Download as PDF, PPTX


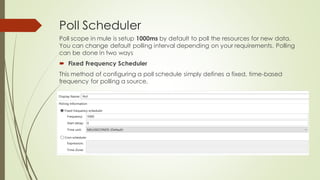



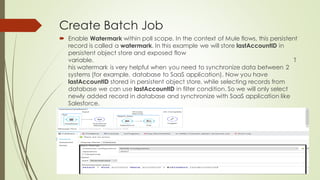
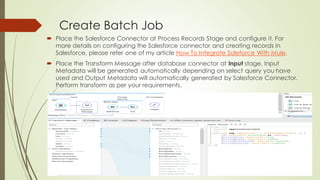
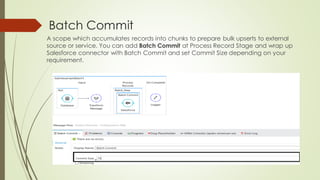


Batch processing in MuleSoft can handle large quantities of incoming data, perform ETL tasks, and enable near real-time integration between systems. It works by splitting large messages into individual records that are processed asynchronously within batch jobs. Poll scopes can retrieve new data from resources on a fixed or cron-based schedule. A batch job contains input, process, and on complete phases where records are loaded, processed asynchronously in batches, and a summary report is generated. The example creates a batch job to synchronize data from a MySQL database to Salesforce using a poll scope, watermarking, transforms, and a batch commit.






























































































