Collective Intelligence
Chapter9. 커널 기법과 SVM
Kwang Woo Nam
Department of Computer and Information Engineering
Kunsan National University
Textbook: Programming in Collective Intelligence, Toby Segaran
2.
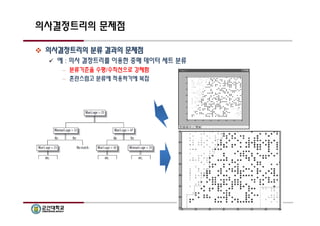
의사결정트리의 문제점
의사결정트리의 분류 결과의 문제점
예 : 의사 결정트리를 이용한 중매 데이터 세트 분류
– 분류기준을 수평/수직선으로 강제함
– 혼란스럽고 분류에 적용하기에 복잡
3.
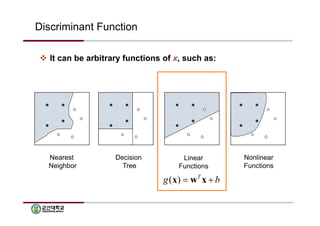
Discriminant Function
It can be arbitrary functions of x, such as:
Nearest
Neighbor
Decision
Tree
Linear
Functions
g(x) wT x b
Nonlinear
Functions
4.
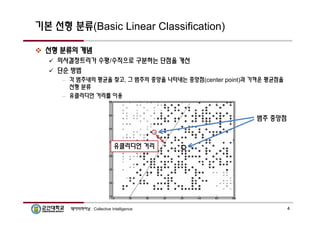
기본 선형 분류(BasicLinear Classification)
선형 분류의 개념
의사결정트리가 수평/수직으로 구분하는 단점을 개선
단순 방법
– 각 범주내의 평균을 찾고, 그 범주의 중앙을 나타내는 중앙점(center point)과 가까운 평균점을
선형 분류
– 유클리디언 거리를 이용
범주 중앙점
유클리디언 거리
데이터마이닝 : Collective Intelligence 4
5.
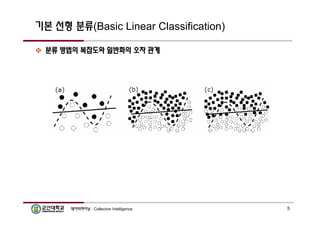
기본 선형 분류(BasicLinear Classification)
분류 방법의 복잡도와 일반화의 오차 관계
데이터마이닝 : Collective Intelligence 5
6.
기본 선형 분류(BasicLinear Classification)
벡터거리를 이용한 선형 분류
예) Vector의 예
– A : (2,2)-(4,6)
– A의 벡터는 <4,6>
(2,2)
|A| 는?
– 벡터의 길이
4
• 직선의 길이 구하는 공식
(6,8)
6
데이터마이닝 : Collective Intelligence 6
7.
기본 선형 분류(BasicLinear Classification)
벡터거리를 이용한 선형 분류
벡터내적(dot product)
– 벡터의 내적 개념
– 벡터의 내적을 구하는 공식
– 벡터의 내적을 Cosine을 이용하여 표현
데이터마이닝 : Collective Intelligence 7
8.
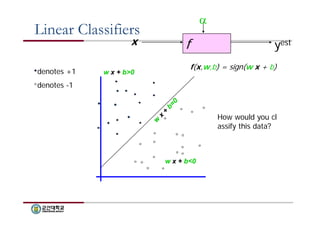
Linear Classifiers
xf
yest
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
How would you cl
assify this data?
w x + b<0
w x + b>0
9.
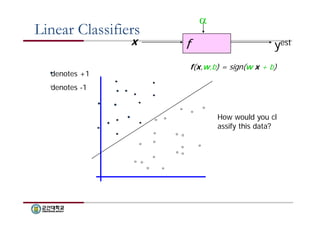
Linear Classifiers
xf
yest
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
How would you cl
assify this data?
10.
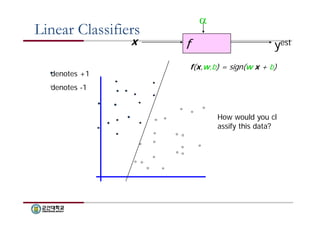
Linear Classifiers
xf
yest
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
How would you cl
assify this data?
11.
Linear Classifiers
xf
yest
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
Any of these woul
d be fine..
..but which is bes
t?
12.
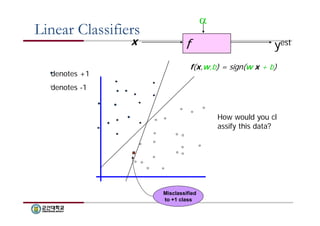
Linear Classifiers
xf
yest
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
How would you cl
assify this data?
Misclassified
to +1 class
13.
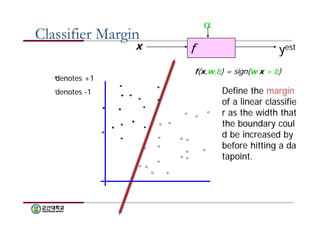
Classifier Margin
xf
yest
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
Define the margin
of a linear classifie
r as the width that
the boundary coul
d be increased by
before hitting a da
tapoint.
14.
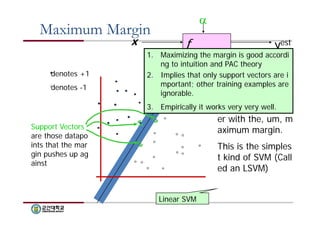
Maximum Margin
xf
yest
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
The maximum mar
gin linear classifier
is the linear classifi
er with the, um, m
aximum margin.
This is the simples
t kind of SVM (Call
ed an LSVM)
Linear SVM
Support Vectors
are those datapo
ints that the mar
gin pushes up ag
ainst
1. Maximizing the margin is good accordi
ng to intuition and PAC theory
2. Implies that only support vectors are i
mportant; other training examples are
ignorable.
3. Empirically it works very very well.
15.
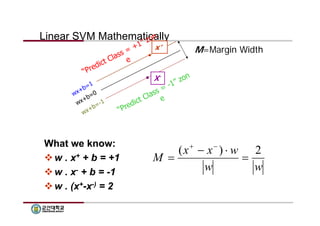
Linear SVM Mathematically
What we know:
w . x+ + b = +1
w . x- + b = -1
w . (x+-x-) = 2
X-x+
M=Margin Width
M (x x ) w 2
w w
16.
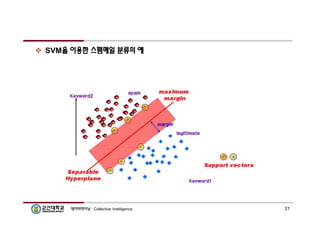
지지벡터머신(Support Vector Machine)
SVM의 개념
두 범주를 갖는 객체들을 분류하는 방법
SVM은 ‘여백을margin 최대화’하여 일반화 능력의 극대화 꾀함
SVM의 역사와 장점
1979년 Vapnik에 의하여 발표된 바 있으나,
– 최근에 와서야 그 성능을 인정받게 됨, Vapnik(1995)과 Burges(1998)
주어진 많은 데이터들을 가능한 멀리 두 개의 집단으로 분리시키는 최적의
초평면(hyperplane)을 찾는 것
– 기존의 통계적 학습 방법들에서 이용되는 경험적 위험도 최소화(empirical risk
minimization)가 아닌 구조적 위험도 최소화(structural risk minimization)방법을 이용하여
일반적으로 에러를 줄이는 방법
– 패턴 인식이나 비선형 운동 분류 등의 다양한 응용분야에 효과적으로 수행
데이터마이닝 : Collective Intelligence 16
지지벡터머신(Support Vector Machine)
기존 선형분류와 SVM의 비교
분류기의 일반화 능력
– ②보다 ③이 여백이 더 크다.
– 즉 ③이 ②보다 일반화 능력이 뛰어나다.
– 신경망은 초기값 ①에서 시작하여 ②를 찾았다면
거기서 멈춘다. 왜?
– SVM은 ③을 찾는다.
중요한 문제
– 여백이라는 개념을 어떻게 공식화할 것인가?
– 여백을 최대로 하는 결정 초평면을 어떻게 찾을 것인가?
출처:패턴인식(오일석)
데이터마이닝 : Collective Intelligence 18
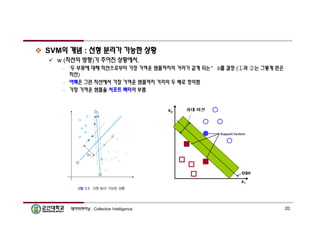
SVM의 개념: 선형 분리가 가능한 상황
w (직선의 방향)가 주어진 상황에서,
– ‘두 부류에 대해 직선으로부터 가장 가까운 샘플까지의 거리가 같게 되는’ b를 결정 (①과 ②는 그렇게 얻은
직선)
– 여백은 그런 직선에서 가장 가까운 샘플까지 거리의 두 배로 정의함
– 가장 가까운 샘플을 서포트 벡터라 부름
데이터마이닝 : Collective Intelligence 20
SVM의 특징
여백이라는 간단한 아이디어로 breakthrough 이룩함
SVM의 특성
– 사용자 설정 매개 변수가 적다.
• 커널 종류와 커널에 따른 매개 변수
• (5.15)에서 목적 1 과 목적 2의 가중치 C
– 최적 커널을 자동 설정하는 방법 없음
• 실험에 의한 휴리스틱한 선택
– 일반화 능력 뛰어남
– 구현이 까다로움
OSS 활용
SVMlight
LIBSVM
데이터마이닝 : Collective Intelligence 22
23.
Dataset with noise
Hard Margin: So far we require
all data points be classified correctly
- No training error
What if the training set is nois
y?
- Solution 1: use very powerful ker
nels
denotes +1
denotes -1
OVERFITTING!
24.
커널 기법(Kernal Methods)의이해
선형 분류의 문제점
선형 분류를 적용하기 어려운 데이터의 존재
아래의 데이터 세트인 경우 두 데이터 세트의 평균점이 모두 중간에 존재
커널 트릭
함수를 이용하여 공간 변환
데이터마이닝 : Collective Intelligence 24
25.
커널 기법(Kernal Methods)의이해
커널기법
벡터 내적 함수를 특정 사항 함수(mapping function)을 사용하여 고차원으로 변환 한후
벡터 내적 결과를 리턴하는 함수로 대치
데이터마이닝 : Collective Intelligence 25






















![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180905033306-thumbnail.jpg?width=640&height=640&fit=bounds)




![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)



![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)






![[공간정보시스템 개론] L04 항공사진의 이해](https://cdn.slidesharecdn.com/ss_thumbnails/l04-170314115042-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L03 지구의형상과좌표체계](https://cdn.slidesharecdn.com/ss_thumbnails/l03-170314115023-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L02 공간정보와 지리정보](https://cdn.slidesharecdn.com/ss_thumbnails/l02-170314114945-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L01 공간정보시스템개요](https://cdn.slidesharecdn.com/ss_thumbnails/l01-170314114926-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L12 공간정보분석](https://cdn.slidesharecdn.com/ss_thumbnails/l12-170314114828-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L11 공간정보의 구축](https://cdn.slidesharecdn.com/ss_thumbnails/l11-170314114751-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L10 수치표고모델](https://cdn.slidesharecdn.com/ss_thumbnails/l10-170314114727-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L09 공간 데이터 모델](https://cdn.slidesharecdn.com/ss_thumbnails/l09-170314114718-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L08 gnss의 개념과 활용](https://cdn.slidesharecdn.com/ss_thumbnails/l08gnss-170314114625-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L07 원격탐사의 개념과 활용](https://cdn.slidesharecdn.com/ss_thumbnails/l07-170314114620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L06 GIS의 이해](https://cdn.slidesharecdn.com/ss_thumbnails/l06gis-170314114559-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L05 우리나라의 수치지도](https://cdn.slidesharecdn.com/ss_thumbnails/l05-170314114527-thumbnail.jpg?width=640&height=640&fit=bounds)


