Download as PDF, PPTX









![Below given example shows
the document structure of a blog site which is simply a comma separated key value pair.
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}
_id is a 12 bytes hexadecimal number which assures the uniqueness of every document. You can
provide _id while inserting the document. If you didn't provide then MongoDB provide a unique id
for every document. These 12 bytes first 4 bytes for the current timestamp, next 3 bytes for
machine id, next 2 bytes for process id of mongodb server and remaining 3 bytes are simple
incremental value.
Sample document](https://image.slidesharecdn.com/3f630fc8-a983-442d-b211-d4f43128071c-151224182427/85/Mongodb-Introduction-9-320.jpg)

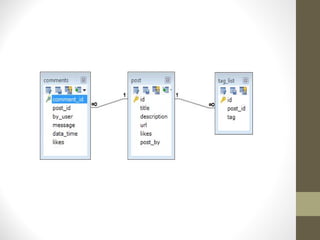
![So while showing the data, in RDBMS you need to join three tables and in mongodb
data will be shown from one collection only.
While in MongoDB schema design will have one collection post and has the following structure:
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [
TAG1,
TAG2,
TAG3
],
likes: TOTAL_LIKES,
comments: [
{
user: 'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user: 'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}](https://image.slidesharecdn.com/3f630fc8-a983-442d-b211-d4f43128071c-151224182427/85/Mongodb-Introduction-12-320.jpg)




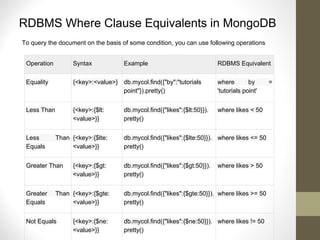


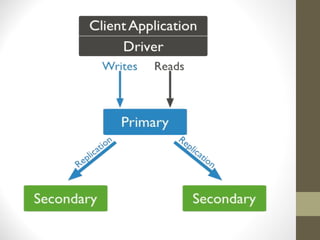


![● Add instance(s) to a cluster
● mongo myhost:27017
config = {_id: 'cluster1', members: [
{_id: 0, host: 'myhost1:27017'},
{_id: 1, host: 'myhost2:27018'},
{_id: 2, host: 'myhost3:27019'}]
}
rs.initiate(config);
cluster1:PRIMARY> rs.status()
ref : http://www.jonathanhui.com/mongodb-replication-replica-set](https://image.slidesharecdn.com/3f630fc8-a983-442d-b211-d4f43128071c-151224182427/85/Mongodb-Introduction-25-320.jpg)

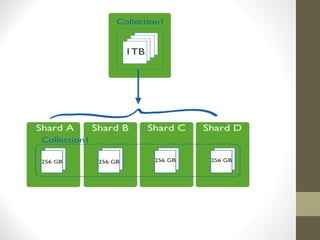
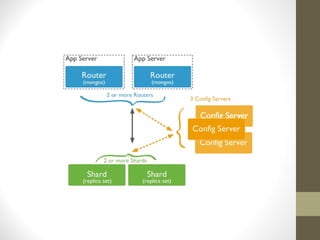

![GridFS
GridFS is a specification for storing and retrieving files that exceed the BSON-document size
limit of 16MB.
Instead of storing a file in a single document, GridFS divides a file into parts, or chunks, [1] and
stores each of those chunks as a separate document. By default GridFS limits chunk size to
255k. GridFS uses two collections to store files. One collection stores the file chunks, and the
other stores file metadata.](https://image.slidesharecdn.com/3f630fc8-a983-442d-b211-d4f43128071c-151224182427/85/Mongodb-Introduction-31-320.jpg)



MongoDB is a document-oriented, cross-platform NoSQL database known for high performance, availability, and scalability, leveraging collections and documents without rigid schemas. It features document-oriented storage with dynamic schemas, supporting full index capabilities, replication for high availability, and easy sharding for managing large datasets. Additionally, MongoDB includes functionalities such as GridFS for handling files larger than its document size limit and provides methods for creating collections and indices efficiently.























































































