Introduction
• Google BrainTeam의 연구이자 NAS, NASNet의 저자 Barret Zoph가 참여한 연구
• NAS : CNN(CIFAR-10), RNN(Penn Treebank) 구조 설계
• NASNet : CNN(CIFAR-10, ImageNet) Transferable한 구조 설계
• RL 기반으로 CNN 혹은 RNN 구조를 찾자!
• Searching for Activation Functions(ICLR 2018)
• NAS, NASNet처럼 RL 기반으로 Activation Function을 찾자!
• RNN Controller + RL → NAS와 거의 유사, Only Search Space..!
• ReLU를 대체할 만한 Swish 라는 Activation function 발견 및 분석
• 일반화 성능을 보이기 위해 다양한 모델, 데이터셋에 대해 실험 진행
4.
Contribution(1)
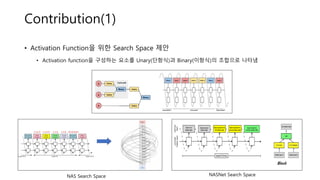
• Activation Function을위한 Search Space 제안
• Activation function을 구성하는 요소를 Unary(단항식)과 Binary(이항식)의 조합으로 나타냄
NAS Search Space NASNet Search Space
5.
Contribution(2)
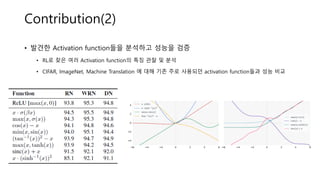
• 발견한 Activationfunction들을 분석하고 성능을 검증
• RL로 찾은 여러 Activation function의 특징 관찰 및 분석
• CIFAR, ImageNet, Machine Translation 에 대해 기존 주로 사용되던 activation function들과 성능 비교
6.
Method(1)
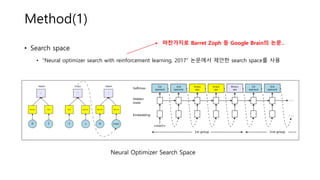
• Search space
•“Neural optimizer search with reinforcement learning, 2017” 논문에서 제안한 search space를 사용
마찬가지로 Barret Zoph 등 Google Brain의 논문..
Neural Optimizer Search Space
7.
Method(1)
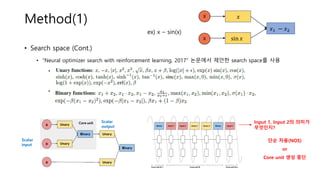
• Search space(Cont.)
• “Neural optimizer search with reinforcement learning, 2017” 논문에서 제안한 search space를 사용
• Unary functions
• Binary functions
Input 1, Input 2의 의미가
무엇인지?
단순 차용(NOS)
or
Core unit 생성 중단
Scalar
input
Scalar
output
ex) x – sin(x)
x
x
𝑥
sin 𝑥
𝑥1 − 𝑥2
8.
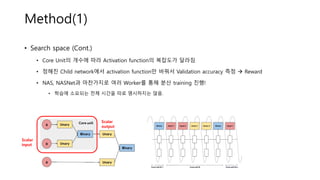
Method(1)
• Search space(Cont.)
• Core Unit의 개수에 따라 Activation function의 복잡도가 달라짐
• 정해진 Child network에서 activation function만 바꿔서 Validation accuracy 측정 → Reward
• NAS, NASNet과 마찬가지로 여러 Worker를 통해 분산 training 진행!
• 학습에 소요되는 전체 시간을 따로 명시하지는 않음.
Scalar
input
Scalar
output
9.
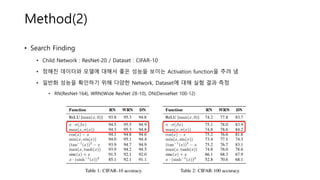
Method(2)
• Search Finding
•Child Network : ResNet-20 / Dataset : CIFAR-10
• 정해진 데이터와 모델에 대해서 좋은 성능을 보이는 Activation function을 추려 냄
• 일반화 성능을 확인하기 위해 다양한 Network, Dataset에 대해 실험 결과 측정
• RN(ResNet-164), WRN(Wide ResNet 28-10), DN(DenseNet 100-12)
10.
Method(2)
• Search Finding(Cont.)
• 대체로 복잡한 activation function일수록 성능 저조 → 1 or 2 core units 에서 좋은 성능
• 성능이 좋은 activation function들의 공통점 : Binary function input으로 x를 사용
• 일반적으로 사용하지 않던 주기 함수들(ex, sin 𝑥 , cos 𝑥)의 적용 가능성을 보여줌
• 나눗셈을 사용하는 function들이 포함되는 경우 대체로 성능 저조
• 성능이 우수한 2가지의 activation function( , ) 중 일반화 성능이 좋았던 전자를 사용
Swish 라 부름
11.
Training with RL
•Controller(LSTM)를 이용하여 예측한 Cell을 통해 Architecture 생성
• 강화학습 알고리즘으로 Proximal Policy Optimization(PPO) 사용
• PPO : 2017, OpenAI
• 전체적인 학습 방법은 NAS, NASNet과 거의 유사
• State : controller의 hidden state
• Action : controller가 생성한 predictions (Activation function)
• Reward : Child Network with Activation function’s accuracy
12.
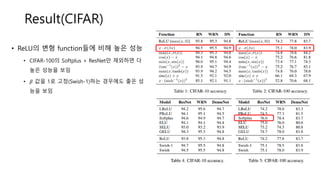
Result(CIFAR)
• ReLU의 변형function들에 비해 높은 성능
• CIFAR-100의 Softplus + ResNet만 제외하면 다
높은 성능을 보임
• 𝛽 값을 1로 고정(Swish-1)하는 경우에도 좋은 성
능을 보임
13.
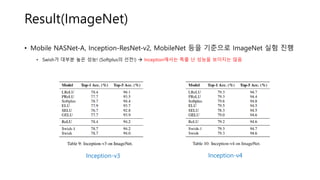
Result(ImageNet)
• Mobile NASNet-A,Inception-ResNet-v2, MobileNet 등을 기준으로 ImageNet 실험 진행
• Swish가 대부분 높은 성능! (Softplus의 선전!)
Mobile NASNet-A Inception-ResNet-v2 MobileNet
14.
Result(ImageNet)
• Mobile NASNet-A,Inception-ResNet-v2, MobileNet 등을 기준으로 ImageNet 실험 진행
• Swish가 대부분 높은 성능! (Softplus의 선전!) → Inception에서는 특출 난 성능을 보이지는 않음
Inception-v3 Inception-v4
15.
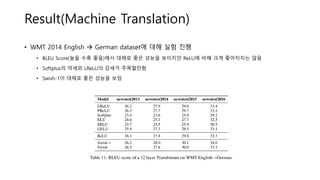
Result(Machine Translation)
• WMT2014 English → German dataset에 대해 실험 진행
• BLEU Score(높을 수록 좋음)에서 대체로 좋은 성능을 보이지만 ReLU에 비해 크게 좋아지지는 않음
• Softplus의 약세와 LReLU의 강세가 주목할만함
• Swish-1이 대체로 좋은 성능을 보임
16.
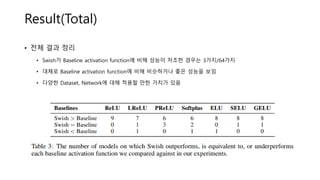
Result(Total)
• 전체 결과정리
• Swish가 Baseline activation function에 비해 성능이 저조한 경우는 3가지/64가지
• 대체로 Baseline activation function에 비해 비슷하거나 좋은 성능을 보임
• 다양한 Dataset, Network에 대해 적용할 만한 가치가 있음
17.
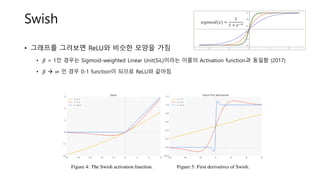
Swish
• 그래프를 그려보면ReLU와 비슷한 모양을 가짐
• 𝛽 = 1인 경우는 Sigmoid-weighted Linear Unit(SiL)이라는 이름의 Activation function과 동일함 (2017)
• 𝛽 → ∞ 인 경우 0-1 function이 되므로 ReLU와 같아짐
18.
Swish
• ReLU와 비교
•공통점 : 상한은 존재하지 않고 하한은 존재
• 차이점 : Smooth하고 non-monotonic 함
미분계수가 같은 부호로 유지
19.
Discussion
• Activation function을위한 Search space 제안
• NAS의 Activation function 버전으로 Novelty가 뛰어나지는 않음, but 2018 ICLR!
• ReLU보다 대체로 좋은 성능을 보이는 것을 증명
• 다양한 Network, 다양한 Dataset에 대해 63가지의 실험 중 60가지에서 높거나 같은 성능!
• 앞으로는 tf.nn.relu 대신 tf.nn.swish가 default로 쓰일 것으로 예상
• 현재 사용 중인 network들에도 간단히 적용할 수 있음
• Optimizer, Architecture, Activation function.. 그 다음은?
























![[224] 번역 모델 기반_질의_교정_시스템](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)












![[컴퓨터비전과 인공지능] 10. 신경망 학습하기 파트 1 - 2. 데이터 전처리](https://cdn.slidesharecdn.com/ss_thumbnails/lec10trainingneuralnetworkspart12datapreprocessing-210223065837-thumbnail.jpg?width=640&height=640&fit=bounds)

![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)


























