Downloaded 286 times























![• Indexes on geospatial fields
– Using GeoJSON objects
– Geometries on spheres
Geospatial Index - 2dSphere
//GeoJSON object structure for indexing
{
name: ’MongoDB Palo Alto’,
location: { type : “Point”,
coordinates: [ 37.449157 , -122.158574 ] }
}
// Index on GeoJSON objects
>db.articles.ensureIndex( { location: “2dsphere” } )
Supported GeoJSON
objects:
Point
LineString
Polygon
MultiPoint
MultiLineString
MultiPolygon
GeometryCollection](https://image.slidesharecdn.com/fastquerying-indexingforperformance4-150324144349-conversion-gate01/75/Fast-querying-indexing-for-performance-4-27-2048.jpg)
![//Javascript function to get geolocation.
navigator.geolocation.getCurrentPosition();
//You will need to translate into GeoJSON
Extended Articles document
• Store the location
article was posted
from….
• Geo location from
browser
Articles collections
>db.articles.insert({
'text': 'Article
content…’,
'date' : ISODate(...),
'title' : ’Indexing
MongoDB’,
'author' : ’Muthu C’,
'tags' : ['mongodb',
'database',
'geospatial’],
‘location’ : {
‘type’ : ‘Point’,
‘coordinates’ :
[37.449, -122.158]
}
});](https://image.slidesharecdn.com/fastquerying-indexingforperformance4-150324144349-conversion-gate01/75/Fast-querying-indexing-for-performance-4-28-2048.jpg)
![– Query for locations ’near’ a particular coordinate
Geo Spatial Example
>db.articles.find( {
location: { $near :
{ $geometry :
{ type : "Point”, coordinates : [37.449, -122.158] } },
$maxDistance : 5000
}
} )](https://image.slidesharecdn.com/fastquerying-indexingforperformance4-150324144349-conversion-gate01/75/Fast-querying-indexing-for-performance-4-29-2048.jpg)































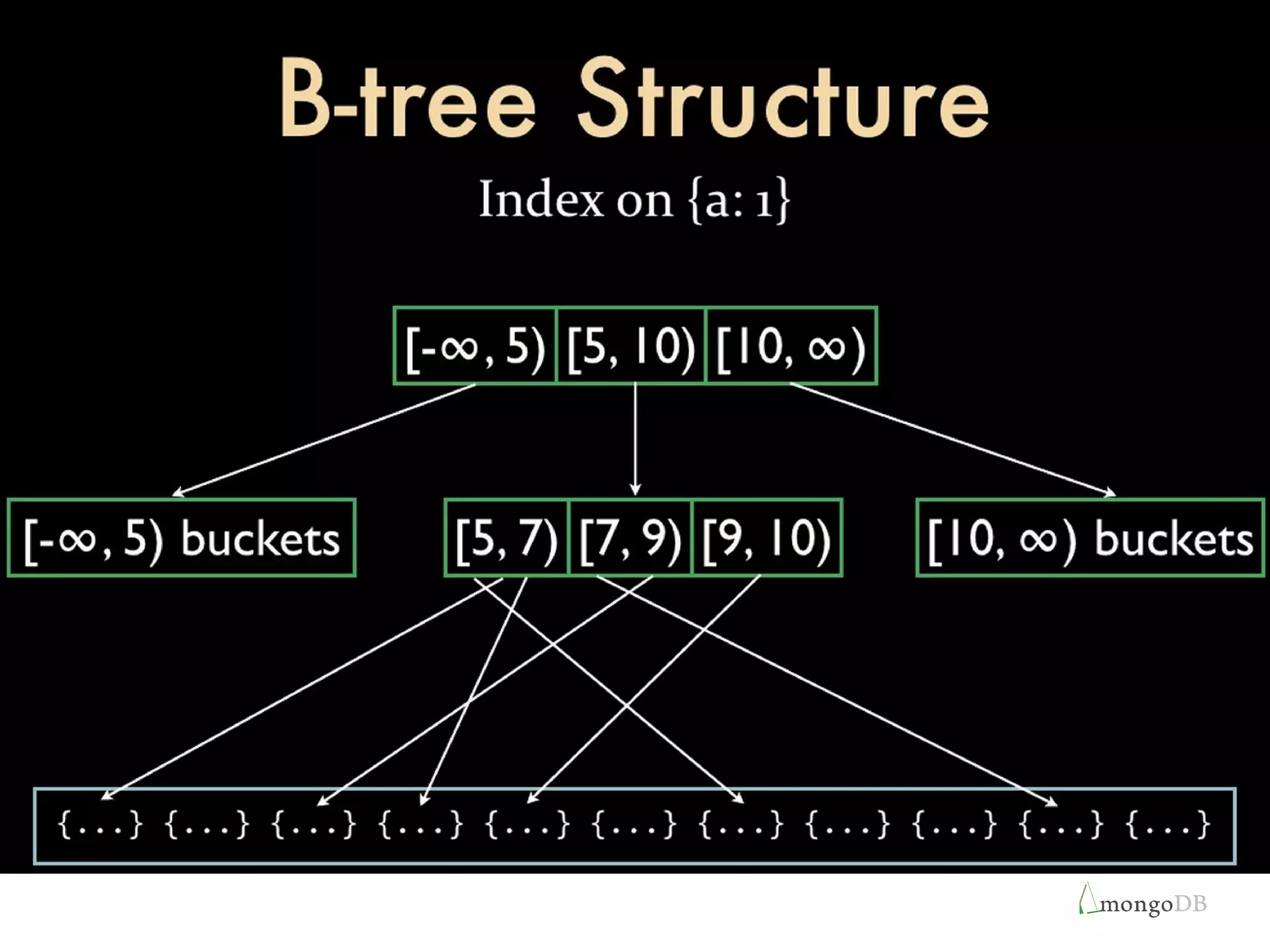
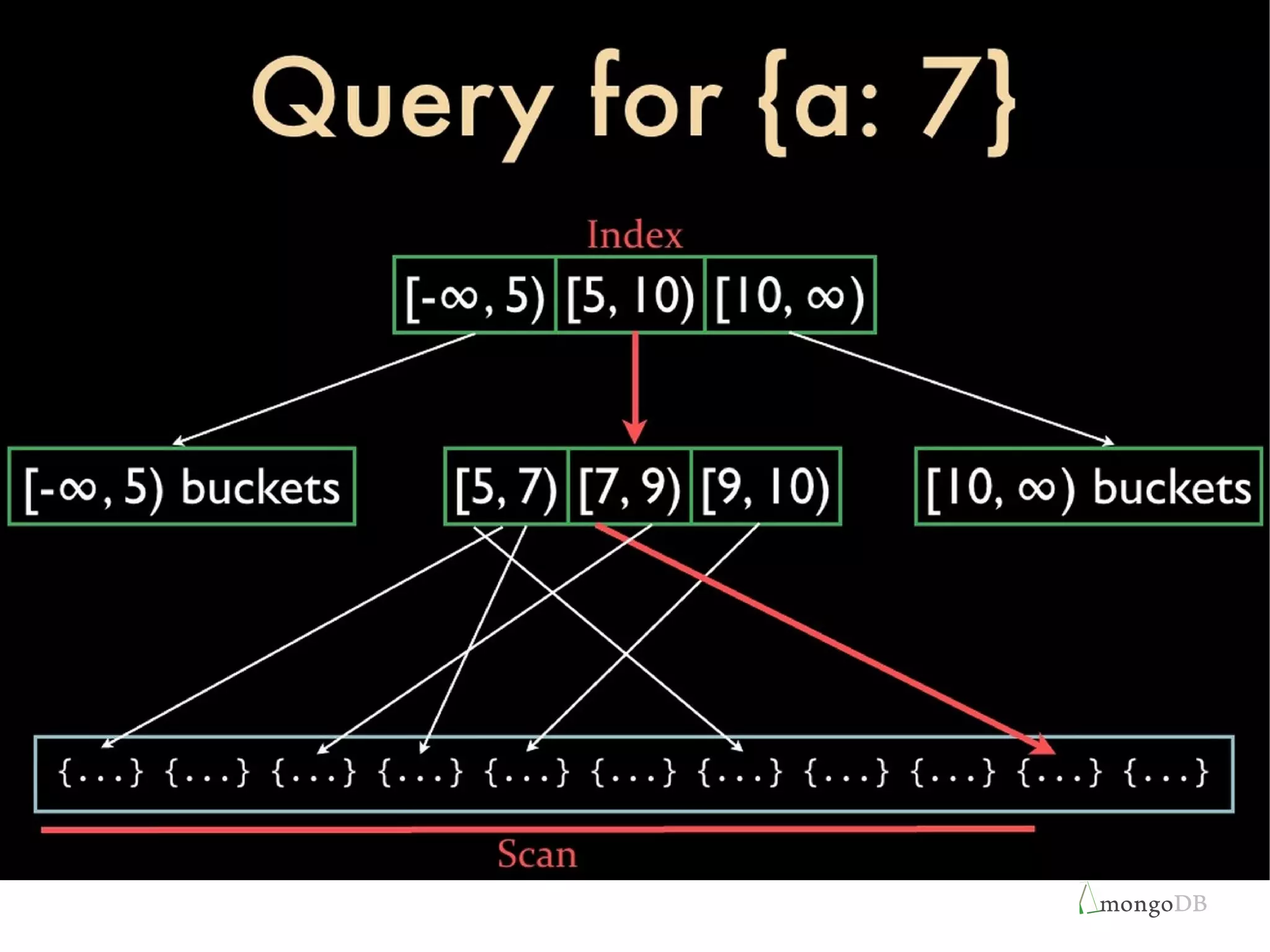
The document discusses strategies for optimizing performance in MongoDB through effective indexing techniques, including the creation and management of various types of indexes. It highlights examples of fast querying, the importance of index monitoring, and the latest features introduced in MongoDB 3.0, such as index compression and placement on separate storage devices. Additionally, it covers practical tips for using indexes and the query optimizer to enhance query performance.
Introduction to fast querying and indexing strategies to optimize performance in MongoDB.
Overview of MongoDB's architecture enabling indexing for performance, with examples of indexes and their impact on query speed.
Discussion of types of indexes including compound indexes, and properties of indexing within MongoDB.
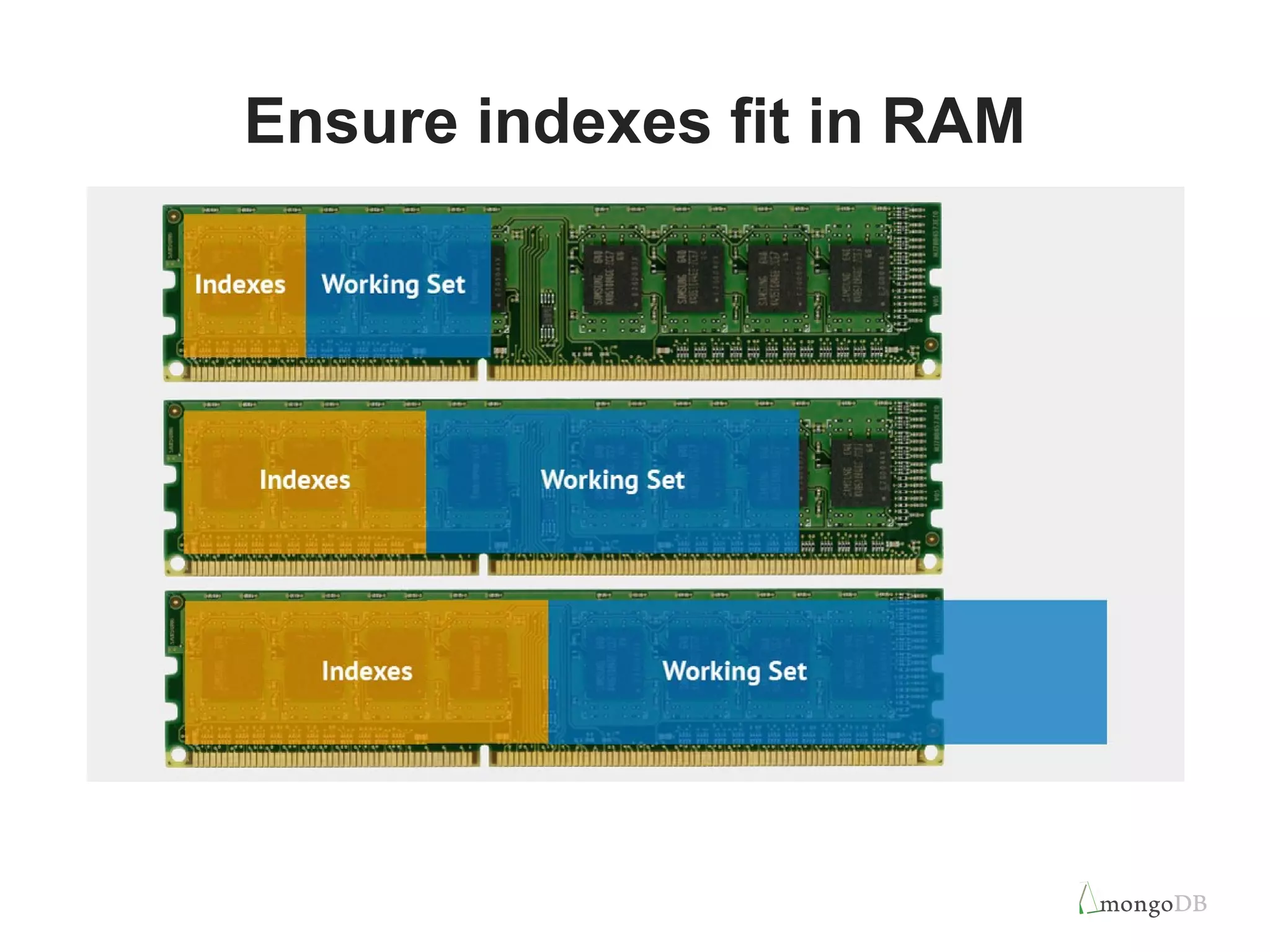
Best practices for index management such as creating and removing indexes efficiently to enhance performance and response times.
Exploration of index intersection to optimize queries by using a compound index vs. multiple single-field indexes.
Methods for monitoring query performance, analyzing indexes, and new features introduced in MongoDB 3.0 for better index management.
Promotional information about MongoDB World events, including registration details and discount codes.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)














![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















