Download as PDF, PPTX


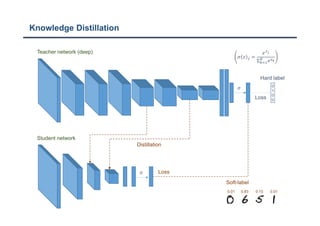
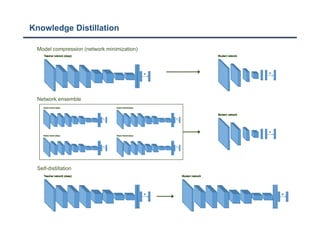
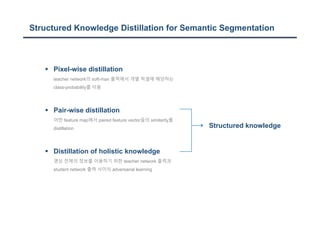
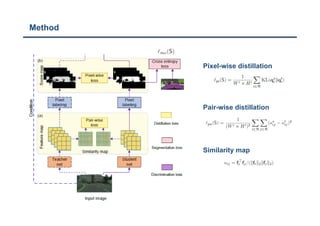
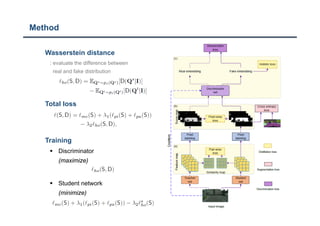
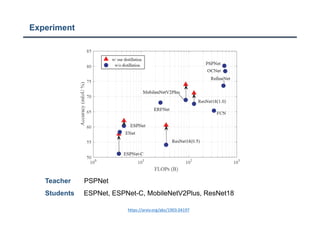

The document discusses a structured knowledge distillation approach for semantic segmentation presented by Sang Jun Lee at CVPR 2019. It highlights techniques such as pixel-wise and pair-wise distillation to transfer knowledge from a teacher network to student networks, including adversarial learning methods for improved accuracy. The study also includes details on minimizing network size and employs various loss functions to evaluate performance.

![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/171222stargan-171225064145-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]AutoAugment: LearningAugmentation Strategies from Data & Learning Data...](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0712f-190719034120-thumbnail.jpg?width=640&height=640&fit=bounds)





























