Downloaded 43 times




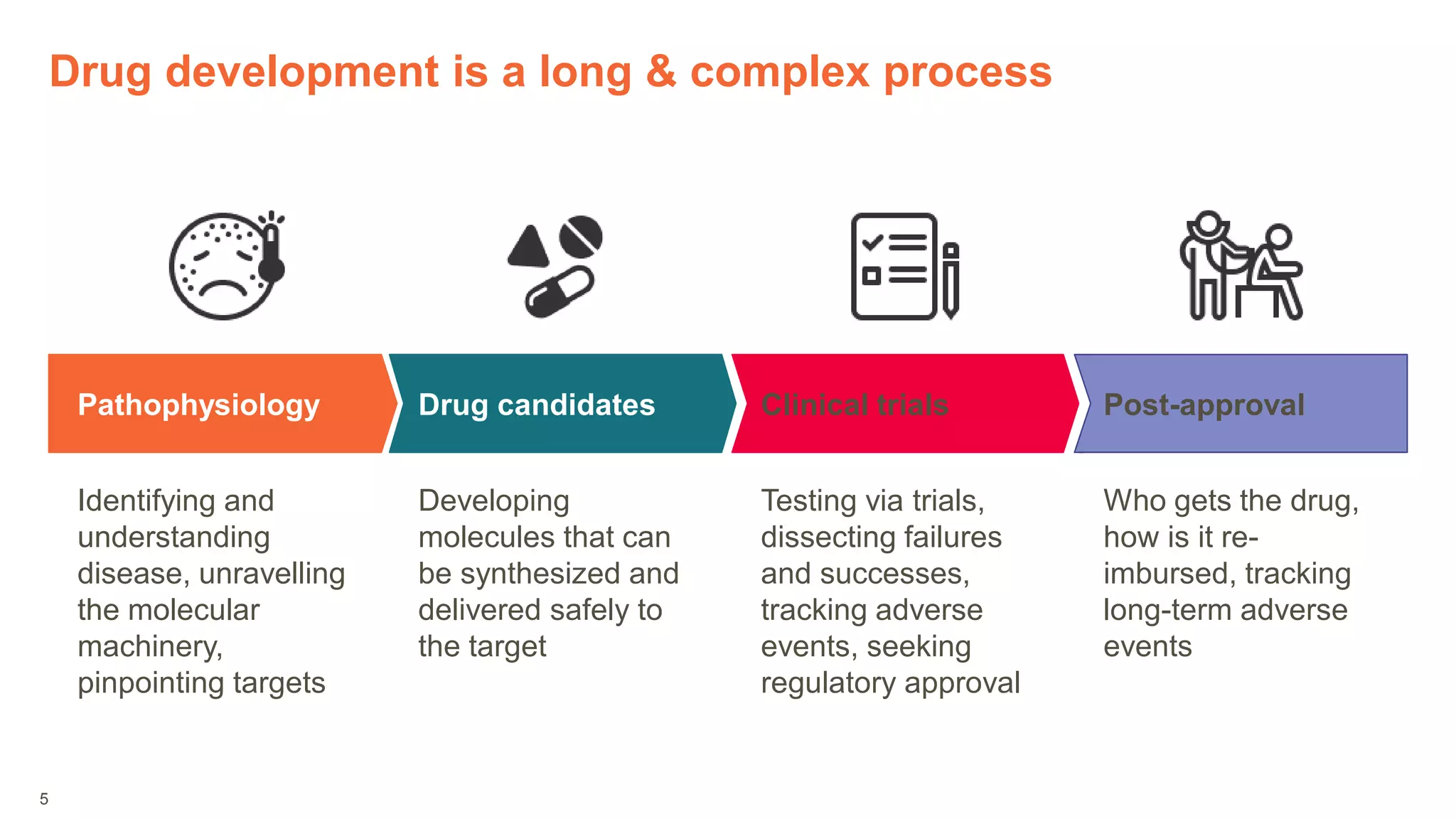
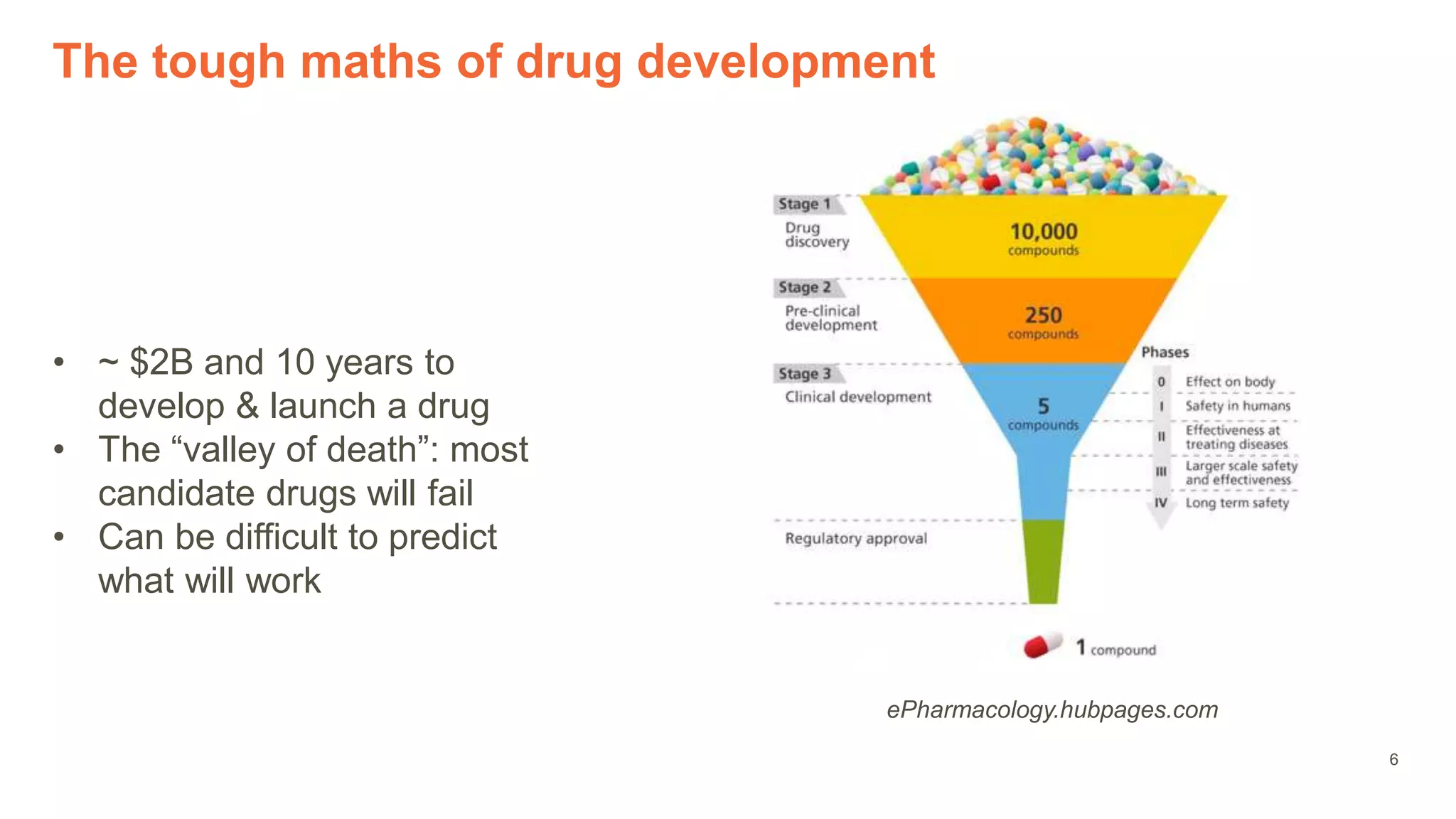





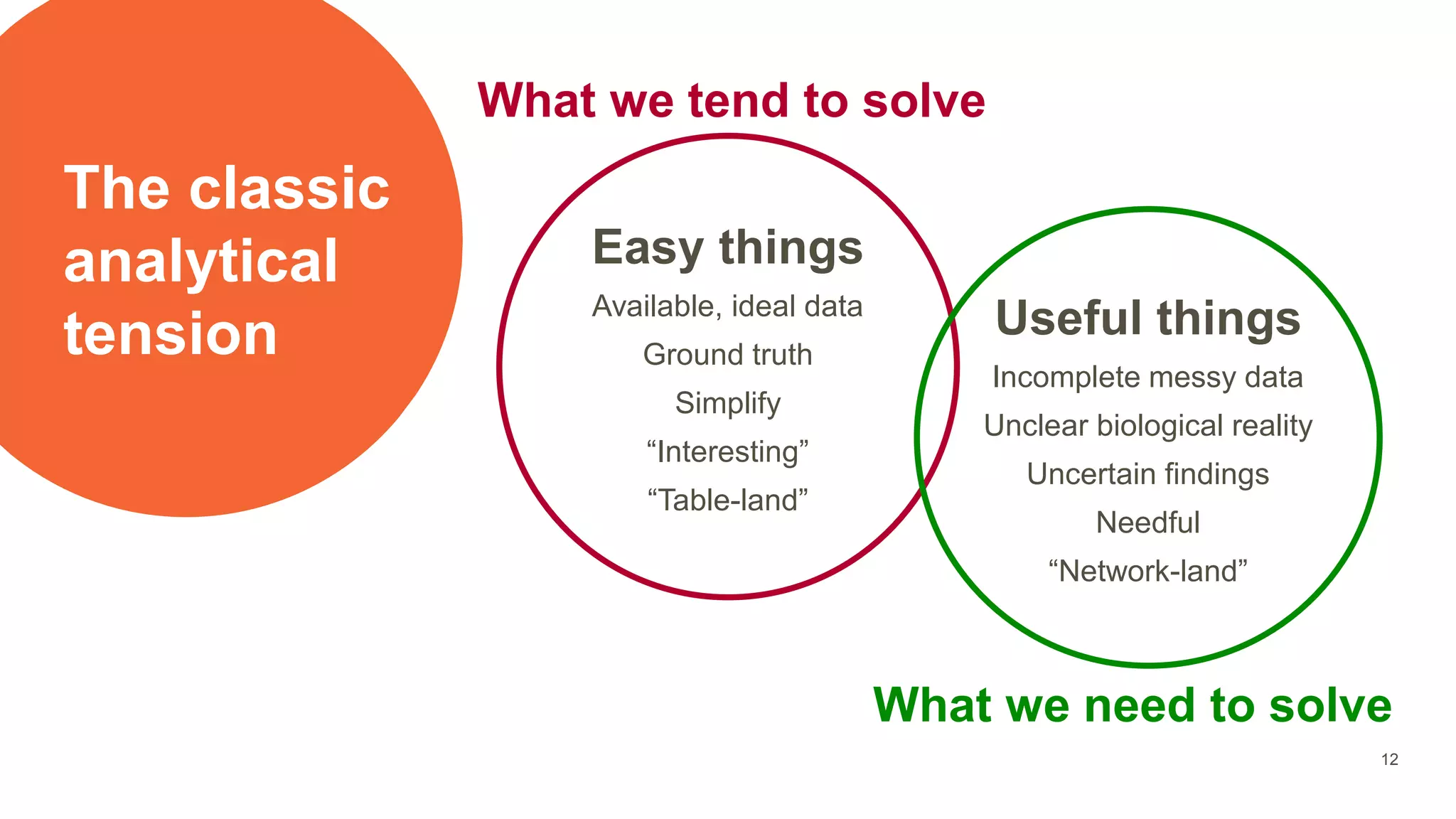


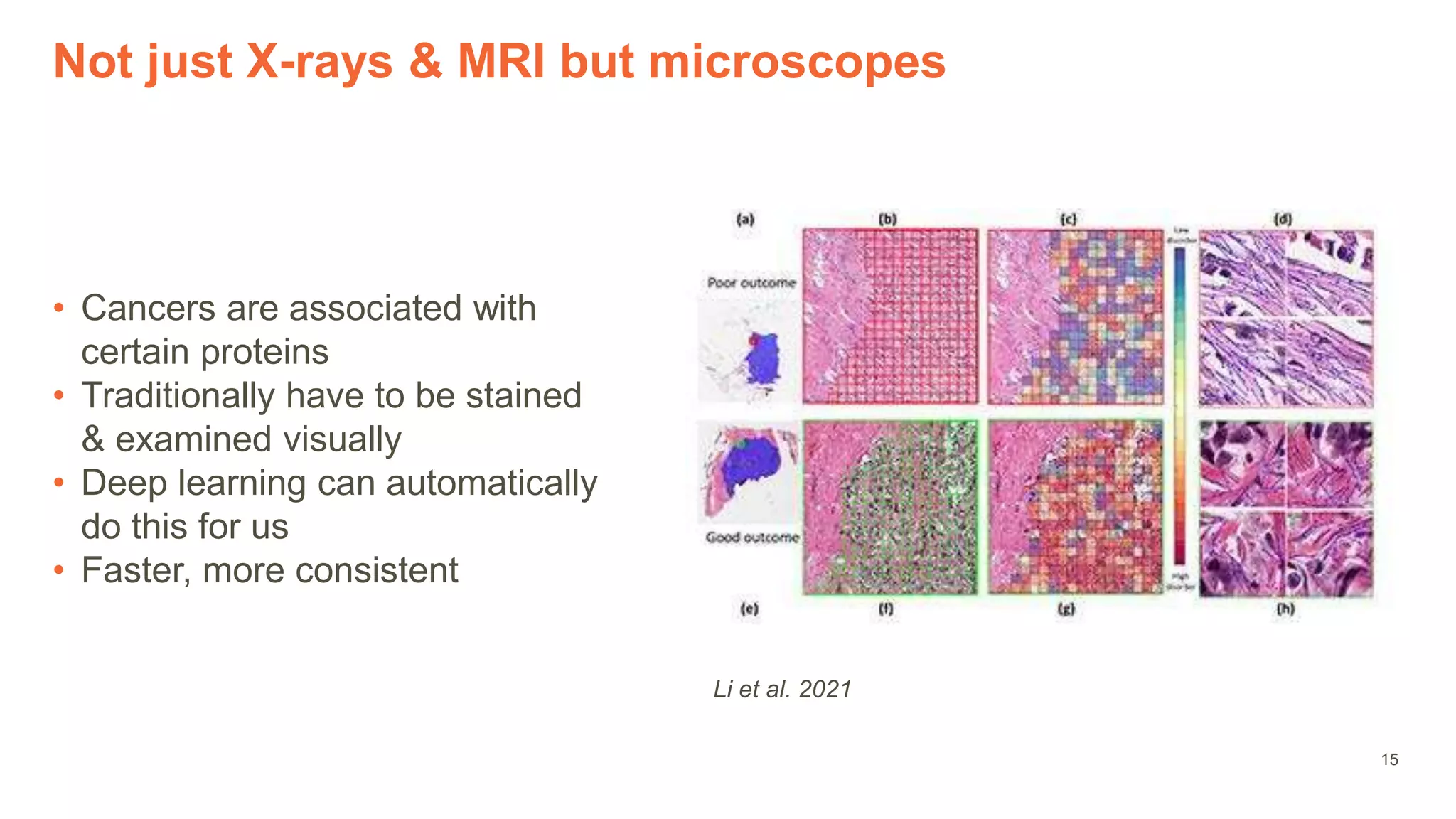
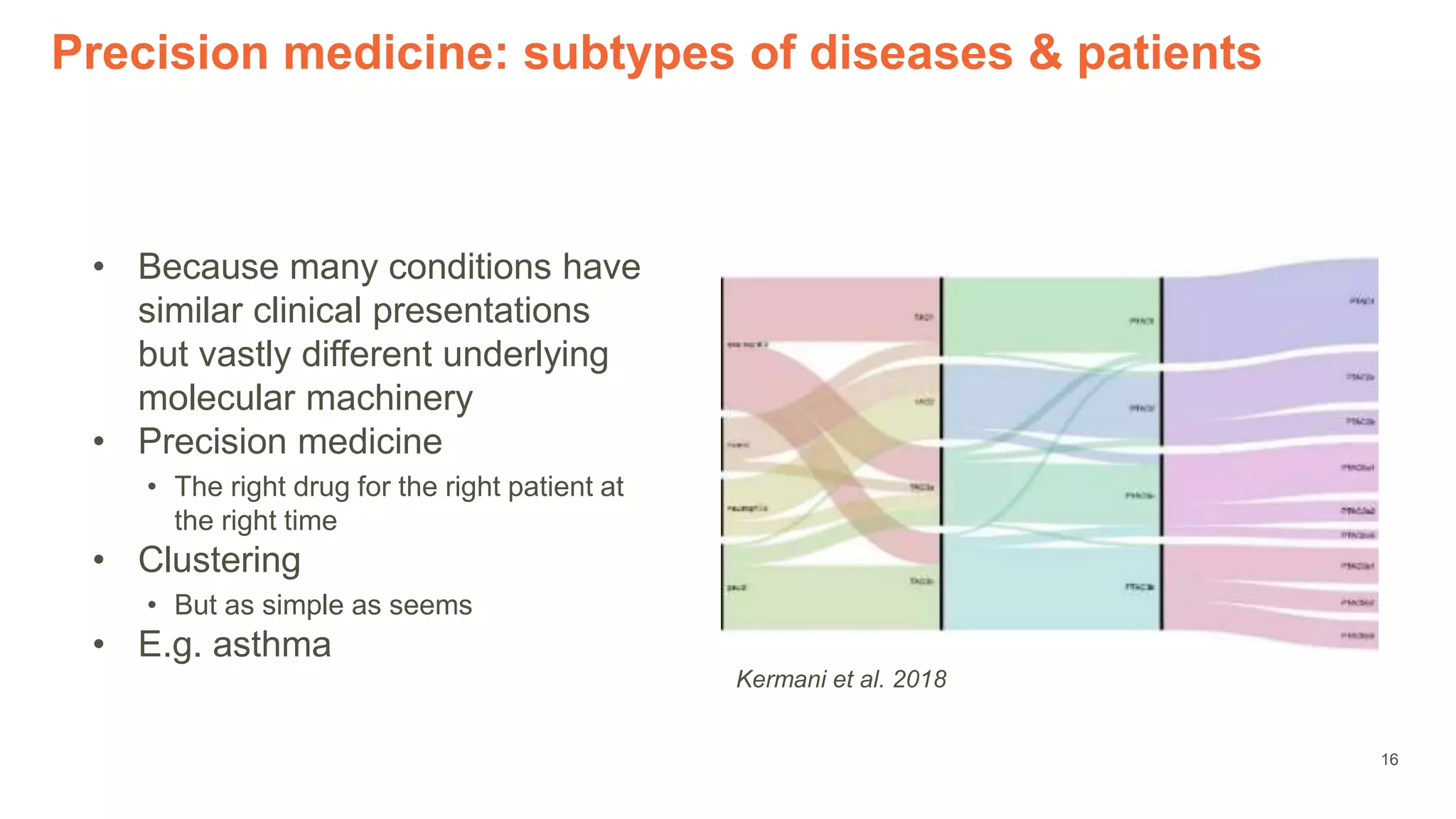
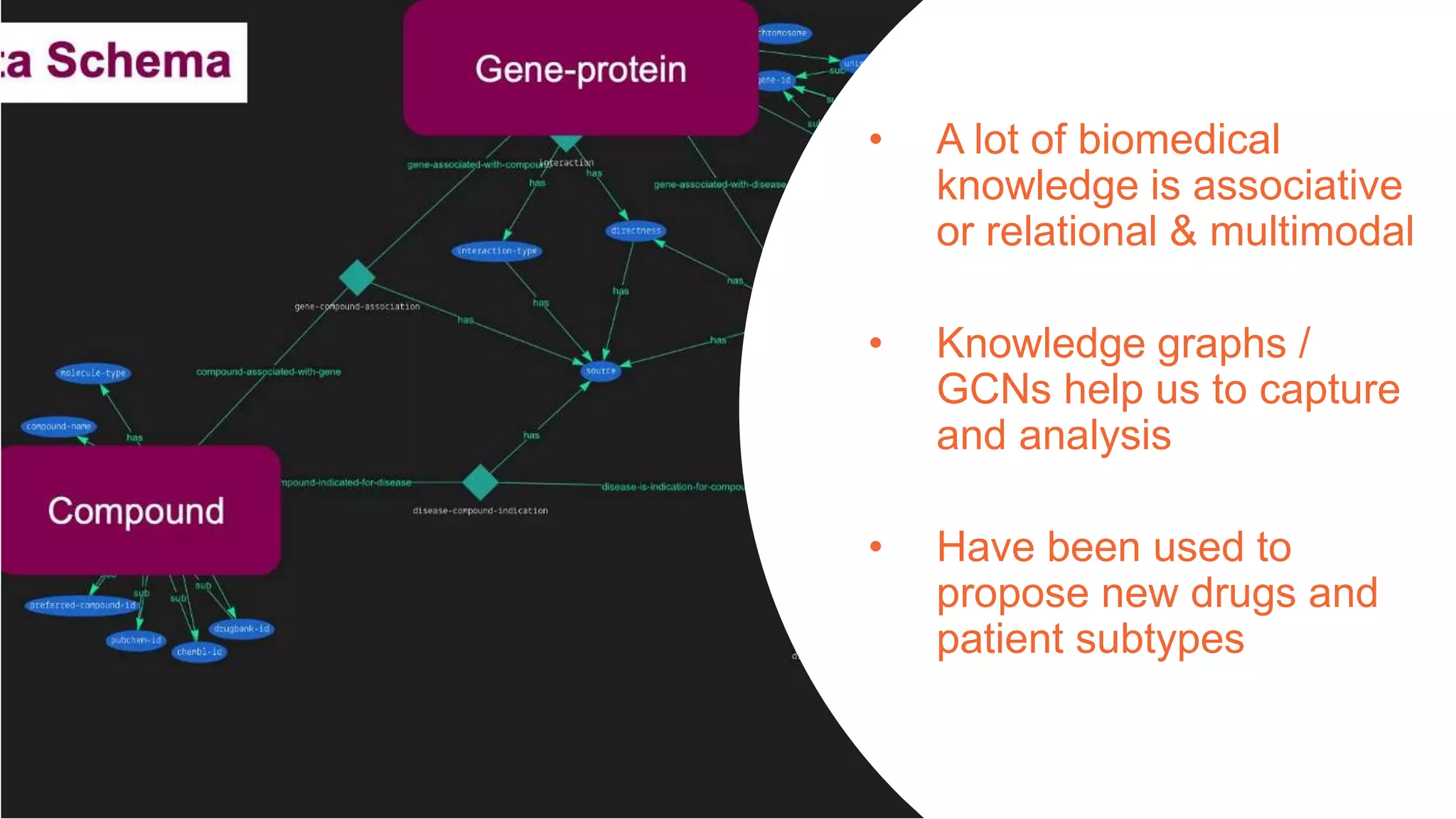
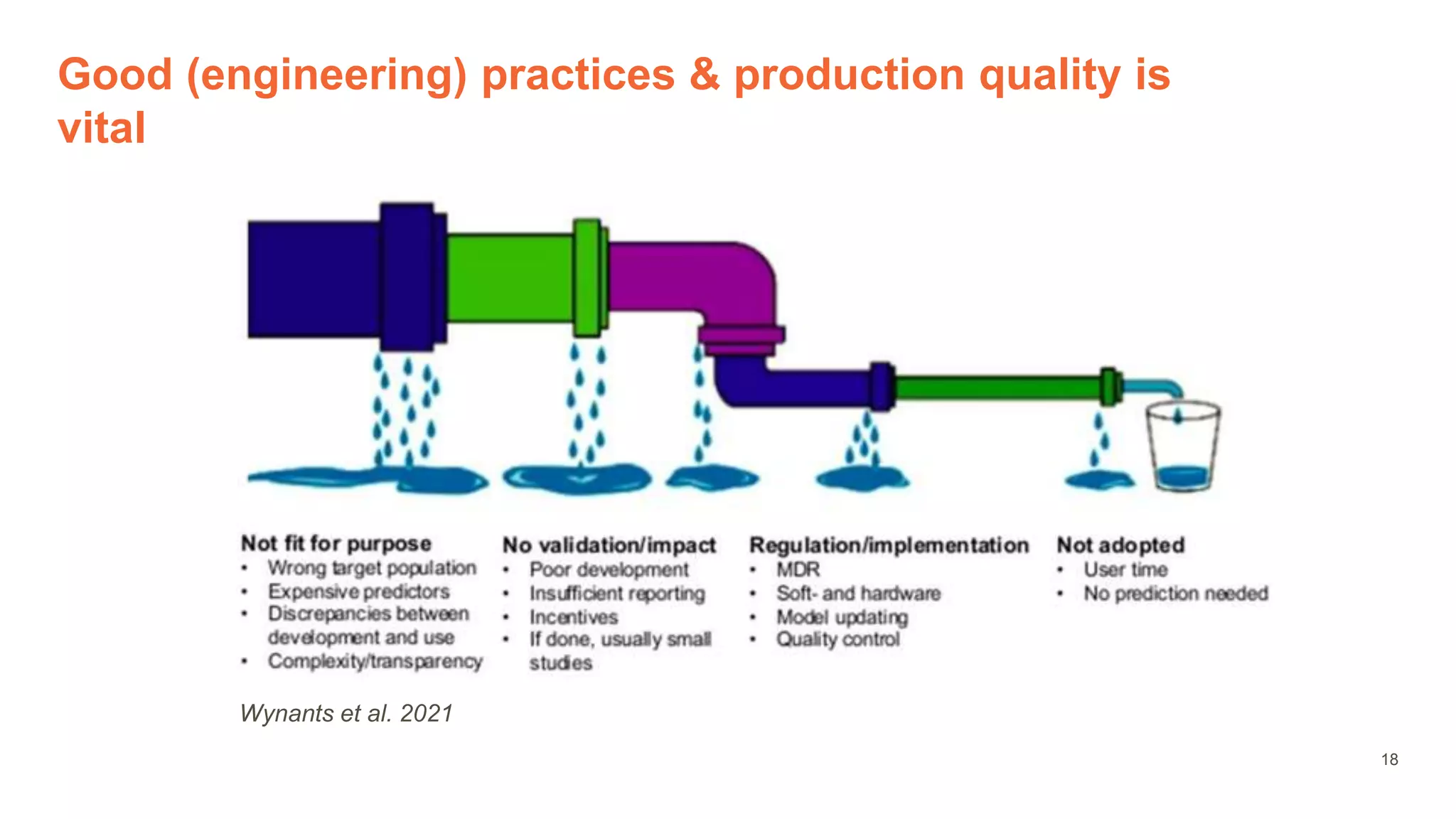
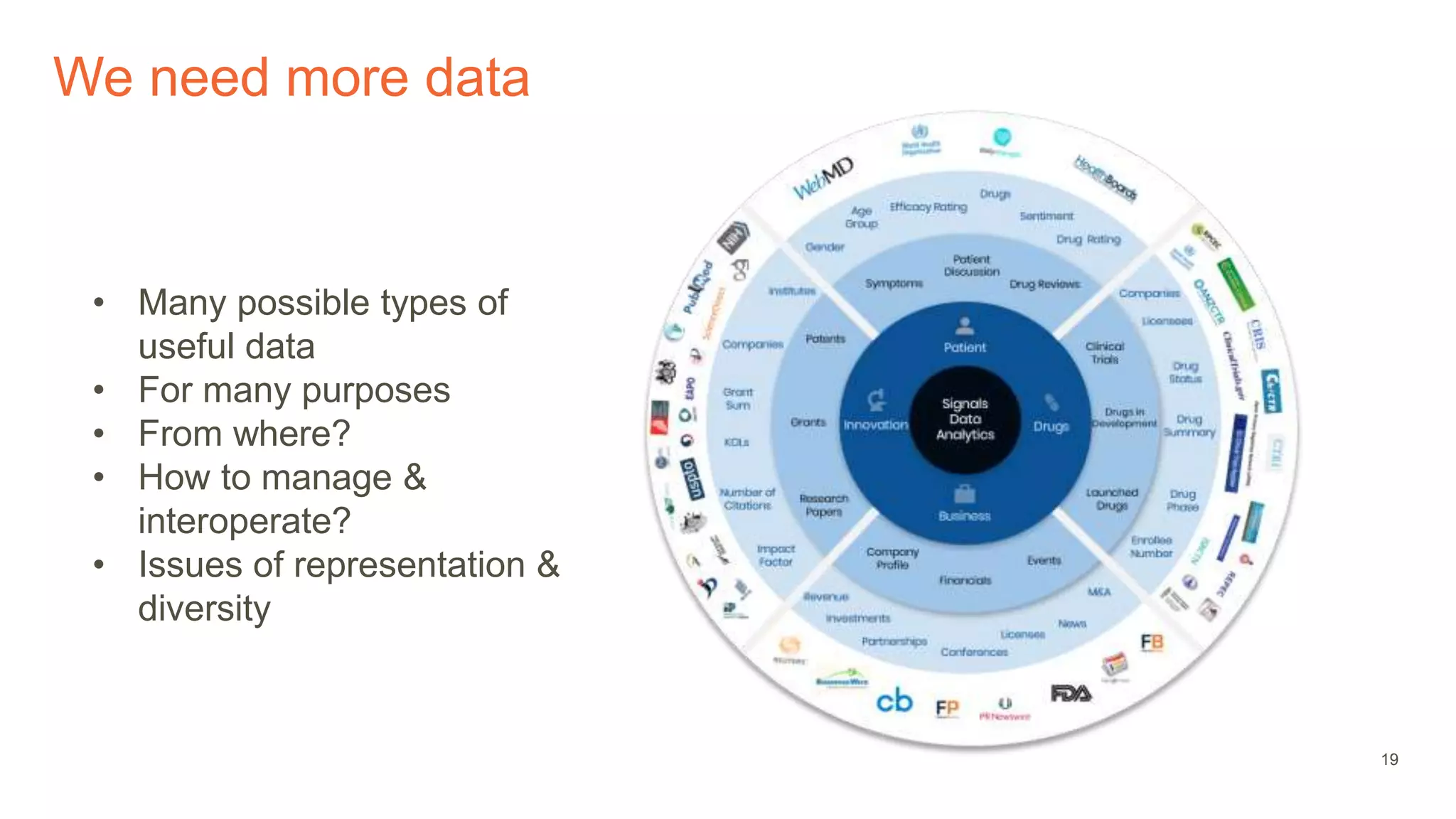




The document provides an overview of the role of machine learning and artificial intelligence in drug development, highlighting the complexities involved in the process and challenges faced due to data quality and biological intricacies. It discusses where ML and AI can have significant impacts, such as in imaging and precision medicine, while emphasizing the need for better data and engineering practices. The conclusion stresses the importance of using ML and AI effectively in pharmaceutical research to enhance drug development outcomes.























































































