Downloaded 10 times






















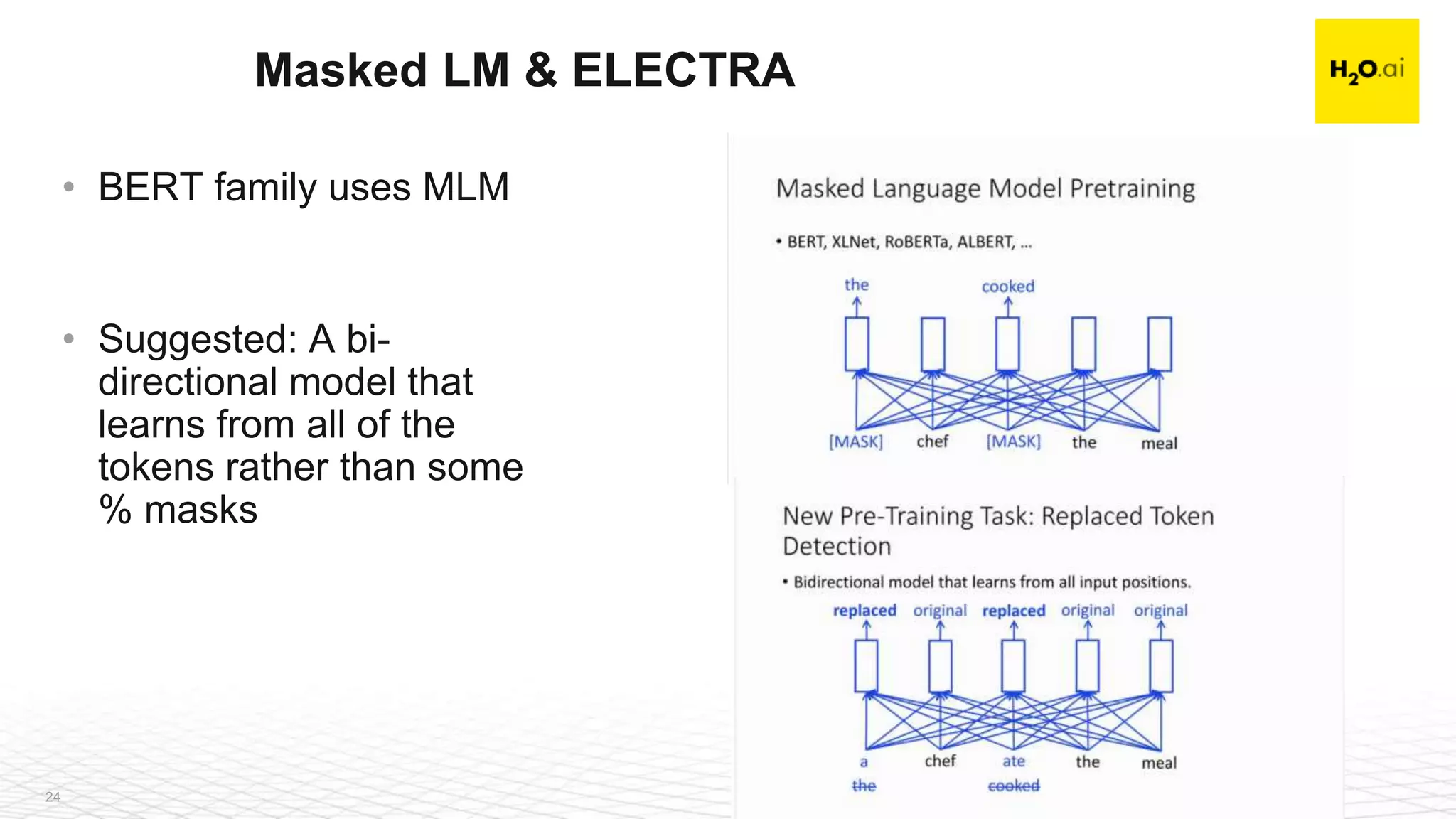
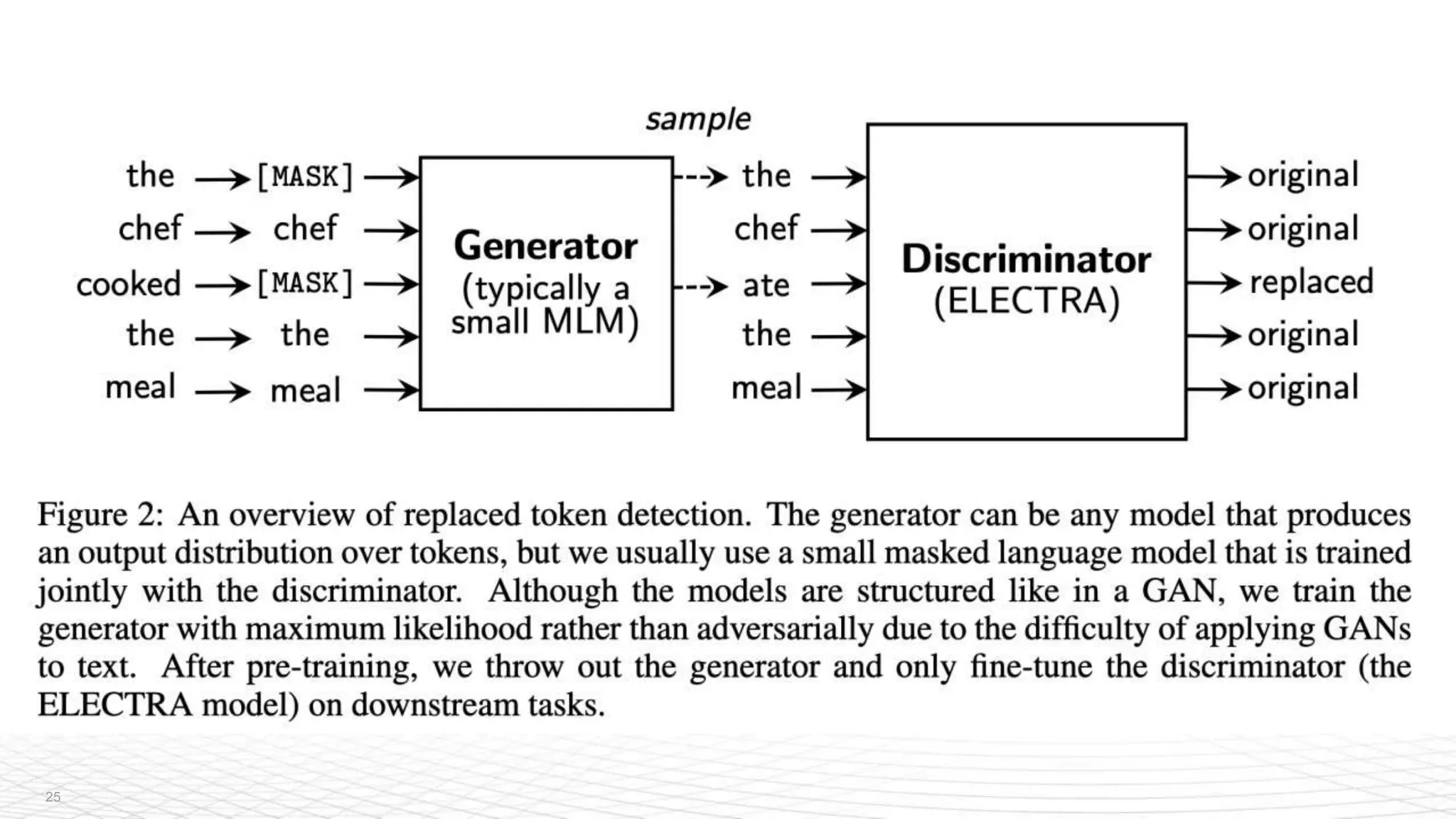
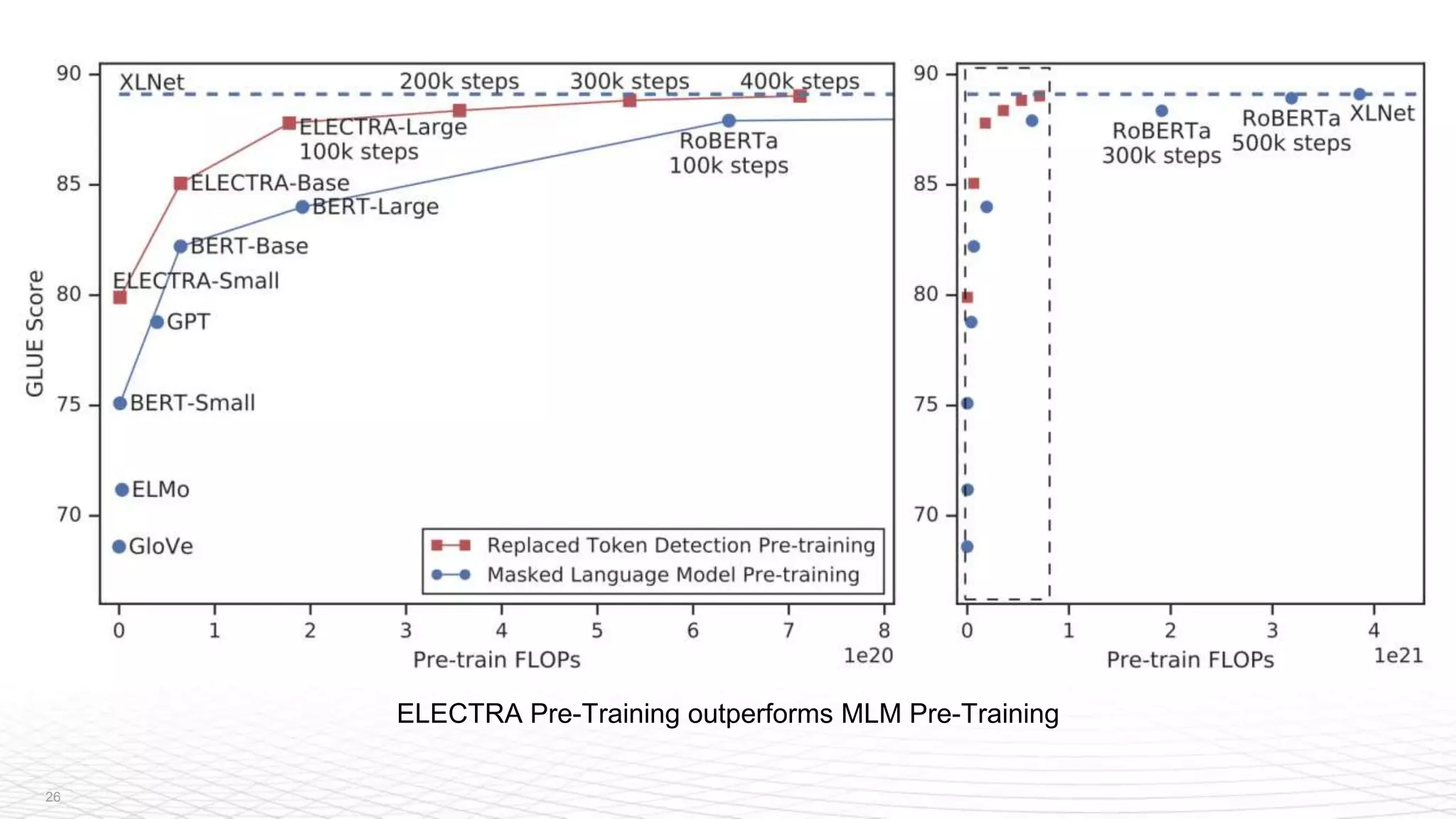



























The document is a recap of the ICLR 2020 conference, highlighting selected paper summaries and discussions on advancements in AI and machine learning. Key topics include image-to-image translation, data augmentation methods, and innovations in natural language processing such as the ELECTRA model. The document also emphasizes the role of community and collaboration in democratizing AI and enhancing its impact across various industries.






















































































