"Dataset and metrics for predicting local visible differences" Paper Review
1.
SIGGRAPH 2018 참석후기 및 논문 리뷰
Dataset and metrics for predicting local visible differences
수아랩 이호성
2.
SIGGRAPH 2018
• SIGGRAPH(SpecialInterest Group on Graphics and Interactive Techniques)
• 컴퓨터 그래픽스의 최대 규모를 자랑하는 컨퍼런스
• 8.12(일) ~ 8.16(목) 캐나다 밴쿠버에서 개최
3.
SIGGRAPH 2018 –Exhibition
• 각종 그래픽스, VR/AR 등 다양한 주제의 데모, 포스터, 전시 활발
• VR Theater, Electronic Theater 등 관람할 수 있는 contents
• Technology 뿐만 아니라 Art 관련 전시회도 다수
• NVIDIA 젠슨 황 회장이 Turing 아키텍처 기반 GPU 공개
4.
SIGGRAPH 2018 –Training
• NVIDIA의 Hands-On Training Session
• 1시간 30분 ~ 2시간 분량의 실습 수업 진행
• 정해진 수업 시간에만 사용 가능한 aws cloud 제공 및 실습 코드(jupyter notebook) 제공
• “Image Super Resolution using Autoencoders”
• “Analogous Image generation using CycleGAN”
• “Image creation using Generative Adversarial Networks in Tensorflow and DIGITS”
• “Anomaly Detection with Variational Autoencoder”
• “Image Style Transfer with Torch”
• etc (Reinforcement Learning, Character Animation)
5.
SIGGRAPH 2018 –Technical Paper
• 굉장히 광범위한 주제의 논문 발표
• 광학, 유체, VR/AR, Sketching, 3D rendering, 음성 등
• 학회 첫날 “Fast Forward”라는 프로그램이 굉장히 인상적
• 모든 oral presentation 발표자들이 각 30초간 자신의 연구를 소개 (총 172편)
• 비디오 준비 or 말로 빠르게 ppt 발표
• https://www.youtube.com/watch?v=CV_14aUBxsI
6.
SIGGRAPH 2018 –Paper Review
• Technical Paper의 “Perception & Haptics” Session의 논문
• “Dataset and metrics for predicting local visible differences”
7.
Introduction
• “Dataset andmetrics for predicting local visible differences”
• 질문: 사람이 인식하는 시각적 차이를 예측할 수 있을까?
• 원본 이미지가 있고, 무언가를 거친 타겟 이미지가 있을 때, 둘 간의 차이를 나타내는 metric
• 컴퓨터가 인식하는 시각적 차이는 주로 PSNR, SSIM 등의 quality metric을 사용
• 지엽적인 difference는 사람은 잘 구분하지만 위의 metric은 구분하지 못함, vice versa
• 결국 application을 위해서는 quality metric보다는 사람을 기준으로 metric을 이용할 필요
• 예시
• 배심원: 컴퓨터
• 숫자: 컴퓨터가 계산한 quality metric
• 원본 이미지가 주어졌다고 가정하고, 타겟 이미지를 보여주는 상황
12.
Introduction
• “Dataset andmetrics for predicting local visible differences”
• 질문: 사람이 인식하는 이미지간 시각적 차이를 예측할 수 있을까?
• 컴퓨터가 인식하는 시각적 차이는 주로 PSNR, SSIM 등의 numerical metric을 사용
• 사람 눈에 잘 보이는 difference들은 사람은 잘 구분하지만 위의 metric은 구분하지 못함
→ “사람이 인식하는 이미지간 시각적 차이”를 예측하는 학습 방법론 제안!
13.
Related Work
• ImageMetric
• Quality metric
• Reference image와 distorted image의 차이를 하나의 global quality score를 예측
• PSNR(Peak Signal-to-Noise Ratio), SSIM(Structural Similarity Index Metric), VSI(Visual Saliency-Induced Index), etc
• 사람이 주관적으로 평가한 지표인 MOS(Mean Opinion Score) 등의 지표도 있음
• Visibility metric
• 사람이 reference image와 distorted image를 보고 차이를 감지하는 지를 예측
• 결과를 visibility map으로 예측 → 사람이 반응하는 정도에 따라 graphics application 성능 조절에 사용
14.
Contribution
• “사람이 인식하는이미지간 시각적 차이”를 예측하는 학습 방법론 제안!
• 사람이 어떻게 인식하는지 학습 데이터가 필요!
• 존재하는 데이터셋 매우 부족 → largest publicly available dataset 제작!
• 취득해도 GT로 사용하기엔 noisy할 가능성 높음 → statistical modeling 방법 제안!
• 기존 방법론들보다 우수한 성능!
• CNN-based 방법론을 통해 기존 방법론들보다 우수한 방법론 제안!
• 이 방법을 기존 방법론에 적용하여 재학습 시키면 성능 향상! (이식성)
• 3가지 실험을 통해 실용적인 application에 적용 가능함 입증!
• JPEG Compression
• Super-Resolution
• Watermarking
15.
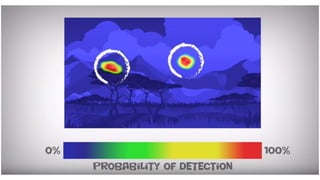
Method
• Dataset 제작
•Visible distortion 관련 소규모의 데이터셋을 취합하여 “Stimuli” 라는 데이터셋 제작
• 총 557장으로 구성되어 있으며 각기 다른 특징(distortion)을 가짐
• 이미지에 대한 visibility map(GT) 취득을 위해 실험자를 모집하여 데이터 수집
Stimuli dataset 예시
16.
Method
• Dataset 제작(실험환경)
• Visible distortion 관련 소규모의 데이터셋을 취득하여 “Stimuli” 라는 데이터셋 제작
• 이미지에 대한 visibility map(GT) 취득을 위해 실험자를 모집하여 데이터 수집
• 편의성을 위해 software 제작 – visible distortion marking web application
• 46명의 실험자로부터 visibility marking data 취득 (동일한 환경, 보수 지급, 피로 방지 차원에서 여러 번에 나눠서 실험)
• 동일한 위치에 distortion magnitude를 3단계로 나눠서 차례대로(low – middle – high) marking
실험용 sofeware 예시
17.
Method
• Dataset 제작(Datamodeling)
• 실험자들로부터 취득한 data를 그대로 사용하지 않고 통계적 모델링 기법 사용
• 앞선 실험으로 얻은 data들이 Stochastic process의 결과물이므로 noisy하고 100% 신뢰하기 어렵다고 주장
• ex) 실제로 같은 이미지를 같은 사람한테 보여줬을 때 결과가 다른 경우도 있었음.
• ex) 모든 곳에 집중하는 것이 아니고, 일부 영역은 아예 집중해서 관찰하지 않는 경우도 있음.
• 그대로 사용하는 경우, biased 된 결과들의 평균의 경향만 학습 가능
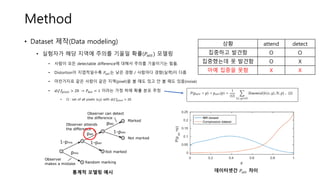
• Marking tool 이용으로 인한 실수가 발생할 확률(𝑃 𝑚𝑖𝑠 = 0.01) 모델링
• 정신물리학 연구에서 흔히 사용되는 실수 확률 모델링 기법으로, 예기치 못한 실수로 인해 모델이 over penalizing 하는 것 방지
통계적 모델링 예시
18.
Method
• Dataset 제작(Datamodeling)
• 실험자가 해당 지역에 주의를 기울일 확률(𝑃𝑎𝑡𝑡) 모델링
• 사람이 모든 detectable difference에 대해서 주의를 기울이기는 힘듦.
• Distortion이 지엽적일수록 𝑃𝑎𝑡𝑡는 낮은 경향 / 사람마다 경향(실력)이 다름
• 마찬가지로 같은 사람이 같은 지역(pixel)을 볼 때도 있고 안 볼 때도 있음(noise)
• 𝑑𝑖𝑓𝑓𝑝𝑖𝑥𝑒𝑙 > 20 → 𝑃𝑑𝑒𝑡 = 1 이라는 가정 하에 확률 분포 추정
• Ω : set of all pixels (x,y) with 𝑑𝑖𝑓𝑓𝑝𝑖𝑥𝑒𝑙 > 20
통계적 모델링 예시
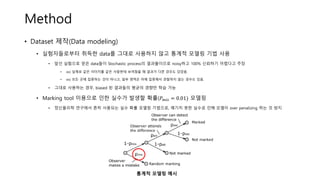
상황 attend detect
집중하고 발견함 O O
집중했는데 못 발견함 O X
아예 집중을 못함 X X
데이터셋간 𝑃𝑎𝑡𝑡 차이
19.
Method
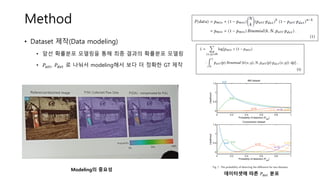
• Dataset 제작(Datamodeling)
• 앞선 확률분포 모델링을 통해 최종 결과의 확률분포 모델링
• 𝑃𝑎𝑡𝑡, 𝑃𝑑𝑒𝑡 로 나눠서 modeling해서 보다 더 정확한 GT 제작
Modeling의 중요성
데이터셋에 따른 𝑃𝑑𝑒𝑡 분포
20.
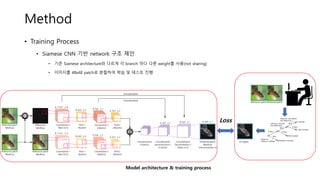
Method
• Training Process
•Siamese CNN 기반 network 구조 제안
• 기존 Siamese architecture와 다르게 각 branch 마다 다른 weight를 사용(not sharing)
• 이미지를 48x48 patch로 분할하여 학습 및 테스트 진행
GT patch
Loss
Model architecture & training process
21.
Result
• 기존 metric대비 높은 성능
• 대부분의 데이터셋에서 CNN 기반 제안한 방법론이 성능 우수
• 제안하는 방법론을 기존 방법에 적용하여 재학습 시 성능 우수
기존 metric 재학습 성능 기존 metric 대비 CNN 성능
22.
Applications
• JPEG compression
•대표적인 손실 압축 방법이며, 흔히 볼 수 있는 .jpg, .jpeg 이미지 등의 확장자를 사용
• 압축률을 높일수록 파일 크기는 줄어들지만 화질도 감소 → 적당히 압축하는 것이 중요
• 주로 고정된 압축률 사용 → 사람이 느끼는 화질에 따라 압축률을 조절하면 파일 크기를 줄일 수 있지 않을까?
JPEG 압축 화질 비교(출처: 위키백과)
오른쪽에서 왼쪽으로 갈수록 압축률 증가
JPEG 압축 화질 비교
(출처: https://sirv.com/help/resources/jpeg-quality-comparison/)
23.
Applications
• JPEG compression
•4AFC(four alternative forced choice) QUEST 라는 실험을 수행
• Distorted image와 정상 image 3장, 총 4장의 image를 보여주고 distorted image를 선택하도록 지시
• 압축률을 조절하며 실험자들이 75% 확률 이하로 선택하는 지점(압축률)을 찾음
• 제안하는 방법으로 찾은 압축률과 위의 실험에서 찾은 압축률 비교 실험 수행
• 제안 하는 방법의 output인 visibility map의 최대 값이 0.5를 넘어서는 지점(압축률)을 찾음
• 기존 고정 압축률 사용 대비 60% 정도 file size를 줄일 수 있음( + 약간의 화질 저하)
JPEG 압축률 유사도 실험
24.
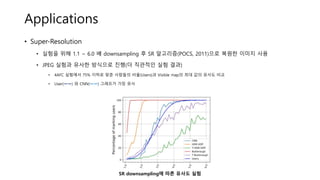
Applications
• Super-Resolution
• 실험을위해 1.1 ~ 6.0 배 downsampling 후 SR 알고리즘(POCS, 2011)으로 복원한 이미지 사용
• JPEG 실험과 유사한 방식으로 진행(더 직관적인 실험 결과)
• 4AFC 실험에서 75% 이하로 맞춘 사람들의 비율(Users)과 Visible map의 최대 값의 유사도 비교
• User(ㅡㅡ) 와 CNN(ㅡㅡ) 그래프가 가장 유사
SR downsampling에 따른 유사도 실험
25.
Applications
• Content-adaptive watermarking
•이미지에 티 안 나게 watermark를 삽입 → 어느 위치가 티가 안 날까?
• Watermark patch(64x64)를 이미지에 삽입 (진한 patch 부터 연하게 줄이면서 실험)
• CNN metric의 output(visibility map)의 pixel maximum 값이 0.06 이하가 되는 시점의 watermark intensity를 사용
• 학습되지 않은 유형의 watermark에 대해서도 그럭저럭 잘 될 수 있음을 보여줌.
Watermarking 예시
26.
Limitations & Conclusion
•Limitations
• 작은 image에 대해서는 예측 성능이 좋지 않음
• 실험 데이터 취득 과정에서 몇몇 제약이 있음(조명, 사람과 화면 사이의 거리)
• 더 많은 실험을 통해 데이터를 축적하면 성능이 좋아질 것으로 기대
• Conclusion
• Visibility metric을 위한 public dataset 구축, CNN 모델 제안
• 아직 가야할 길이 멀지만, 기존 baseline 대비 괜찮은 성능 제시
• Image Processing 분야에서 quality metric뿐만 아니라 visibility metric도 적용하면 좋을 것으로 보임
• ex) Real-time image SR을 위해 CNN 복잡도, bit precision 조절 등을 해야 할 때, 얼만큼 줄일 수 있을지에 대한 지표 제공


































![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[컴퓨터비전과 인공지능] 5. 신경망](https://cdn.slidesharecdn.com/ss_thumbnails/lec5neuralnetwork-210125014802-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Paper Review] Visualizing and understanding convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/visualizingandunderstandingconvolutionalnetworks-171116075511-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Dissertation] Zero-Shot Demographic Inference on Edge Devices from Unstructu...](https://cdn.slidesharecdn.com/ss_thumbnails/finaldefenseformasterdongminkim-250321015431-38a8f713-thumbnail.jpg?width=640&height=640&fit=bounds)


















