Download as PDF, PPTX



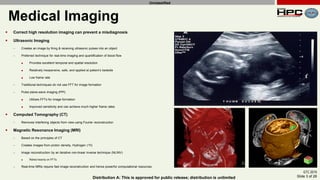
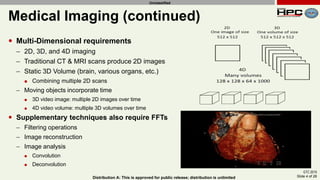
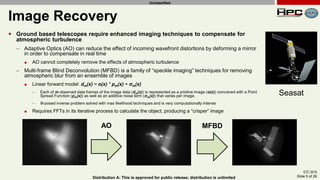




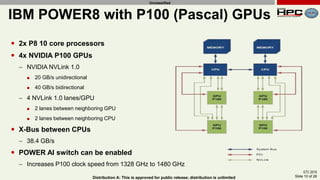
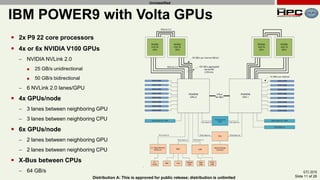
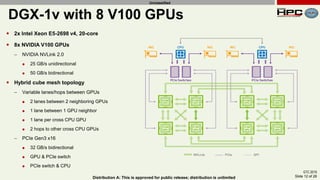
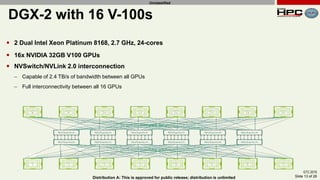

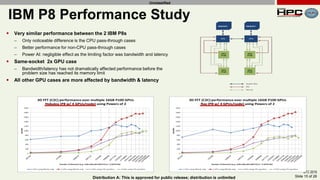

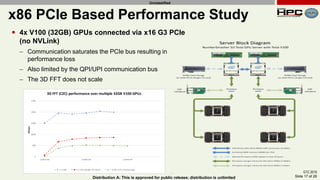
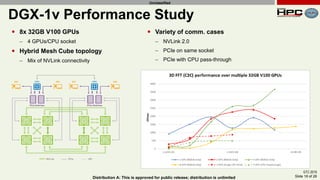
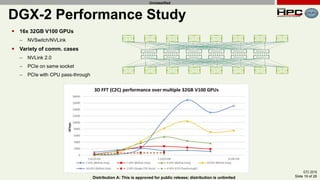
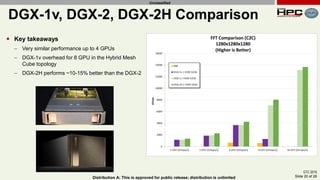
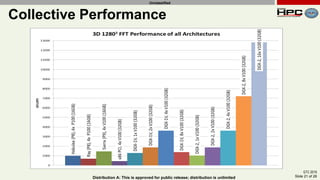
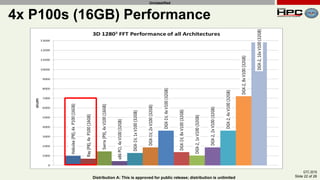
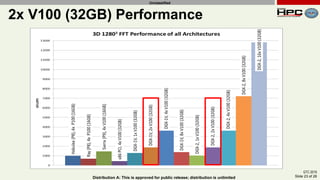
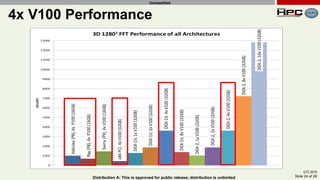
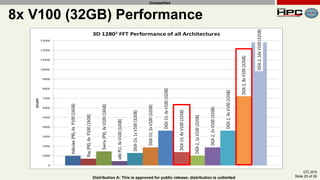
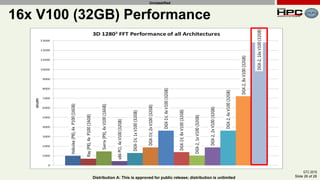



The document discusses the performance of multi-GPU FFT (Fast Fourier Transform) calculations on various hardware configurations, especially in contexts like medical imaging and computational fluid dynamics. It outlines the challenges related to bandwidth and latency in multi-GPU setups and compares performance among different systems, including IBM Power series and NVIDIA GPUs. Conclusions indicate that collective communication operations significantly impact performance, and future work will explore improving FFT implementations across multiple nodes and GPUs.






















































































