






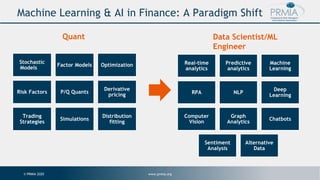









































































The document discusses model risk management considerations for machine learning models. It begins with an overview of machine learning and artificial intelligence applications in finance. It then covers key elements of model risk management for machine learning such as model governance structure, model lifecycle management, tracking, metadata management, scaling, reproducibility, interpretability, and testing. The presentation concludes with a discussion on quantifying model risk.























































































