Paper Review
ImageNet 데이터셋+ ResNet-50에
다양한 Trick들을 적용해서
Top-1 accuracy를
무려 4% point를 끌어 올림!
Bag of Tricks for Image Classification with CNNs, 2019 CVPR
5.
Paper Review
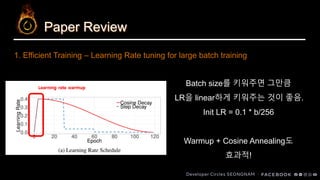
Batch size를키워주면 그만큼
LR을 linear하게 키워주는 것이 좋음.
Init LR = 0.1 * b/256
Warmup + Cosine Annealing도
효과적!
1. Efficient Training – Learning Rate tuning for large batch training
6.
Paper Review
ResNet과 같은Residual Connection이
있는 경우, Batch Norm의 Gamma를
0으로 초기화하는 것이 좋다는 실험 결과
L2 weight decay를 bias와 Batch Norm의
parameter에는 적용하지 않는 것이
좋다는 실험 결과
2. Training Heuristic
Zero init
7.
Paper Review
Mixed PrecisionTraining을 통해 FP16으로
망을 안정적으로 학습시킬 수 있음.
GPU Memory 사용량이 줄어들어서 Batch
Size를 키울 수 있고, 연산이 빨라져서 학습
시간을 대폭 줄일 수 있음.
3. Low-precision Training
Paper Review
전체 방법들총 정리
Learning Rate Tuning
Zero Gamma
Selective Weight Decay
Low Precision Training
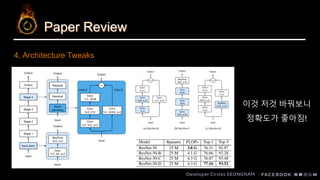
ResNet-50 Tweaks
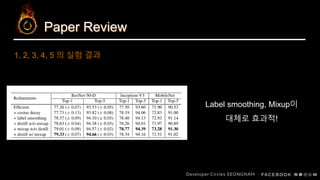
Label Smoothing
Knowledge Distillation
Mixup Augmentation
13.
Paper Review
MXNet 기반Gluon CV에 구현되어 있음.
하지만 Bag of Tricks를 쓰자고 기존
코드를 전부 MXNet으로 옮길 순 없지..
Bag of Tricks for Image Classification with CNNs, 2019 CVPR
14.
Related Works
Bag ofTricks 저자들의
Object Detection 버전! (자매품)
YOLOv3은 무려 5% 포인트 증가!
Bag of Freebies for Training Object Detection Neural Networks, 2019 arXiv
15.
Related Works
Clova Vision,Naver의 논문
각종 최신 방법론을 짬뽕하여
Assemble-ResNet-50 기준
82.8% Top-1 Acc 달성!
Compounding the Performance Improvements of Assembled Techniques in
a Convolutional Neural Network, 2020 arXiv
16.
Related Works
YOLO도 질수 없다!
각종 테크닉들을 적용하여
성능을 대폭 향상시킴!
YOLOv4: Optimal Speed and Accuracy of Object Detection, 2020 arXiv
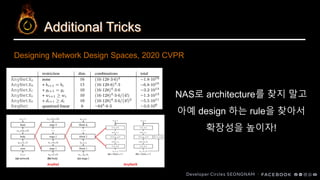
Additional Tricks
섞거나 (Mixup)
구멍낼 거면 (Cutout)
둘 다 하면 안됨?? (CutMix)
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable
Features, 2019 ICCV
19.
Additional Tricks
Adam 모르면간첩
경험 상 Fine-tuning 할 때는 작은
lr과 Adam을 쓰는게 좋은 결과를
보였음!
Adam: A Method for Stochastic Optimization, 2015 ICLR
20.
Additional Tricks
Adam의 학습극 초반 bad local
optima convergence를 개선하기 위해
adaptive learning rate의 variance를
줄여서 학습 안정성을 높인
RAdam Optimizer 제안
On the Variance of the Adaptive Learning Rate and Beyond, 2020 ICLR
21.
Additional Tricks
말 그대로batch 마다
Random하게
Augmentation 뽑아서
적용하자!
RandAugment: Practical automated data augmentation with a reduced search
space, 2020 CVPRW
22.
Additional Tricks
Norm +Act를 한번에 고려함.
진화 알고리즘을 통해
특정 데이터셋에 대한
최적의 연산 조합을 찾자!
Evolving Normalization-Activation Layers, 2020 arXiv
23.
Additional Tricks
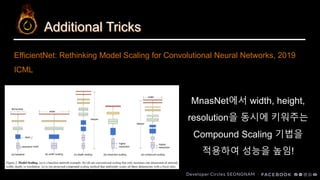
MnasNet에서 width,height,
resolution을 동시에 키워주는
Compound Scaling 기법을
적용하여 성능을 높임!
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, 2019
ICML
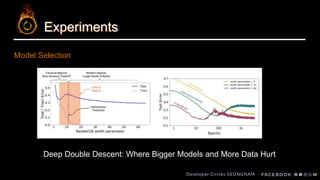
Experiments
Model Selection
- Train80%, Validation 20%, Last Model 로 Test
- Train 80%, Validation 20%, Best Model (Val Acc가 가장 높았던 epoch) 로 Test
- Train 100%, Last Model 로 Test
K-fold CV, 반복 실험까지 했으면 더 좋았을 텐데.. 크흠..
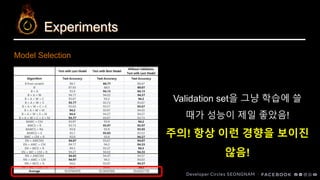
Experiments
Experimental Results
B :Baseline / A : Adam Optimizer / W : Warm up / C : Cosine
Annealing S : Label Smoothing / M : MixUp Augmentation
ImageNet Pretraining이 역시 효과적!
Adam이 fine-tuning에 역시 효과적!
Warm up이 좋은 결과를 보임!
나머지 기법들은 무난한 결과..
37.
Experiments
Experimental Results
CM: CutMix/ R: RAdam / RA: RandAugment / E: EvoNorm
대부분의 기법이 재미를 못 봄..
이유는 Hyper-parameter를 search
하지 않았기 때문..!
최적 셋팅을 찾으면 성능 향상이 될
것이라고 믿습니다!
Experiments
Summary
• 재미 본방법론
• 역시 Adam이 좋구만
• Learning Rate Warmup은 요새는 거의 기본으로 쓰이는 이유가 있음
• Cosine, Label Smoothing, MixUp, CutMix 는 좋긴 한데 드라마틱하진 않음!
• EfficientNet, RegNet도 역시 ResNet보다 대체로 좋은 경향!
• 재미 못 본 방법론
• EvoNorm, RandAugment 는 쓰나 안 쓰나 비슷한 성능!
모든 방법론들이 ImageNet에서만 검증된 기법이라
성능 향상이 극적이진 않은 건 공통점
41.
Experiments
아쉬웠던 점 &Further Works
• 반복 실험을 해서 randomness로 인한 편차를 줄였으면 더 좋았을 것 같음!
• Data 전 처리나 Augmentation 등에 시간을 거의 쓰지 않음! → 더 높은 성능 달성할 수 있을 듯?
• Dataset 자체가 쉬워서 그런지 성능 향상이 미미했음.
• ImageNet에 특화된 기법들이 많아서 데이터 셋이 바뀌면 그에 따라 hyper-parameter 등을 tuning
해줘야 하는데 이 과정을 대부분 생략함.
• 다양한 technique 들을 추가하고 실험해볼 예정!




















































![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 5 - Others](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture5others-210215060452-thumbnail.jpg?width=640&height=640&fit=bounds)

![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 4 - ResNet](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture4resnet-210214112234-thumbnail.jpg?width=640&height=640&fit=bounds)














