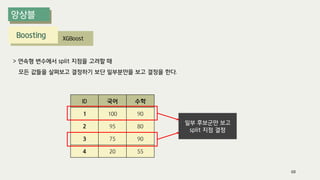
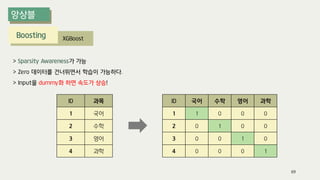

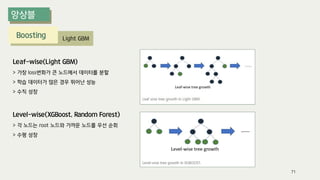




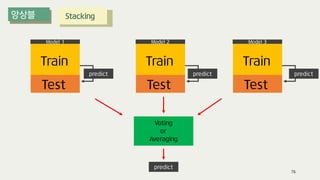
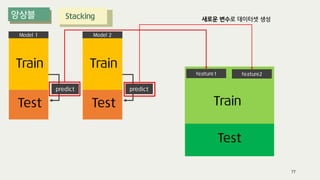



The document outlines the process of decision tree formation and application in classification and prediction tasks. It discusses the methodologies used for segmentation, classification, prediction, and interaction effect identification, along with the structure and components of decision trees such as nodes, branches, and depth. Additionally, it addresses the importance of rules for splitting, stopping, and pruning trees to avoid overfitting, and emphasizes the need for ensemble methods to improve predictive power.

















![Lec 8 03_sept [compatibility mode]](https://cdn.slidesharecdn.com/ss_thumbnails/lec803septcompatibilitymode-130917013815-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![Decision Tree Intro [의사결정나무]](https://cdn.slidesharecdn.com/ss_thumbnails/thetreeslideshare-170922160319-thumbnail.jpg?width=640&height=640&fit=bounds)




![제 14회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [BICS팀] : Boaz Industry Classification Standard](https://cdn.slidesharecdn.com/ss_thumbnails/bics-210806012608-thumbnail.jpg?width=640&height=640&fit=bounds)








































