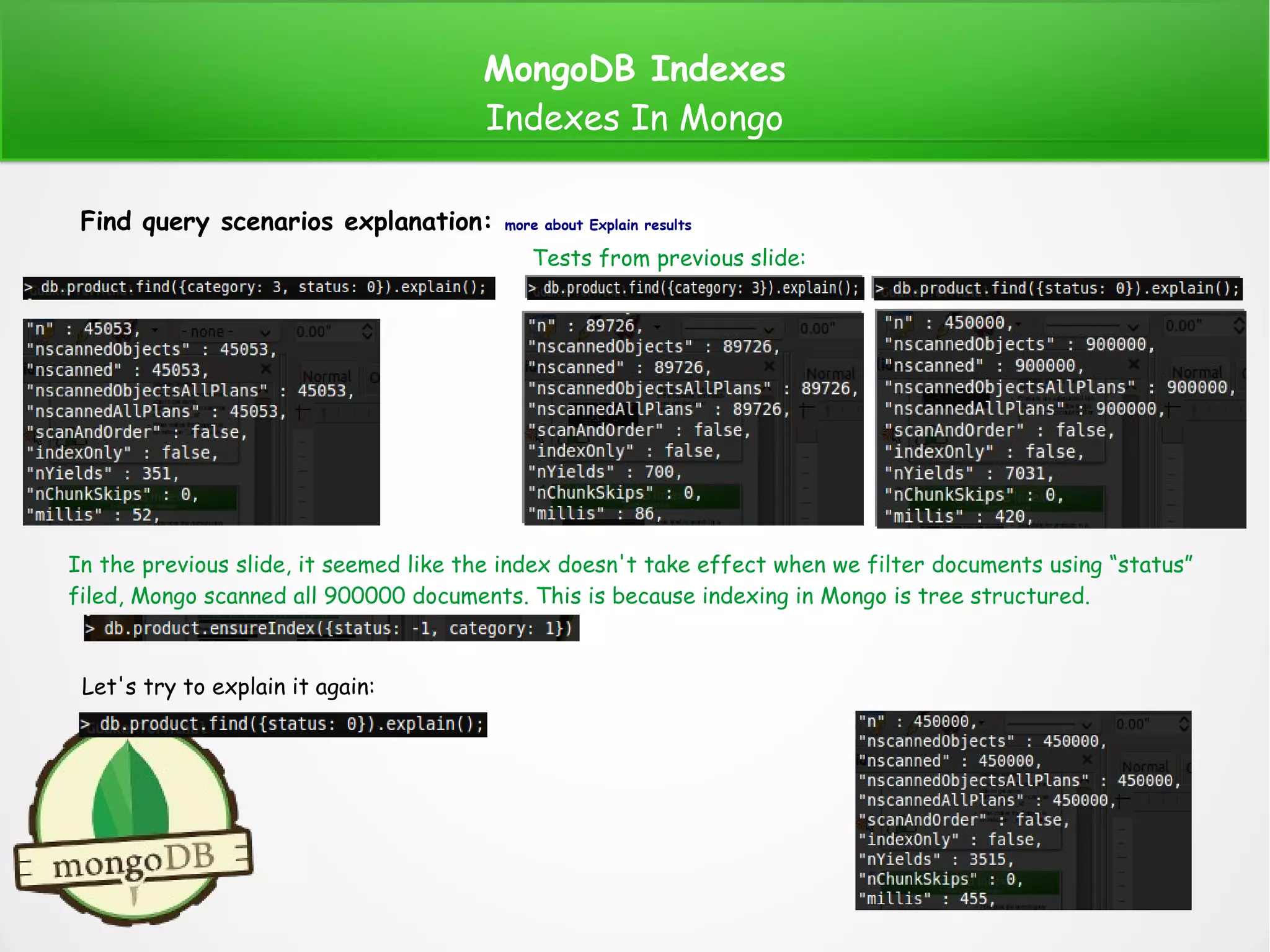
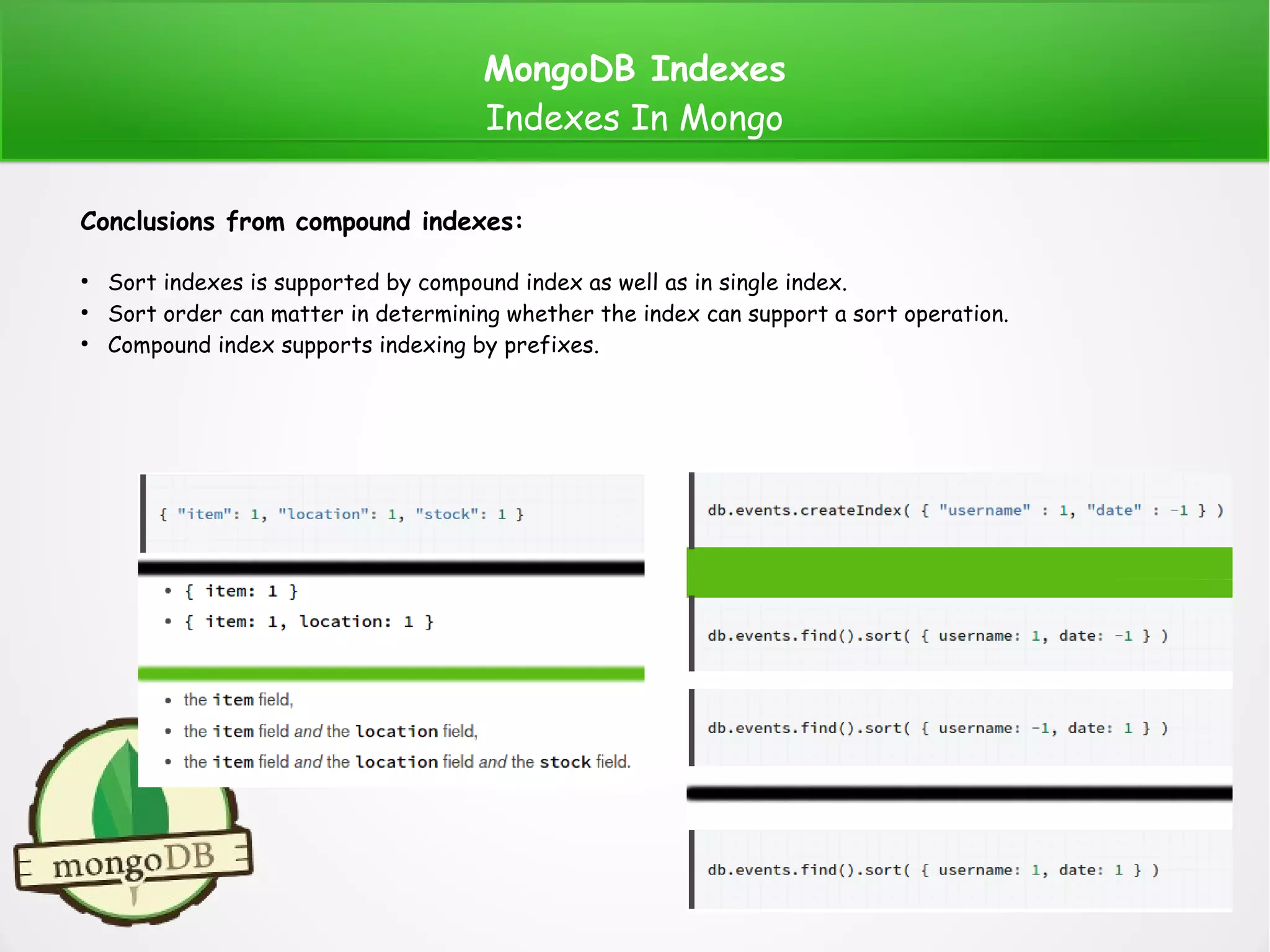
The document provides a comprehensive overview of MongoDB indexes, including types such as default, single, compound, multikey, geospatial, text, and hashed indexes. It discusses their creation, usage, and scenarios in query analysis, highlighting how indexes enhance database performance and efficiency. Additionally, it covers practical examples of index implementation and geospatial data handling within MongoDB.







![MongoDB Indexes
GeoSpatial Index
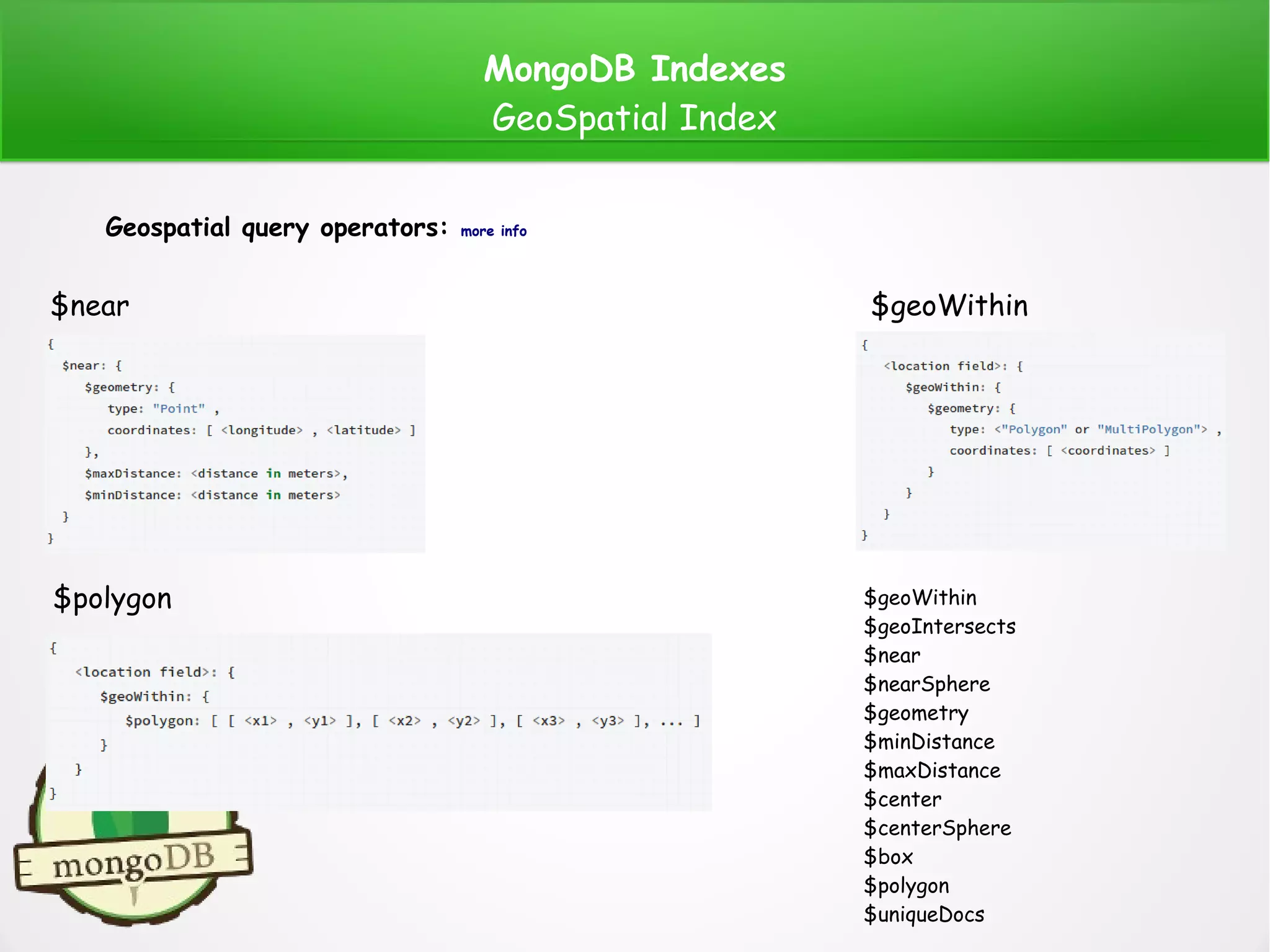
GeoSpatial Index:
MongoDB offers a number of indexes that allows us to handle geospatial data. That geospatial data
is a geographical information that points to a specific location using longitude and latitude or x and
y in the Cartesian coordinates.
There are two surface types:
●
Flat (1): To calculate distances on a Euclidean plane. Use “2d” index. Supports data stored as
two-dimensional plane, legacy coordinate pairs [x, y].
●
Spherical (2): To calculate geometry over an Earth-like sphere. Use “2dsphere” index. Supports
data stored as GeoJSON object and as legacy coordinate pairs
(1)(2)](https://image.slidesharecdn.com/mongoindexes-150807153757-lva1-app6892/75/Mongo-indexes-13-2048.jpg)
![MongoDB Indexes
GeoSpatial Index
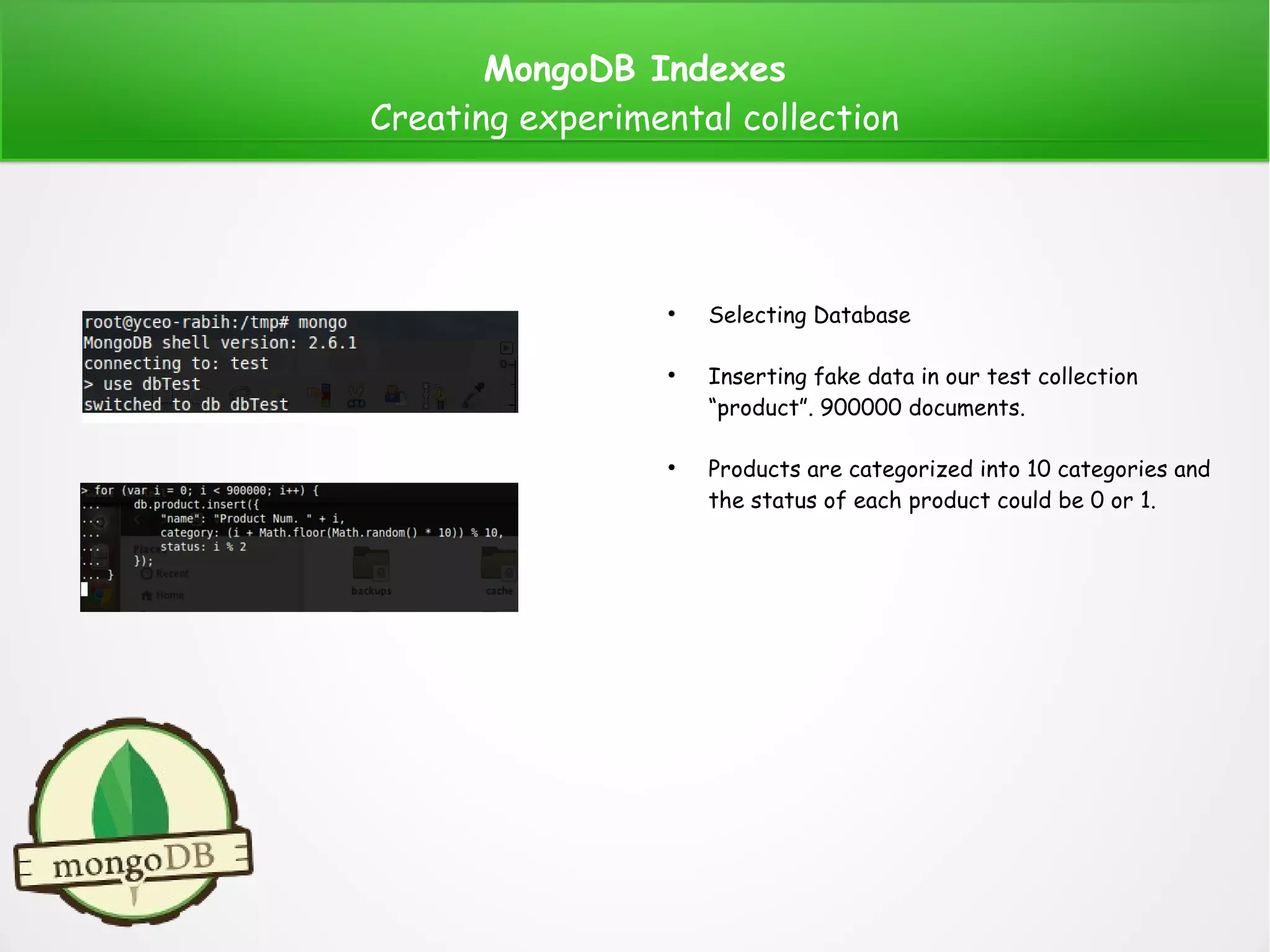
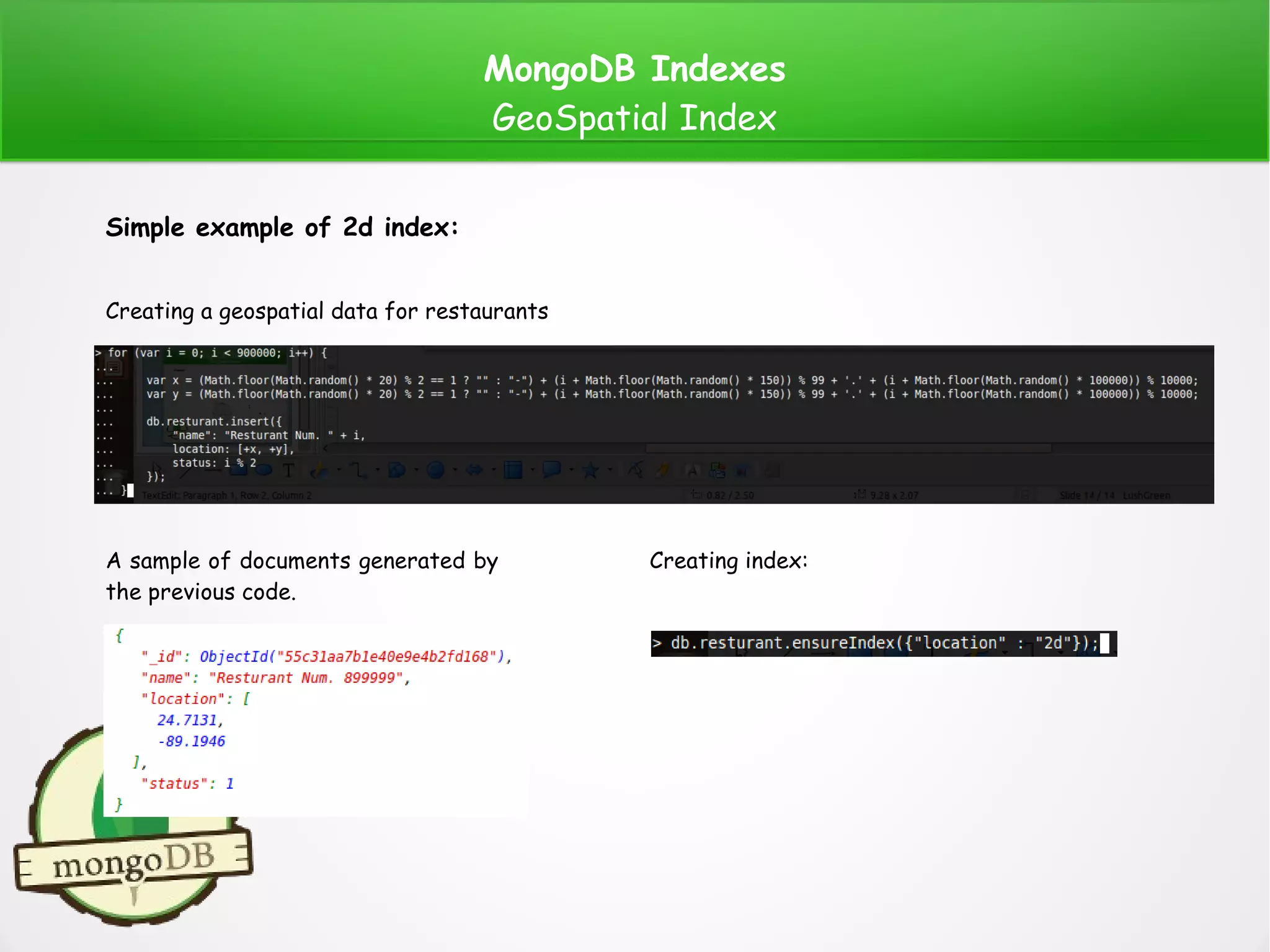
Simple example of 2dsphere index:
Creating a geospatial data for restaurants
A sample of documents generated by
the previous code.
Creating index:
Note: 2dshpere supports data stored as GeoJSON Objects.
For more info about GeoJSON : geojson.org , The following website is a tool to show how GeoJson is structured : geojson.io
for (var i = 0; i < 1000; i++) {
var x = (Math.floor(Math.random() * 20) % 2 == 1 ? "" : "-") + (i + Math.floor(Math.random() * 150)) % 99 + '.' + (i + Math.floor(Math.random() * 100000)) % 1000;
var y = (Math.floor(Math.random() * 20) % 2 == 1 ? "" : "-") + (i + Math.floor(Math.random() * 150)) % 99 + '.' + (i + Math.floor(Math.random() * 100000)) % 1000;
db.places.insert({
"loc": {
type: "Point",
coordinates: [+x, +y]
},
name: "Resturant Num. " + i,
status: i % 2
});
}](https://image.slidesharecdn.com/mongoindexes-150807153757-lva1-app6892/75/Mongo-indexes-15-2048.jpg)