Download as PDF, PPTX









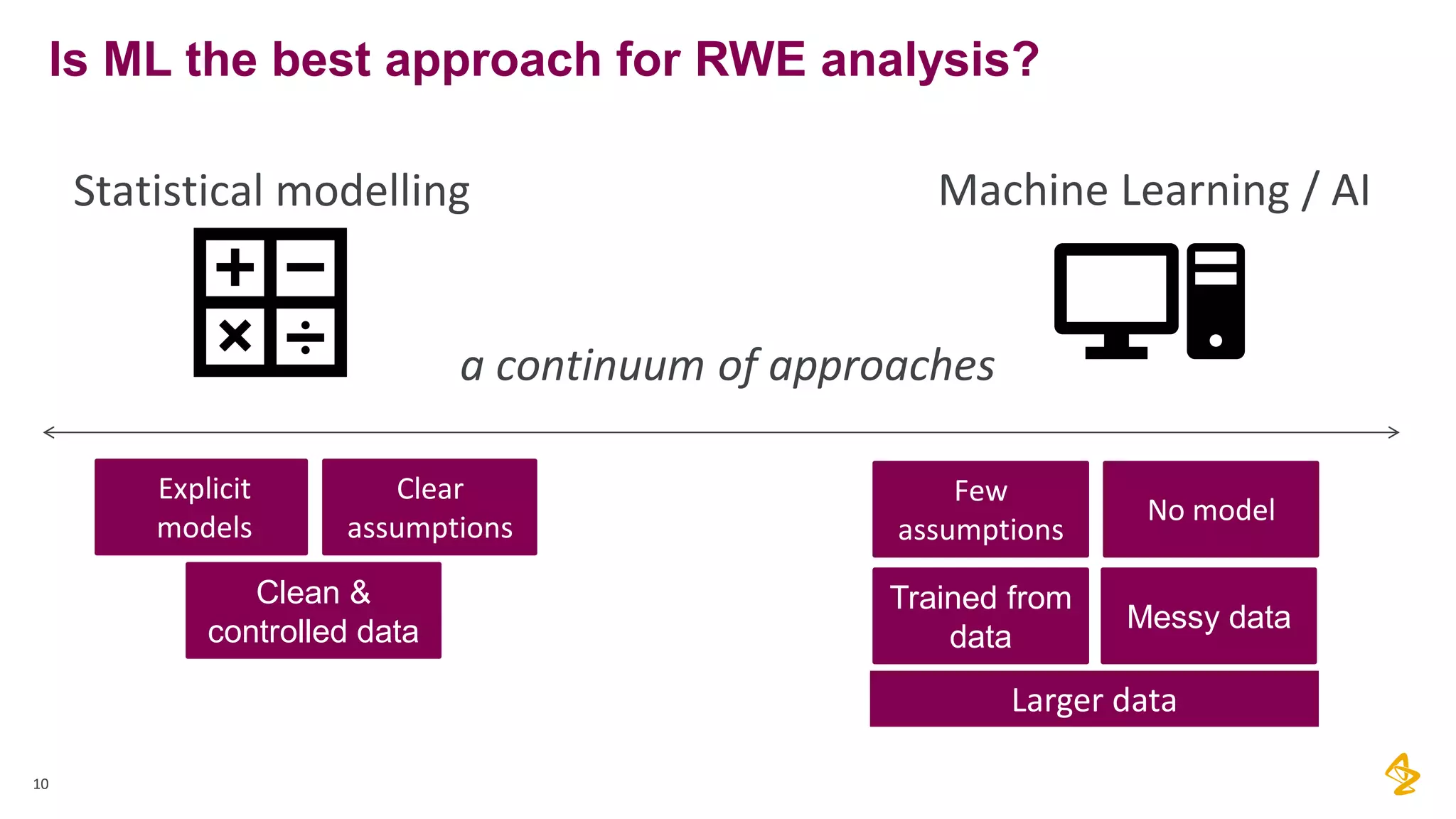
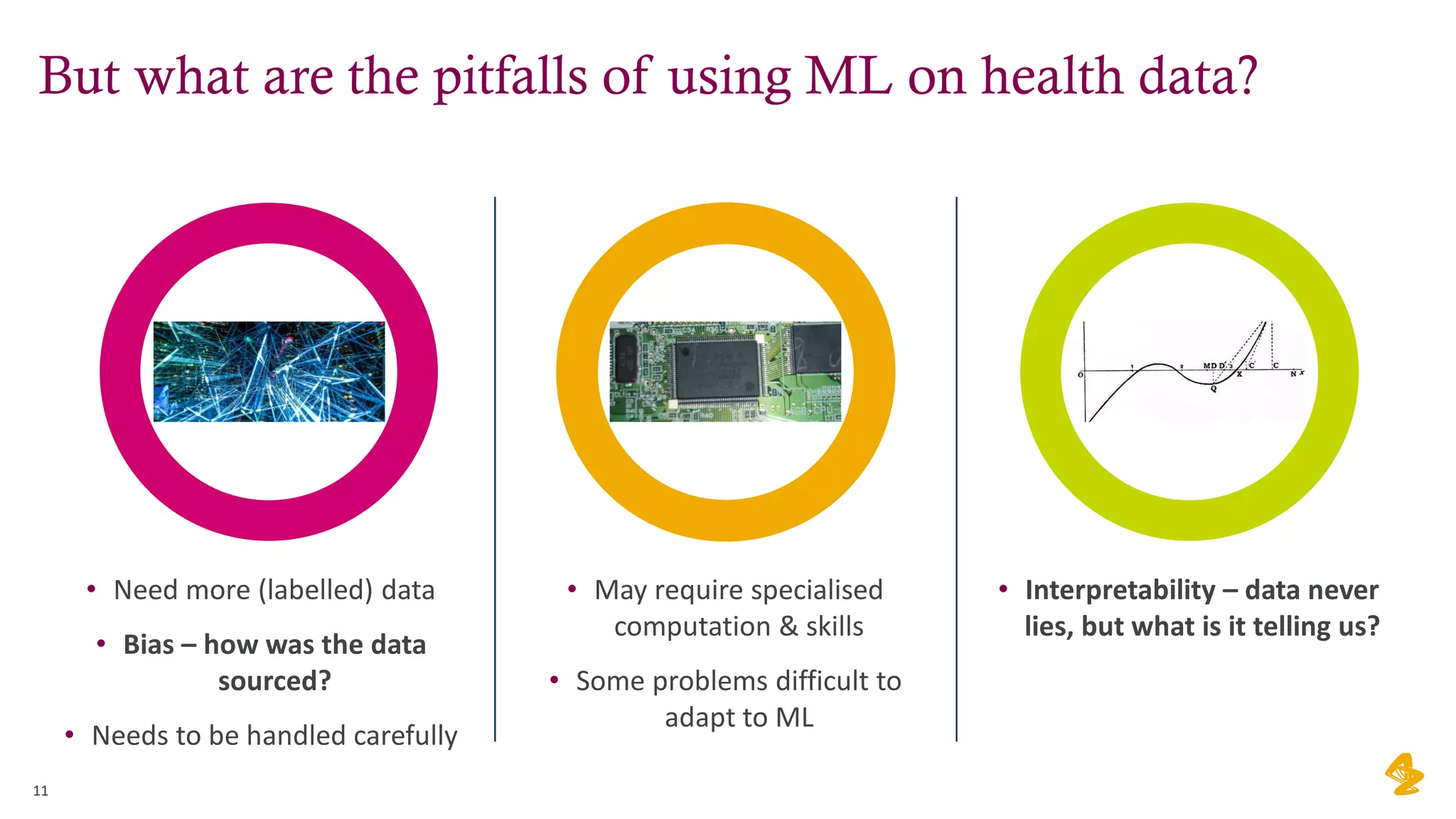







The document discusses the challenges of using real-world evidence (RWE) and machine learning (ML) in healthcare analysis, emphasizing the complexities and biases inherent in health data. It argues that while ML may be a beneficial tool for analyzing RWE, it introduces issues related to data bias, validation, and interpretability. The author suggests that the focus in healthcare analytics should center more on biological insights rather than purely analytical methods.























































































