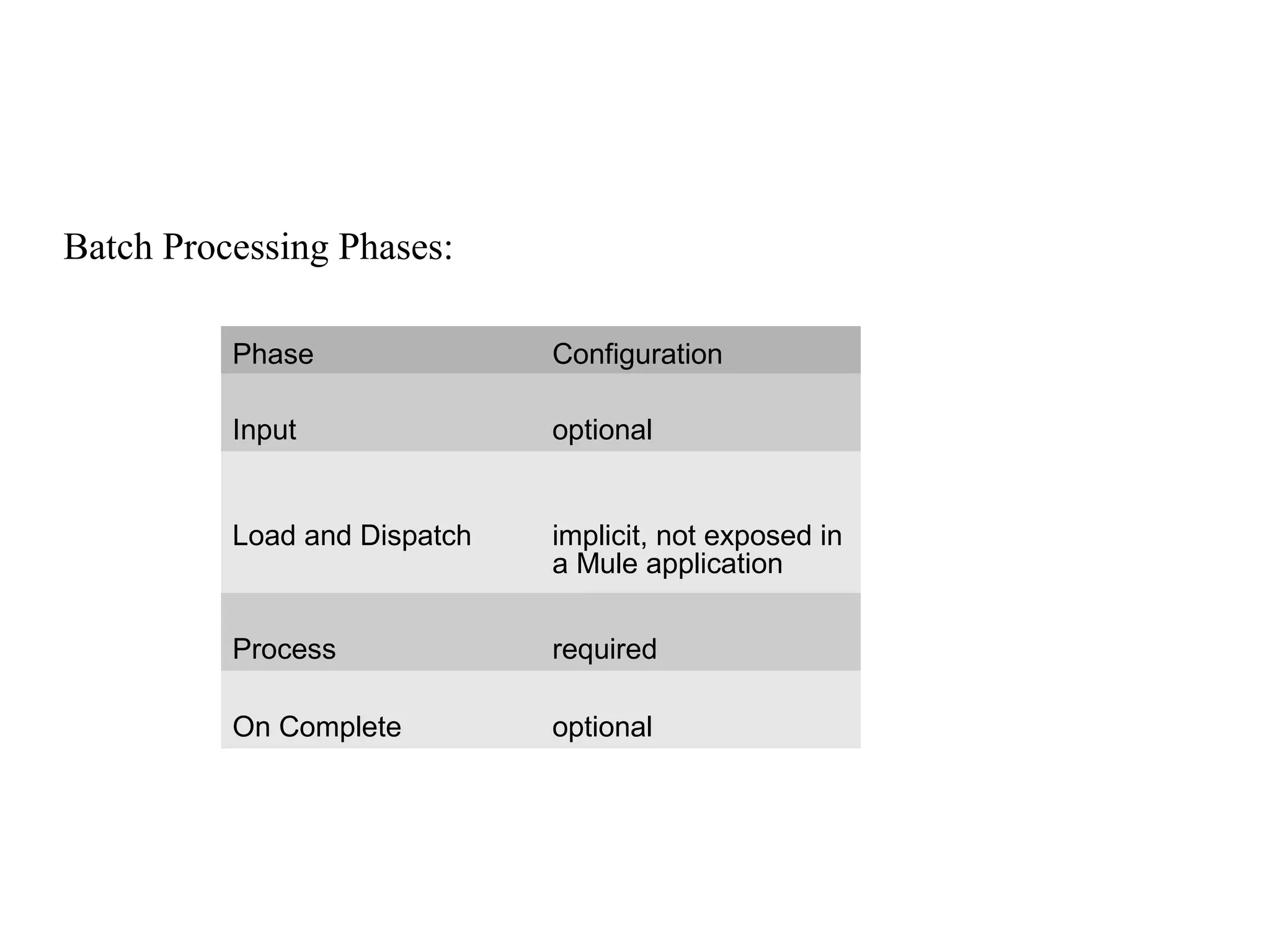
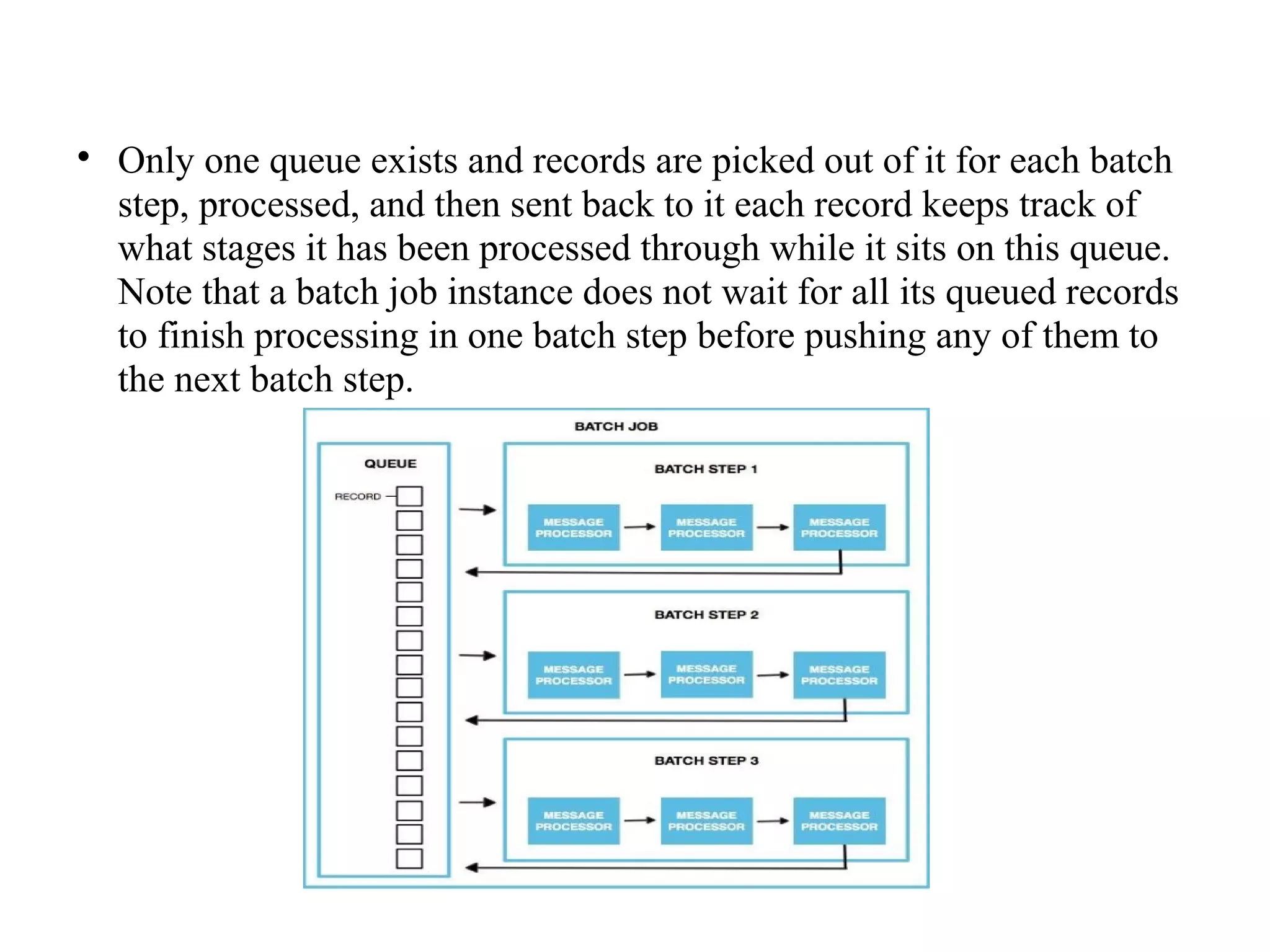
Mule batch processing allows for efficient handling of messages by dividing them into records and processing these records through batch jobs, which consist of input, load and dispatch, process, and on complete phases. This approach is particularly useful for data integration, synchronization, ETL, and managing large data volumes from APIs into legacy systems. Administrators can also configure reports for processed results and handle record-level errors with various strategies.