Download as PDF, PPTX









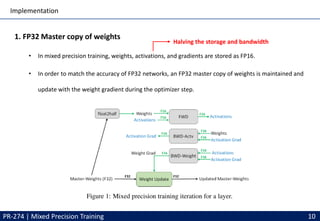
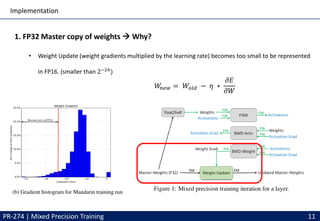
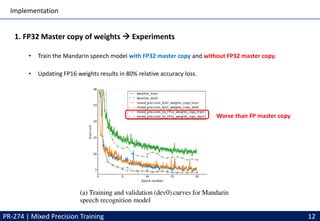
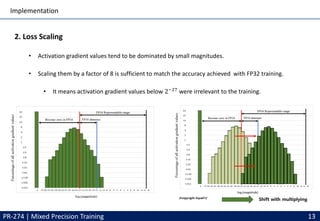





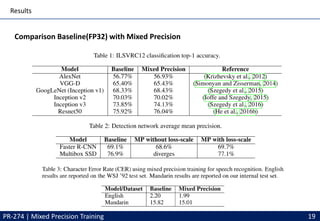


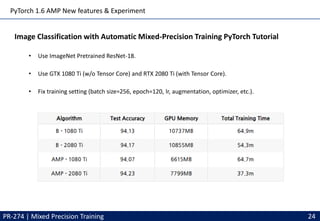



This document discusses mixed precision training techniques for deep neural networks. It introduces three techniques to train models with half-precision floating point without losing accuracy: 1) Maintaining a FP32 master copy of weights, 2) Scaling the loss to prevent small gradients, and 3) Performing certain arithmetic like dot products in FP32. Experimental results show these techniques allow a variety of networks to match the accuracy of FP32 training while reducing memory and bandwidth. The document also discusses related work and PyTorch's new Automatic Mixed Precision features.






![[DL輪読会]Approximating CNNs with Bag-of-local-Features models works surprisingl...](https://cdn.slidesharecdn.com/ss_thumbnails/bagnet-190719032153-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]Whole-Body Human Pose Estimation in the Wild](https://cdn.slidesharecdn.com/ss_thumbnails/20200731wholebodyhumanposeestimationinthewildkuboshizuma-200804012445-thumbnail.jpg?width=640&height=640&fit=bounds)


![[논문리뷰] Data Augmentation for 1D 시계열 데이터](https://cdn.slidesharecdn.com/ss_thumbnails/20181204a-gistdataugwearableeegdkim-181212141033-thumbnail.jpg?width=640&height=640&fit=bounds)





























































