Mongo db a deep dive of mongodb indexes
•
1 like•492 views

MongoDB defines indexes at the collection level and supports indexes on any field or sub-field of the documents in a MongoDB collection.

Recommended
Recommended
More Related Content
What's hot
What's hot (18)
Viewers also liked
Viewers also liked (19)
Similar to Mongo db a deep dive of mongodb indexes
Similar to Mongo db a deep dive of mongodb indexes (20)
Recently uploaded
Recently uploaded (20)
Mongo db a deep dive of mongodb indexes
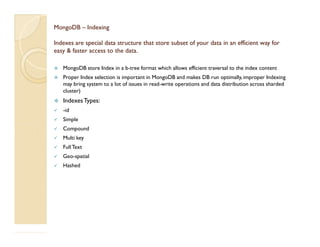
- 1. MongoDBMongoDB –– IndexingIndexing IndexesIndexes are special data structure that store subset of your data in an efficient way forare special data structure that store subset of your data in an efficient way for easy & faster access to theeasy & faster access to the data.data. MongoDB store Index in a b-tree format which allows efficient traversal to the index content Proper Index selection is important in MongoDB and makes DB run optimally, improper Indexing may bring system to a lot of issues in read-write operations and data distribution across sharded cluster) IndexesTypes: -id Simple Compound Multi key FullText Geo-spatial Hashed
- 2. Index continued..Index continued.. The –id index : It is automatically created, immutable and can’t be removed. This is same as primary key in RDBMS. Default value is a 12 byte Object ID 4-Byte timestamp, 3-byte machine id, 2-byte process id,3-byte counter Simple Index: A simple Index is an Index on a single key Compound Index:A compound Index is created over two or more fields in a document Multi-key Index:A multi-key Index is an Index created on a field that contains an array Full-text search Index:This is an Index over a text based field, similar to how google indexes web pages. e.g Find all tweets that mention auto insurance within 30 days. Search Big Data in a blogpost or all the tweets in last 30 days. Geo-spatial Index: This Index is to support efficient queries of geospatial coordinate data .It is Geo-spatial Index: This Index is to support efficient queries of geospatial coordinate data .It is used when you need to query location based spatial data.This Index is really a great feature because location based data is one of the valuable data being collected today for targeted location based customer, location based product analysis . e.g Find all customers that live within 50 miles of NY. Hashed Index: Used mainly in Hash based sharding, and allows for more randomized data distribution across shards Create Index syntax: db.employee.ensureIndex({“email”:1},{“unique”:true}) db.employee.ensureIndex({“age”;1}, {“sparse”: true}) db.employee.find({age: {$gte :25}})
- 3. Index Continue..Index Continue.. Index Properties: TTL Index-TTL indexes are special indexes that MongoDB can use to automatically remove documents from a collection after a certain amount of time Sparse Index-The sparse property of an index ensures that the index only contain entries for documents that have the indexed field.The index skips documents that do not have the indexed field. Unique Index- To enable the uniqueness of the field. Text Search Index: MongoDB provides text indexes to support text search queries on text content.To perform text search queries, you must have a text index on your collection.A collection can only have one text search index, but that index can cover multiple fields. Creating text search Index over the ”title” and “content” fields : db.blogpost.ensureIndex( { title: "text", content: "text" } )db.blogpost.ensureIndex( { title: "text", content: "text" } ) Use the $text query operator to perform text searches on a collection with a text index. $text perform a logical OR of all such on the intended search string. For example, we can use the following query to find term MongoDB and BigData in the blogpost. db.blogpost.find( { $text: { $search:“MongoDB" } } ) db.blogpost.find({$text:{$search:”BigData”}}) DeletingText Index: To delete an existing text index, first find the name of index using the following query, to get the name of the index >db.blogpost.getIndexes() Now you can drop the text Index: >db.blogpost.dropIndex(“title_text_content_text")
- 4. TTextext indexesindexes to support text searchto support text search analyticsanalytics--By exampleBy example
- 5. That’s it Thank you ! Follow me onTwitter: @rajesh14k