Downloaded 25 times




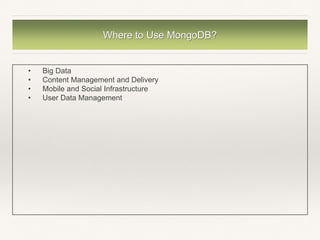
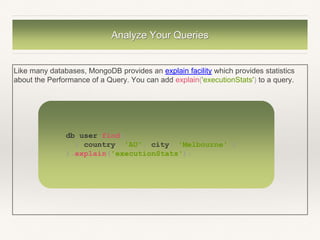


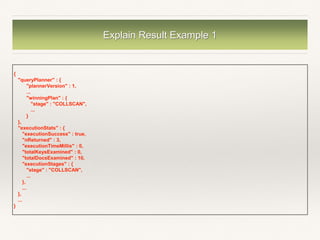
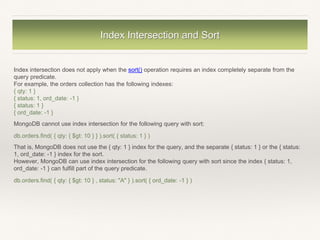
![Explain Result Example 2
{
"queryPlanner" : {
"plannerVersion" : 1,
...
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"quantity" : 1
},
...
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 3,
"executionTimeMillis" : 0,
"totalKeysExamined" : 3,
"totalDocsExamined" : 3,
"executionStages" : {
...
},
...
},
...
}](https://image.slidesharecdn.com/mongodb-180219195435/85/Query-Optimization-in-MongoDB-9-320.jpg)


![Index Intersection and Compound Indexes
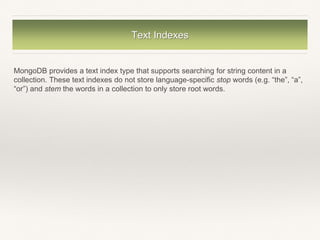
Index intersection does not eliminate the need for creating compound indexes. However, because both the list
order (i.e. the order in which the keys are listed in the index) and the sort order (i.e. ascending or descending),
matter in compound indexes, a compound index may not support a query condition that does not include the
index prefix keys or that specifies a different sort order.
For example, if a collection orders has the following compound index, with the status field listed before the
ord_date field:
{ status: 1, ord_date: -1 }
The compound index can support the following queries:
db.orders.find( { status: { $in: ["A", "P" ] } } )
db.orders.find({ord_date: { $gt: new Date("2014-02-01") }, status: {$in:[ "P", "A" ] }})
But not the following two queries:
db.orders.find( { ord_date: { $gt: new Date("2014-02-01") } } )
db.orders.find( { } ).sort( { ord_date: 1 } )
However, if the collection has two separate indexes:
{ status: 1 }
{ ord_date: -1 }
The two indexes can, either individually or through index intersection, support all four aforementioned queries.
The choice between creating compound indexes that support your queries or relying on index intersection
depends on the specifics of your system.](https://image.slidesharecdn.com/mongodb-180219195435/85/Query-Optimization-in-MongoDB-21-320.jpg)






MongoDB is a document-oriented database that provides high performance, high availability, and scalability. It uses collections and documents where collections do not enforce a schema and documents can have different fields. The document explains various MongoDB concepts like databases, collections, documents and their relationships. It also discusses advantages of MongoDB over relational databases and where MongoDB can be used. The document then talks about analyzing queries using explain, adding appropriate indexes like single field, compound, multikey etc and their properties. It finally covers index intersection and prefix intersection.























![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




