Download to read offline



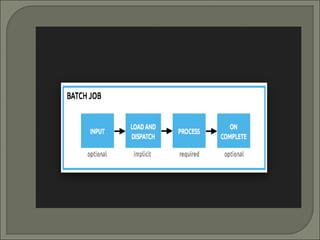






Batch processing in Mule allows splitting messages into individual records, performing actions on each record in parallel, and reporting results. It is useful for integrating or synchronizing large datasets between systems, extracting/transforming/loading data into a target system, and handling large volumes of incoming API data. Mule's batch jobs feature introduced in 2013 simplifies processing massive amounts of data through parallelization, record-based reporting and error handling.




























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








