Downloaded 150 times





![Self-Supervised Visual Representation Learning – Exemplar
• ”Discriminative unsupervised feature learning with exemplar convolutional neural
networks”, 2014 NIPS
• Randomly sample 𝑁 ∈ [50, 32000] patches of size 32x32 from different images
• Apply a various transformations to a randomly sampled “seed” image patch
• Train to classify these exemplars as same class → cannot be scalable to large datasets!
Seed
Transformations
Regions containing considerable gradients
Train with STL-10 dataset (96x96)](https://image.slidesharecdn.com/unsupervisedvisualrepresentationlearningoverview-191117143841/85/Unsupervised-visual-representation-learning-overview-Toward-Self-Supervision-5-320.jpg)
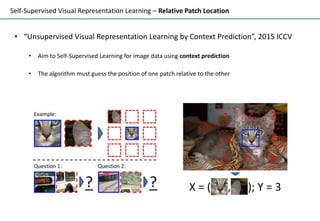
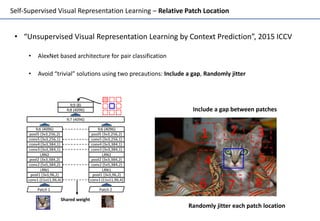
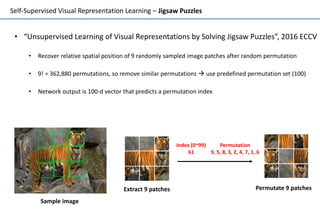

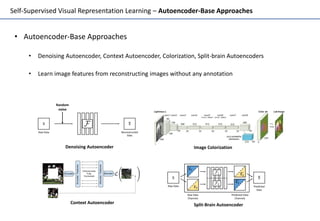

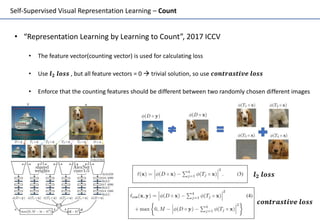
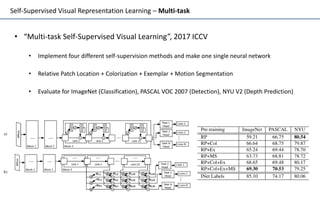
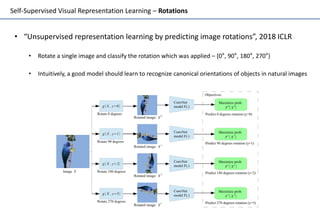
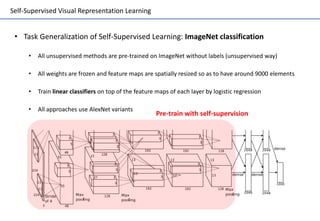
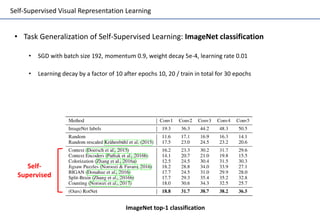
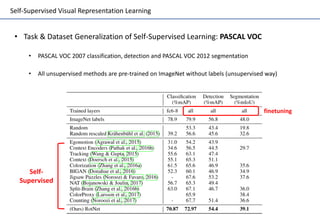
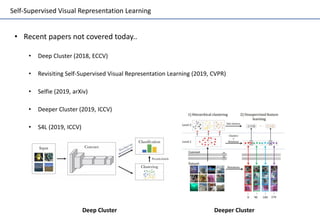
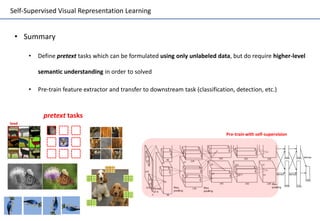


Self-supervised learning uses unlabeled data to learn visual representations through pretext tasks like predicting relative patch location, solving jigsaw puzzles, or image rotation. These tasks require semantic understanding to solve but only use unlabeled data. The features learned through pretraining on pretext tasks can then be transferred to downstream tasks like image classification and object detection, often outperforming supervised pretraining. Several papers introduce different pretext tasks and evaluate feature transfer on datasets like ImageNet and PASCAL VOC. Recent work combines multiple pretext tasks and shows improved generalization across tasks and datasets.








![[DL Hacks]Self-Attention Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/self-attentiongenerativeadversarialnetworks-180730075733-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)



























































